
保费因子表计算
day08_保险项目课程笔记
今日内容:
- 完成保费因子表计算操作
1. 计算保费相关指标
1.1 计算保费参数因子
- 需求一: 根据性别, 投保年龄, 缴费期 以及保单年度来统计其中23个保费参数因子指标
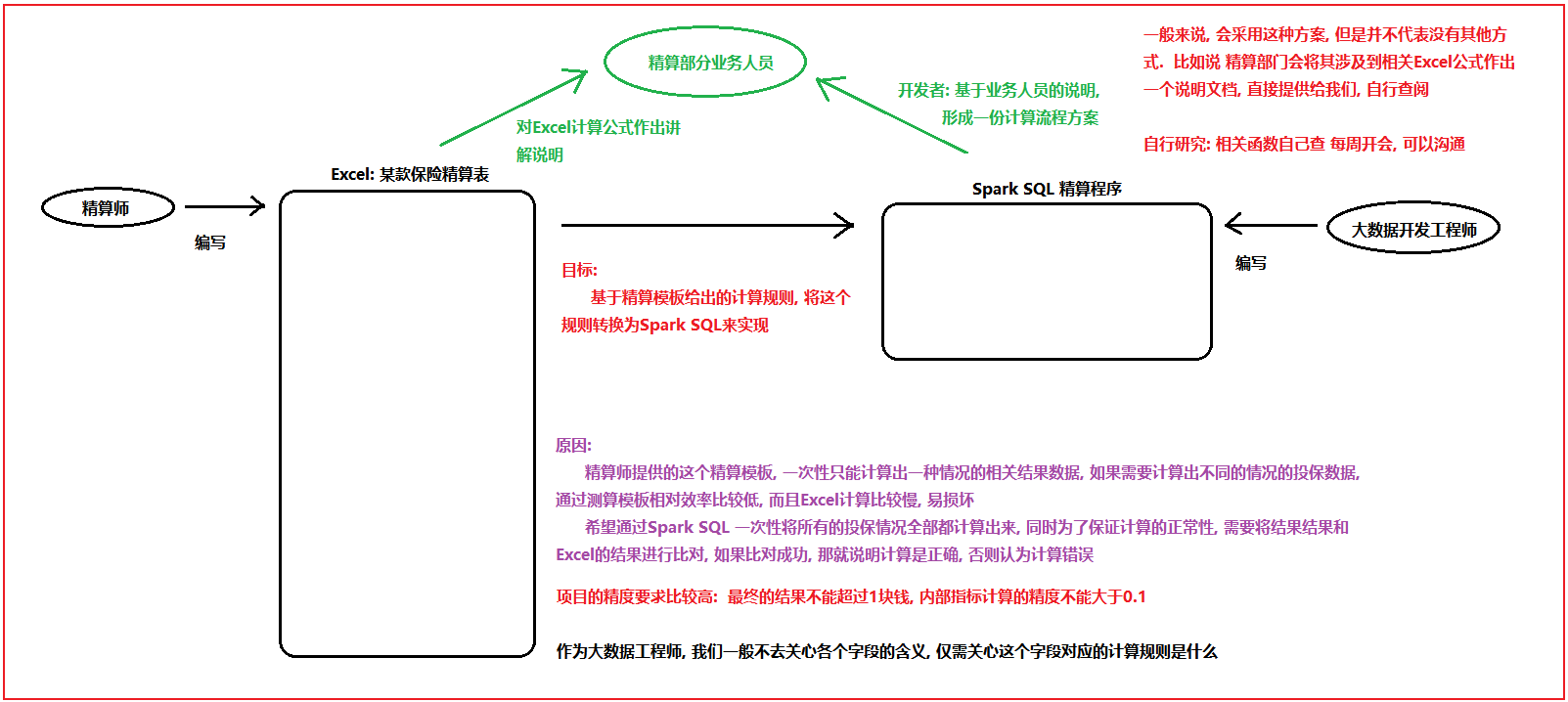
需求分析:
1- 整个保费参数因子表共计有 33个字段, 其中10个维度字段 + 23个指标字段
2- 分析维度数据如何处理?
其中 投保年龄 缴费期 性别 以及保单年度 为联合主键 通知这四个字段就可以确定唯一的一条数据: 一共有 19338种
其他的维度, 要不就是固定的值, 要不就可以使用其他的字段计算出来
只需要关注: 投保年龄 缴费期 性别 保单年度
投保年龄: 18~60
缴费期: 10 15 20 30
性别: 男 女
保单年度: 1 ~ 88
投保的第一年, 就是第一个保单年度, 第二年就是第二个保单年度, 以此类推,直到计算到106岁
比如说:
以18岁投递, 保障终生(106), 保单年度 106 - 18 = 88 年 有88条信息数据
3- 分析指标如何计算: 整体是基于横向迭代计算操作
对于指标杰斯安来说, 需要解析每个指标的计算规则
以其中一个指标为例, 讲解其整个解析流程: 死亡率
计算公式: =IF(J14<=105,VLOOKUP(J14,MORT_10_13,IF(Sex="M",2,3)),0)*MortRatio_Prem_0*(I14<=BPP)
分析:
A * MortRatio_Prem_0 * C
|
|
MortRatio_Prem_0 = if(SEX = 'M',1,1) == 1
A * 1 * C
|
|
解析C: (I14<=BPP) 保单年度一定是小于等于保险期间 == 1
A * 1 * 1
|
|
解析A: IF(J14<=105,VLOOKUP(J14,MORT_10_13,IF(Sex="M",2,3)),0)
当用户年龄 小于等于 105的时候:
执行: VLOOKUP(J14,MORT_10_13,IF(Sex="M",2,3))
根据用户年龄和生命表进行匹配, 匹配后, 如果是男性就返回生命表中第二列数据, 否则返回第三列数据
否则: 返回 0
当前我们是带着大家分析了其中一个指标的计算流程方案, 实际生产中, 剩下的22个指标, 我们都需要大家一个个进行分析, 找到那些指标先计算, 那些指标后计算,那些指标可以一起计算, 每个指标的计算规则是什么, 最终形成一个计算流程表
对于当前学习环境, 不需要大家直接对接Excel进行分析了, 因为这个工作实在太费时间了, 而且技术含量相对不高, 本次直接将所有的指标计算流程, 全部直接提供给大家, 我们可以直接根据计算流程图完成统计计算操作即可, 但是建议大家在计算过程中, 可以根据计算流程图, 对Excel进行反推操作, 理解Excel中相关的计算规则| 保险名词 | 描述解释 | 字段名 |
|---|---|---|
| 缴费期 | 客户要交多少年保费 | ppp |
| 保险费 | 客户每年交多少钱的保费 | prem |
| 投保年龄(购买年龄) | 购买保险时的年龄。最低购买年龄18岁。70岁以后不能购买,70岁后也不能缴费。比如缴费期10年,那么最大购买年龄是60岁。不能在61岁时购买,否则导致71岁还在缴费。所以缴费期与投保年龄的关系如下图: 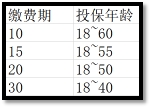 | age_buy |
| 保单年度 | 自投保之日起,第1年是第1个保单年度,第2年是第二保单年度.。。以此类推。 | policy_year |
| 满期年龄 | 一直保障至多少岁。如果是终身则是106岁。 | t_age |
| 保险期间 | 自投保之日起,至满期年龄,之间的年数。比如18岁投保,满期年龄106岁,保障至106岁,保险期间=106-18=88年。 | bpp |
1.2 建库建表操作
- 1- 在项目的sparksql_script目录下创建一个SQL脚本, 用于放置DW层建库建表语句
- 文件名为: _02_insurance_create_dw.sql
- 2- 编写SQL构建库和表
-- 此脚本用于放置构建DW层相关的库和表
-- 建库语句
drop database if exists insurance_dw;
create database if not exists insurance_dw
location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db';
-- 创建表: 保费参数因子表
drop table if exists insurance_dw.prem_src;
create table if not exists insurance_dw.prem_src (
age_buy smallint comment '投保年龄',
nursing_age smallint comment '长期护理保险金给付期满年龄',
sex string comment '性别',
t_age smallint comment '满期年龄(Terminate Age)',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
interest_rate decimal(6, 4) comment '预定利息率(Interest Rate PREM&RSV)',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
policy_year smallint comment '保单年度',
age smallint comment '保单年度对应的年龄',
qx decimal(17, 12) comment '死亡率',
kx decimal(17, 12) comment '残疾死亡占死亡的比例',
qx_d decimal(17, 12) comment '扣除残疾的死亡率',
qx_ci decimal(17, 12) comment '残疾率',
dx_d decimal(17, 12) comment '',
dx_ci decimal(17, 12) comment '',
lx decimal(17, 12) comment '有效保单数',
lx_d decimal(17, 12) comment '健康人数',
cx decimal(17, 12) comment '当期发生该事件的概率,如下指的是死亡发生概率',
cx_ decimal(17, 12) comment '对Cx做调整,不精确的话,可以不做',
ci_cx decimal(17, 12) comment '当期发生重疾的概率',
ci_cx_ decimal(17, 12) comment '当期发生重疾的概率,调整',
dx decimal(17, 12) comment '有效保单生存因子',
dx_d_ decimal(17, 12) comment '健康人数生存因子',
ppp_ smallint comment '是否在缴费期间,1-是,0-否',
bpp_ smallint comment '是否在保险期间,1-是,0-否',
expense decimal(17, 12) comment '附加费用率',
db1 decimal(17, 12) comment '残疾给付',
db2_factor decimal(17, 12) comment '长期护理保险金给付因子',
db2 decimal(17, 12) comment '长期护理保险金',
db3 decimal(17, 12) comment '养老关爱金',
db4 decimal(5, 2) comment '身故给付保险金',
db5 decimal(17, 12) comment '豁免保费因子'
) comment '保费因子表(到每个保单年度)'
row format delimited fields terminated by '\t';1.3 准备构建起始维度表
- 1- 在项目的sparksql_script的目录下, 创建一个SQL脚本, 用于放置计算保费和保费参数因子的相关内容
- 文件名称: _04_insurance_dw_prem.sql
- 2- 编写SQL实现:
-- 此脚本用于放置DW层计算保费以及保费参数因子的相关SQL
-- 0 生成维度数据
-- 缴费期: 10 15 20 30
create or replace view insurance_dw.prem_src_0_ppp as
select stack(4,10,15,20,30) as ppp;
-- 性别: M F
create or replace view insurance_dw.prem_src_0_sex as
select stack(2,'M','F') as sex;
-- 投保年龄: 18 ~ 60
create or replace view insurance_dw.prem_src_0_age_buy as
select explode(sequence(18,60)) as age_buy;
-- 保单年度: 终身寿险 保障到106岁, 所以最大的保单年度为 106-18 = 88
create or replace view insurance_dw.prem_src_0_policy_year as
select explode(sequence(1,88)) as policy_year;
-- 构建一个input常量表, 将固定的参数值放置在一个表中, 整个表只有一行多列即可
create or replace view insurance_dw.input as
select
0.035 interest_rate, --预定利息率(Interest Rate PREM&RSV)
0.055 interest_rate_cv,--现金价值预定利息率(Interest Rate CV)
0.0004 acci_qx,--意外身故死亡发生率(Accident_qx)
0.115 rdr,--风险贴现率(Risk Discount Rate)
10000 sa,--基本保险金额(Baisc Sum Assured)
1 average_size,--平均规模(Average Size)
1 MortRatio_Prem_0,--Mort Ratio(PREM)
1 MortRatio_RSV_0,--Mort Ratio(RSV)
1 MortRatio_CV_0,--Mort Ratio(CV)
1 CI_RATIO,--CI Ratio
6 B_time1_B,--生存金给付时间(1)—begain
59 B_time1_T,--生存金给付时间(1)-terminate
0.1 B_ratio_1,--生存金给付比例(1)
60 B_time2_B,--生存金给付时间(2)-begain
106 B_time2_T,--生存金给付时间(2)-terminate
0.1 B_ratio_2,--生存金给付比例(2)
70 MB_TIME,--祝寿金给付时间
0.2 MB_Ration,--祝寿金给付比例
0.7 RB_Per,--可分配盈余分配给客户的比例
0.7 TB_Per,--未分配盈余分配给客户的比例
1 Disability_Ratio,--残疾给付保险金保额倍数
0.1 Nursing_Ratio,--长期护理保险金保额倍数
75 Nursing_Age--长期护理保险金给付期满年龄
;
-- 进行数据汇总合并操作: 形成 19338条数据
-- 由于维度表结果数据, 需要笛卡尔积的情况, 但是呢, 如果不写on条件, 优化器会认为这个SQL可能是一个效率低下的SQL, 导致无法运行
-- 为了解决这个问题, 可以增加on条件, 只不过在on条件中写为 1 = 1 即可
-- 说明: 根据 性别 缴费期 以及投保年龄, 进行匹配 共计有274种不同的情况
create or replace view insurance_dw.prem_src0 as
select
t3.age_buy,
input.Nursing_Age,
t1.sex,
input.B_time2_T as t_age,
t2.ppp,
106 - t3.age_buy as bpp,
input.interest_rate,
input.sa,
t4.policy_year,
t3.age_buy + t4.policy_year - 1 as age
from insurance_dw.prem_src_0_sex t1
join insurance_dw.prem_src_0_ppp t2 on 1 = 1
join insurance_dw.prem_src_0_age_buy t3 on t3.age_buy >= 18 and t3.age_buy <= 70 - t2.ppp
join insurance_dw.prem_src_0_policy_year t4 on t4.policy_year >= 1 and t4.policy_year <= 106 - t3.age_buy
join insurance_dw.input on 1 = 1;1.4 完成计算步骤一

-- 计算步骤一: ppp_ 和 bpp_
create or replace view insurance_dw.prem_src1 as
select
*,
if(
policy_year <= ppp,
1,
0
) as ppp_,
if(
policy_year <= bpp,
1,
0
) as bpp_
from insurance_dw.prem_src0;
-- 校验: 与 Excel进行校验操作, 在校验的时候, 查询某一种情况, 和Excel对应情况下的数据进行对比, 如果比对成功, 说明计算是正确的
-- 在校验的时候, 尽量多次校验, 前中后校验, 从而确保计算结果没有任何的问题
select * from insurance_dw.prem_src1 where age_buy = 23 and ppp = 20 and sex = 'M';1.5 完成计算步骤二

-- 计算步骤二: qx kx 和 qx_ci
-- 为了保证整个计算的精度, 进行强制类型转换, 将小数强制转换为 12位小数
create or replace view insurance_dw.prem_src2 as
select
t1.*,
cast(
if(
t1.age <= 105,
if(
t1.sex = 'M',
t2.cl1,
t2.cl2
),
0
) * input.MortRatio_Prem_0 * t1.bpp_
as decimal(17,12)) as qx,
cast(
if(
t1.age <= 105 ,
if(
t1.sex = 'M',
t3.k_male,
t3.k_female
),
0
) * t1.bpp_
as decimal(17,12)) as kx,
cast(
if(
t1.sex = 'M',
t3.male,
t3.female
) * t1.bpp_
as decimal(17,12)) as qx_ci
from insurance_dw.prem_src1 t1 join insurance_dw.input on 1 = 1
join insurance_ods.mort_10_13 t2 on t1.age = t2.age
join insurance_ods.dd_table t3 on t1.age = t3.age;
-- 校验步骤二:
select * from insurance_dw.prem_src2 where age_buy = 23 and ppp = 20 and sex = 'M';1.6 完成计算步骤三

-- 步骤三: 计算 qx_d
create or replace view insurance_dw.prem_src3 as
select
*,
cast(
if(
age = 105,
qx - qx_ci,
qx * (1 - kx)
) * bpp_
as decimal(17,12)) as qx_d
from insurance_dw.prem_src2;
-- 校验步骤三:
select * from insurance_dw.prem_src3 where age_buy = 23 and ppp = 20 and sex = 'M';1.7 创建Py脚本,读取Sql处理
- 1- 在项目的main目录下, 创建一个python的文件, 用于读取SQL脚本, 执行SQL
- 文件名: insurance_FIAA_main
- 2- 编写代码
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import os
# 锁定远端操作环境, 避免存在多个版本环境的问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
# 功能: 读取外部SQL脚本文件, 识别每一个SQL语句, 去重SQL中空行注释, 然后执行SQL语句 如果SQL以select开头, 打印其返回的结果
def executeSQLFile(filename):
with open(r'../sparksql_script/' + filename, 'r') as f:
# 读取文件中所有行数据, 得到一个列表,列表中每一个元素就是一行行数据
read_data = f.readlines()
# 将数组的一行一行拼接成一个长文本,就是SQL文件的内容
read_data = ''.join(read_data)
# 将文本内容按分号切割得到数组,每个元素预计是一个完整语句
arr = read_data.split(";")
# 对每个SQL,如果是空字符串或空文本,则剔除掉
# 注意,你可能认为空字符串''也算是空白字符,但其实空字符串‘’不是空白字符 ,即''.isspace()返回的是False
arr2 = list(filter(lambda x: not x.isspace() and not x == "", arr))
# 对每个SQL语句进行迭代
for sql in arr2:
# 先打印完整的SQL语句。
print(sql, ";")
# 由于SQL语句不一定有意义,比如全是--注释;,他也以分号结束,但是没有意义不用执行。
# 对每个SQL语句,他由多行组成,sql.splitlines()数组中是每行,挑选出不是空白字符的,也不是空字符串''的,也不是--注释的。
# 即保留有效的语句。
filtered = filter(lambda x: (not x.lstrip().startswith("--")) and (not x.isspace()) and (not x.strip() == ''),
sql.splitlines())
# 下面数组的元素是SQL语句有效的行
filtered = list(filtered)
# 有效的行数>0,才执行
if len(filtered) > 0:
df = spark.sql(sql)
# 如果有效的SQL语句是select开头的,则打印数据。
if filtered[0].lstrip().startswith("select"):
df.show()
# 快捷键: main 回车
if __name__ == '__main__':
print("精算系统执行驱动类程序")
# 1- 创建SparkSession对象
spark = SparkSession.builder.appName("FIAA_MAIN") \
.master("local[*]") \
.config("spark.sql.shuffle.partitions", 4) \
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node1:9083") \
.enableHiveSupport() \
.getOrCreate()
# 2- 读取SQL脚本, 执行SQL语句
executeSQLFile('_04_insurance_dw_prem.sql')1.8 完成计算步骤四

- 先处理当保单年度为1的时候
-- 步骤 4_1 完成当保单年度为1的时候
create or replace view insurance_dw.prem_src4_1 as
select
*,
if(policy_year = 1, 1,NULL) AS lx
from insurance_dw.prem_src3;- 编写自定义UDAF函数, 实现计算LX
@F.pandas_udf(returnType='decimal(17,12)')
def udaf_lx(qx:pd.Series,lx:pd.Series) -> decimal:
tmp_lx = decimal.Decimal(0) # 0 --> 1 --> 0.999432
for i in range(0,len(qx)):
if i == 0:
tmp_lx = decimal.Decimal(lx[i])
else:
# 此处返回的小数位 和 注册中对应函数的返回类型对应的小数位保持一致, 否则会直接报错(报警告)
tmp_lx = (tmp_lx * (1 - qx[i - 1])).quantize(decimal.Decimal('0.000000000000'))
return tmp_lx
spark.udf.register('udaf_lx',udaf_lx)- 编写SQL, 完成调用操作
-- 步骤4_2 完成计算lx操作
drop table if exists insurance_dw.prem_src4_2;
create table if not exists insurance_dw.prem_src4_2 as
select
age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
udaf_lx(qx,lx) over(partition by age_buy,ppp,sex order by policy_year) as lx
from insurance_dw.prem_src4_1;
-- 校验步骤4_2: lx计算结果
select * from insurance_dw.prem_src4_2 where age_buy = 23 and ppp = 20 and sex = 'M';
说明:
由于后续要在SQL脚本中对数据进行测试操作, 以及后续的步骤也要继续编写, 所以将使用自定义函数后, 直接将结果保存到一张表, 这样后续就可以直接测试使用了, 不需要每一次通过PY程序运行了
如果后续想要通过视图的方式来处理, 此处必须构建的是临时视图, 因为自定义函数是临时的, 所以视图也必须是临时的, 因为在永久的里面不能使用临时的东西, 但是在临时的内部可以使用永久的内容1.9 完成计算步骤五

- 首先, 完成当保单年度为1的时候, 计算lx_d的值
-- 步骤 5_1: 当保单年度为1的时候, 计算 lx_d
create or replace view insurance_dw.prem_src5_1 as
select
*,
if(policy_year = 1, 1, null) as lx_d
from insurance_dw.prem_src4_2;- 接着自定义UDAF函数, 完成一次性计算三列的结果, 并封装到一个字符串中
@F.pandas_udf(returnType='string')
def udaf_3col(qx_d:pd.Series,qx_ci:pd.Series,lx_d:pd.Series) -> str:
tmp_lx_d = decimal.Decimal(0) # 1
tmp_dx_d = decimal.Decimal(0) # 0.000455536
tmp_dx_ci = decimal.Decimal(0) # 0.000565
for i in range(0,len(qx_d)):
if i == 0 :
tmp_lx_d = decimal.Decimal(lx_d[i])
tmp_dx_d = decimal.Decimal(qx_d[i])
tmp_dx_ci = decimal.Decimal(qx_ci[i])
else:
# 此处结果计算的当前的lx_d
tmp_lx_d = (tmp_lx_d - tmp_dx_d - tmp_dx_ci).quantize(decimal.Decimal('0.000000000000'))
tmp_dx_d = (tmp_lx_d * qx_d[i]).quantize(decimal.Decimal('0.000000000000'))
tmp_dx_ci = (tmp_lx_d * qx_ci[i]).quantize(decimal.Decimal('0.000000000000'))
return f'{tmp_lx_d},{tmp_dx_d},{tmp_dx_ci}'
spark.udf.register('udaf_3col',udaf_3col)- 最后 编写SQL, 调用函数, 并且实现分隔操作, 完成最终三列计算
-- 步骤 5_2:
drop table if exists insurance_dw.prem_src5_2;
create table if not exists insurance_dw.prem_src5_2 as
select
age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
lx,
udaf_3col(qx_d,qx_ci,lx_d) over(partition by age_buy,ppp,sex order by policy_year) as lx_d_dx_d_dx_ci
from insurance_dw.prem_src5_1;
-- 步骤5_3 将三列数据拆解开
create or replace view insurance_dw.prem_src5_3 as
select
age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
lx,
cast( split(lx_d_dx_d_dx_ci,',')[0] as decimal(17,12)) as lx_d,
cast( split(lx_d_dx_d_dx_ci,',')[1] as decimal(17,12)) as dx_d,
cast( split(lx_d_dx_d_dx_ci,',')[2] as decimal(17,12)) as dx_ci
from insurance_dw.prem_src5_2;
-- 校验步骤五
select * from insurance_dw.prem_src5_3 where age_buy = 23 and ppp = 20 and sex = 'M';1.10 完成计算步骤六

-- 步骤六: cx ^ 幂
-- 如何进行幂次方计算呢? pow(底数,指数)
create or replace view insurance_dw.prem_src6 as
select
*,
cast( dx_d / pow((1+interest_rate),(age+1)) as decimal(17,12)) as cx
from insurance_dw.prem_src5_3;
-- 校验步骤六
select * from insurance_dw.prem_src6 where age_buy = 23 and ppp = 20 and sex = 'M';1.11 完成计算步骤七

-- 步骤七: cx_ 和 ci_cx
create or replace view insurance_dw.prem_src7 as
select
*,
cast( cx * pow((1+interest_rate),0.5) as decimal(17,12)) as cx_,
cast(dx_ci / pow((1+interest_rate),(age+1)) as decimal(17,12)) as ci_cx
from insurance_dw.prem_src6;
-- 校验步骤七
select * from insurance_dw.prem_src7 where age_buy = 23 and ppp = 20 and sex = 'M';1.12 完成计算步骤八

-- 步骤八
create or replace view insurance_dw.prem_src8 as
select
*,
cast(ci_cx * pow((1+interest_rate),0.5) as decimal(17,12)) as ci_cx_,
cast(lx / pow((1+interest_rate),age) as decimal(17,12)) as dx,
cast(lx_d / pow((1+interest_rate),age) as decimal(17,12)) as dx_d_
from insurance_dw.prem_src7;
-- 校验步骤八
select * from insurance_dw.prem_src8 where age_buy = 23 and ppp = 20 and sex = 'M';1.13 完成计算步骤九
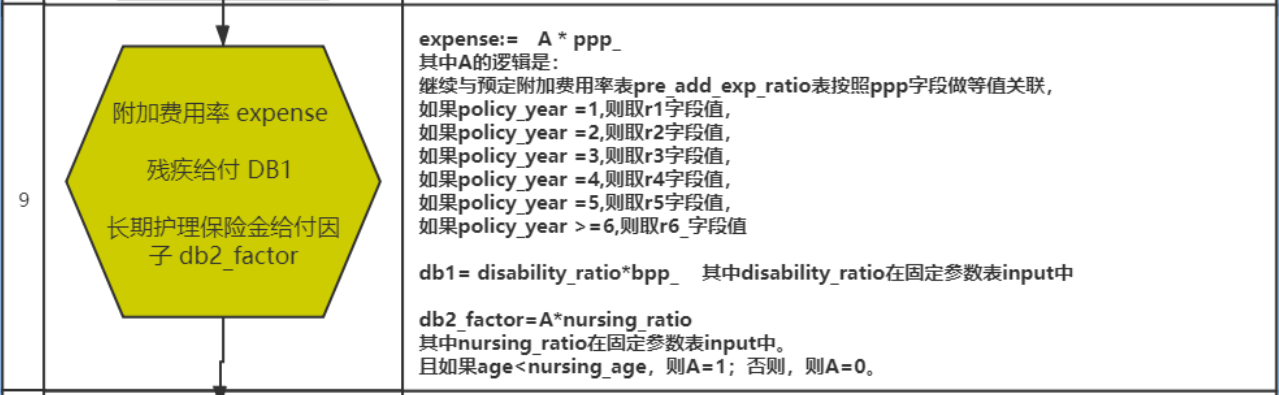
-- 步骤九
create or replace view insurance_dw.prem_src9 as
select
t1.*,
case
when t1.policy_year = 1 then t2.r1
when t1.policy_year = 2 then t2.r2
when t1.policy_year = 3 then t2.r3
when t1.policy_year = 4 then t2.r4
when t1.policy_year = 5 then t2.r5
else t2.r6_
end * t1.ppp_ as expense,
cast(input.Disability_Ratio * t1.bpp_ as decimal(17,12)) as db1,
cast(
if(
t1.age < t1.Nursing_Age,
1,
0
) * input.Nursing_Ratio
as decimal(17,12)) as db2_factor
from insurance_dw.prem_src8 t1
join insurance_ods.pre_add_exp_ratio t2 on t1.ppp = t2.PPP
join insurance_dw.input on 1 = 1;
-- 校验步骤九
select * from insurance_dw.prem_src9 where age_buy = 23 and ppp = 20 and sex = 'M';遇到问题:
在业务端的数据源表于测算模板中相关的配置表信息不一致, 导致基础配置数据出错, 从而影响最终结果的计算
如何解决呢?
一般都是寻求业务方人员以及精算人员沟通, 确定到底是那方的问题, 如果是业务库问题, 由业务人员修改业务库, 调整后, 重新采集数据即可, 一般大数据开发者对业务库仅仅只有只读权限, 无权利直接修改业务库
如果精算人员的问题, 精算重新调整精算模板, 重新验证1.13 完成计算步骤十

-- 计算步骤十
create or replace view insurance_dw.prem_src10 as
select
t1.*,
cast(
sum(t1.dx * t1.db2_factor) over(partition by t1.age_buy,t1.sex,t1.ppp order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
as decimal(17,12)) as db2,
cast(
if(
t1.age >= t1.Nursing_Age,
1,
0
) * input.Nursing_Ratio
as decimal(17,12)) as db3,
least(t1.ppp,t1.policy_year) as db4,
cast(
(
sum(t1.dx * t1.ppp_) over(partition by t1.age_buy,t1.sex,t1.ppp order by t1.policy_year rows between 1 following and unbounded following)
/
t1.dx
) * pow((1+t1.interest_rate),0.5)
as decimal(17,12)) as db5
from insurance_dw.prem_src9 t1 join insurance_dw.input;
-- least(字段1,字段2...) : 表示在多列中 寻找一个最小值返回
-- greatest(字段1,字段2...) : 表示在多列中 寻找一个最大值返回
select least(2,5,4,1);
select greatest(2,5,4,1);
-- 校验步骤十
select * from insurance_dw.prem_src10 where age_buy = 23 and ppp = 20 and sex = 'M';1.14 将保费参数因子表结果导入到目标表
-- 将保费参数因子表的结果导入到目标表
-- select后面的字段顺序一定要和目标表的字段顺序保持一致,否则可能会出现紊乱
insert overwrite table insurance_dw.prem_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
expense,
db1,
db2_factor,
db2,
db3,
db4,
db5
from insurance_dw.prem_src10;
-- 校验目标表
select count(1) from insurance_dw.prem_src;
select * from insurance_dw.prem_src where age_buy = 23 and ppp = 20 and sex = 'M' ;思考: 是否可以有可优化的地方呢?
1- 在4040界面上, 看到分区(线程)的数量比较多的, 最高有200个, 默认spark sql分区数量为 200 , 可以通过添加参数, 调整分区的数量: set spark.sql.shuffle.partitions = 4;
2- 整体保费参数因子计算工作完成后, 中间所有的结果校验工作, 可以全部都删除了
3- 可以将永久视图、表全部切换为临时视图处理, 直到最后保存至表中
4- 对于input表, 可以将其设置为缓存思考: 整个计算难点:
1- 自定义UDAF函数解决业务中复杂的纵向迭代问题
2- 将复杂的精算计算操作, 通过视图化方案, 将其拆解为一个个模块 简化开发难度, 提供程序维护性2. 计算保费
目前这款保险是一个固定保费的保险产品, 就是说用户每一年缴纳的保费是一致的, 所以说计算保费的时候, 其实跟保单年度就没有关系, 只需要根据投递年龄, 性别 以及缴费期, 计算每一种情况下的对应保费数据即可
需求二: 统计各个投保年龄 各个性别 各个缴费期的保费信息 (274条)
2.1 创建保费的结果表
-- 保费表
drop table if exists insurance_dw.prem_std;
create table if not exists insurance_dw.prem_std (
age_buy smallint comment '投保年龄',
sex string comment '性别',
ppp smallint comment '缴费期',
bpp string comment '保障期',
prem decimal(14, 6) comment '每期交的保费'
) comment '标准保费结果表' row format delimited
fields terminated by '\t';注意: 建表的SQL语句需要放置到: _02_insurance_dw_create.sql
2.2 计算步骤十一
-- 步骤十一: 计算中间结果
create or replace view insurance_dw.prem_std11 as
select
age_buy,
sex,
ppp,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * db1 * pow((1+interest_rate),-0.25),
ci_cx_ * db1
)
)
as decimal(17,12)) as T11,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * db2 * pow((1+interest_rate),-0.25),
ci_cx_ * db2
)
)
as decimal(17,12)) as V11,
cast(sum(dx * db3) as decimal(17,12)) as W11,
cast(sum(dx * ppp_) as decimal(17,12)) as Q11,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * pow((1+interest_rate),0.25),
0
)
)
as decimal(17,12)) as T9,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * pow((1+interest_rate),0.25),
0
)
)
as decimal(17,12)) as V9,
cast(sum(dx * expense) as decimal(17,12)) as S11,
cast(sum(cx_ * db4) as decimal(17,12)) as X11,
cast(sum(ci_cx_ * db5) as decimal(17,12)) as Y11
from insurance_dw.prem_src10
group by age_buy,sex,ppp;
-- 校验操作:
select * from insurance_dw.prem_std11 where age_buy = 28 and ppp = 30 and sex = 'F' ;2.3 计算步骤十二
-- 步骤十二:
create or replace view insurance_dw.prem_std12 as
select
t1.age_buy,
t1.sex,
t1.ppp,
cast(
input.sa * (t1.t11 + t1.v11 + t1.W11) / (t1.Q11 - t1.T9 - t1.V9 - t1.S11 - t1.X11 - t1.Y11)
as decimal(17,0)) as prem
from insurance_dw.prem_std11 t1 join insurance_dw.input on 1 = 1;
-- 校验操作:
select * from insurance_dw.prem_std12 where age_buy = 35 and ppp = 15 and sex = 'F' ;2.4 保存至目标表
-- 保存至目标表
insert overwrite table insurance_dw.prem_std
select
age_buy,
sex,
ppp,
(106 - age_buy) as bpp,
prem
from insurance_dw.prem_std12;
-- 校验保费
select count(1) from insurance_dw.prem_std;
select * from insurance_dw.prem_std where age_buy = 35 and ppp = 15 and sex = 'F' ;3. 保险现金价值和准备金
3.1 什么是现金价值
- 1- 指带有储蓄性质的人身保险单所具有的价值
- 2- 保险人为履行合同责任通常提存责任准备金,如果中途退保,即以该保单的责任准备金作为给付解约的退还金。被保险人要求解约或退保时,寿险公司应该发还的金额
- 3- 可以做保单贷款, 一般是可以贷到保单现金价值的70%
3.2 什么是准备金
保险准备金(reserve)是指保险人为保证其如约履行保险赔偿或给付义务,根据政府有关法律规定或业务特定需要,从保费收入或盈余中提取的与其所承担的保险责任相对应的一定数量的基金
寿险准备金意思是计提的保费,用来作为未来赔付的保证。准备金是衡量保险公司偿付能力的重要指标,偿付能力越强,保险公司信用评级越高。
从保险公司的角度来说, 不管是现金价值, 还是保险准备金, 都是准备金, 都是不能动的钱, 都可以认为是保险公司的负债
4. 现金价值计算操作
4.1 需求分析
需求: 统计各个投保年龄, 各个性别, 各个缴费期在每个保单年度对应的现金价值相关指标(总条数为 19338条)
分析:
1- 共计有10个维度字段 和 37个指标字段:
其中 10个维度字段与保费参数因子表的10个维度字段基本一致, 只有一个费率是不同, 后续维度数据可以直接加载保费参数因子表
指标:
发现在现金价值表中相关的字段是来源于保费参数因子表, 所欲对于这类指标 直接对接保费参数因子表即可 不需要再次计算:
不需要计算的指标: 15个
死亡率qx
残疾死亡占死亡的比例kx
扣除残疾的死亡率qx_d
残疾率qx_ci
dx_d
dx_ci
有效保单数lx
健康人数lx_d
缴费期间PPP_
保险期间BPP
附加费用率Expense
残疾给付DB1
"长期护理保险金给付因子db2_factor"
养老关爱金DB3
身故给付保险金DB4
需要计算的指标: 22个
Cx
Cx~
Ci_Cx
Ci_Cx~
有效保单生存因子Dx
健康人数生存因子Dx_D_
长期护理保险金DB2
豁免保费因子DB5
净保费NP_
净保费现值PVNP
PVDB1
PVDB2
PVDB3
PVDB4
PVDB5
保单价值准备金PVR
Rt
修匀净保费(NP)
生存金sur_ben
现金价值年末(生存给付前)cv_1a
现金价值年末(生存给付后)cv_1b
"现金价值年中cv_2"
2- 在现金价值中, 保单年度为0也是有意义的, 所以在生成数据的时候, 需要包含保单年度为0的数据, 共计有274条, 所以最终的全部数据量: 19338 + 274 = 19612条
开发步骤:
1- 在DW层创建现金价值结果表: 共计有 47个字段(10维度 + 37个指标)
2- 对接保费参数因子表, 将不需要计算的维度和指标获取出来
3- 添加保单年度为0的数据到表中, 表总数据量为 19612条
4- 完成后续的计算操作4.2 创建现金价值结果表
-- 现金价值表计算
drop table if exists insurance_dw.cv_src;
create table if not exists insurance_dw.cv_src(
age_buy smallint comment '投保年龄',
nursing_age smallint comment '长期护理保险金给付期满年龄',
sex string comment '性别',
t_age smallint comment '满期年龄(Terminate Age)',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
interest_rate_cv decimal(6, 4) comment '现金价值预定利息率(Interest Rate CV)',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
policy_year smallint comment '保单年度',
age smallint comment '保单年度对应的年龄',
qx decimal(8, 7) comment '死亡率',
kx decimal(8, 7) comment '残疾死亡占死亡的比例',
qx_d decimal(8, 7) comment '扣除残疾的死亡率',
qx_ci decimal(8, 7) comment '残疾率',
dx_d decimal(8, 7) comment '',
dx_ci decimal(8, 7) comment '',
lx decimal(8, 7) comment '有效保单数',
lx_d decimal(8, 7) comment '健康人数',
cx decimal(8, 7) comment '当期发生该事件的概率,如下指的是死亡发生概率',
cx_ decimal(8, 7) comment '对Cx做调整,不精确的话,可以不做',
ci_cx decimal(8, 7) comment '当期发生重疾的概率',
ci_cx_ decimal(8, 7) comment '当期发生重疾的概率,调整',
dx decimal(8, 7) comment '有效保单生存因子',
dx_d_ decimal(8, 7) comment '健康人数生存因子',
ppp_ smallint comment '是否在缴费期间,1-是,0-否',
bpp_ smallint comment '是否在保险期间,1-是,0-否',
expense decimal(8, 7) comment '附加费用率',
db1 decimal(12, 2) comment '残疾给付',
db2_factor decimal(8, 7) comment '长期护理保险金给付因子',
db2 decimal(12, 2) comment '长期护理保险金',
db3 decimal(12, 2) comment '养老关爱金',
db4 decimal(12, 2) comment '身故给付保险金',
db5 decimal(12, 2) comment '豁免保费因子',
np_ DECIMAL(12, 2) comment '净保费',
pvnp DECIMAL(17, 7) comment '净保费现值',
pvdb1 DECIMAL(17, 7) comment '',
pvdb2 DECIMAL(17, 7) comment '',
pvdb3 DECIMAL(17, 7) comment '',
pvdb4 DECIMAL(17, 7) comment '',
pvdb5 DECIMAL(17, 7) comment '',
pvr DECIMAL(17, 7) comment '保单价值准备金',
rt DECIMAL(6, 3) comment '',
np DECIMAL(17, 7) comment '修匀净保费',
sur_ben DECIMAL(17, 7) comment '生存金',
cv_1a DECIMAL(17, 7) comment '现金价值年末(生存给付前)',
cv_1b DECIMAL(17, 7) comment '现金价值年末(生存给付后)',
cv_2 DECIMAL(17, 7) comment '现金价值年中'
)comment '现金价值表(到每个保单年度)'
row format delimited fields terminated by ',';注意: 建表语句需要放置到 _02_insurance_dw_create.sql
4.3 完成计算操作(13~16)
1- 在sparksql_script目录下,创建一个用于记录现金价值的SQL脚本:
- 文件名: _05_insurance_dw_cv.sql
2- 思考如何生成274条保单年度为0的数据:
-- 投机取巧方法
select distinct
t1.age_buy,
t1.nursing_age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
input.interest_rate_cv,
t1.sa,
0 as policy_year,
null as age,
null as qx,
null as kx,
null as qx_d,
null as qx_ci,
null as dx_d,
null as dx_ci,
null as lx,
null as lx_d,
null as ppp_,
null as bpp_,
null as expense,
null as db1,
null as db2_factor,
null as db3,
null as db4
from insurance_dw.prem_src10 t1 join insurance_dw.input on 1 =1;
-- 标准生成方案(实现274条 保单年度为0的数据)
select
t3.age_buy,
input.Nursing_Age,
t1.sex,
input.B_time2_T as t_age,
t2.ppp,
106 - t3.age_buy as bpp,
input.interest_rate_cv,
input.sa,
0 as policy_year,
null as age,
null as qx,
null as kx,
null as qx_d,
null as qx_ci,
null as dx_d,
null as dx_ci,
null as lx,
null as lx_d,
null as ppp_,
null as bpp_,
null as expense,
null as db1,
null as db2_factor,
null as db3,
null as db4
from insurance_dw.prem_src_0_sex t1
join insurance_dw.prem_src_0_ppp t2 on 1 = 1
join insurance_dw.prem_src_0_age_buy t3 on t3.age_buy >= 18 and t3.age_buy <= 70 - t2.ppp
join insurance_dw.input on 1 = 1;- 计算第13步:
-- 此脚本用于放置现金价值相关计算SQL
-- 步骤13~16
create or replace view insurance_dw.cv_src16 as
with cv_src13 as(
select
t1.age_buy,
t1.nursing_age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
input.interest_rate_cv,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
cast(t1.dx_d / pow((1+input.interest_rate_cv),(t1.age + 1)) as decimal(17,12)) as cx ,
t1.ppp_,
t1.bpp_,
t1.expense,
t1.db1,
t1.db2_factor,
t1.db3,
t1.db4
from insurance_dw.prem_src10 t1 join insurance_dw.input on 1 =1
union all
select
t3.age_buy,
input.Nursing_Age,
t1.sex,
input.B_time2_T as t_age,
t2.ppp,
106 - t3.age_buy as bpp,
input.interest_rate_cv,
input.sa,
0 as policy_year,
null as age,
null as qx,
null as kx,
null as qx_d,
null as qx_ci,
null as dx_d,
null as dx_ci,
null as lx,
null as lx_d,
null as cx,
null as ppp_,
null as bpp_,
null as expense,
null as db1,
null as db2_factor,
null as db3,
null as db4
from insurance_dw.prem_src_0_sex t1
join insurance_dw.prem_src_0_ppp t2 on 1 = 1
join insurance_dw.prem_src_0_age_buy t3 on t3.age_buy >= 18 and t3.age_buy <= 70 - t2.ppp
join insurance_dw.input on 1 = 1
),
cv_src14 as (
select
*,
cast( cx * pow((1+interest_rate_cv),0.5) as decimal(17,12)) as cx_,
cast(dx_ci / pow((1+interest_rate_cv),(age+1)) as decimal(17,12)) as ci_cx
from cv_src13
),
cv_src15 as (
select
*,
cast(ci_cx * pow((1+interest_rate_cv),0.5) as decimal(17,12)) as ci_cx_,
cast(lx / pow((1+interest_rate_cv),age) as decimal(17,12)) as dx,
cast(lx_d / pow((1+interest_rate_cv),age) as decimal(17,12)) as dx_d_
from cv_src14
)
select
*,
cast(
sum(dx * db2_factor) over(partition by age_buy,sex,ppp order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as db2,
cast(
(
sum(dx * ppp_) over(partition by age_buy,sex,ppp order by policy_year rows between 1 following and unbounded following)
/
dx
) * pow((1 + interest_rate_cv),0.5)
as decimal(17,12)) as db5
from cv_src15;
-- 校验步骤16
select
*
from insurance_dw.cv_src16 where ppp = 10 and age_buy = 25 and sex ='M' order by policy_year;4.4 完成计算操作(17~18)
-- 步骤17 ~ 18
create or replace view insurance_dw.cv_src18 as
with cv_src17 as (
select
age_buy,
ppp,
sex,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * db1 * pow((1+interest_rate_cv),-0.25),
ci_cx_ * db1
)
)
as decimal(17,12)) as T11,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * db2 * pow((1+interest_rate_cv),-0.25),
ci_cx_ * db2
)
)
as decimal(17,12)) as V11,
cast(sum(dx * db3) as decimal(17,12)) as W11,
cast(sum(dx * ppp_) as decimal(17,12)) as Q11,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * pow((1+interest_rate_cv),0.25),
0
)
)
as decimal(17,12)) as T9,
cast(
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * pow((1+interest_rate_cv),0.25),
0
)
)
as decimal(17,12)) as V9,
cast(sum(dx * expense) as decimal(17,12)) as S11,
cast(sum(cx_ * db4) as decimal(17,12)) as X11,
cast(sum(ci_cx_ * db5) as decimal(17,12)) as Y11
from insurance_dw.cv_src16
group by age_buy,ppp,sex
)
select
t1.age_buy,
t1.sex,
t1.ppp,
cast(
(input.sa * (t1.t11 +t1.v11 +t1.w11) + t2.prem * (t1.T9 + t1.V9 + t1.X11 + t1.Y11))
/
(t1.Q11 - t1.S11)
as decimal(17,12)) as prem_cv
from cv_src17 t1 join insurance_dw.input on 1 = 1
join insurance_dw.prem_std12 t2 on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex
-- 校验步骤18
select
*
from insurance_dw.cv_src18 where ppp = 10 and age_buy = 25 and sex ='M' ;说明: 发现在计算金毛保费的时候, 中间的计算结果, 计算出现一定的偏差, 而且偏差是由精度导致的,但是实际保留了12位小数的精度, 这是为什么呢?
decimal最大长度为38位, 一旦超出了38位的长度后, 默认会自动的进行四舍五入,而整个计算过程中, 大量的中间结果产生, 每个结果极有可能进行四舍五入操作, 从而导致最终的结果出现一定的偏差, 无法保留多个小数位 (相当于出现类似于double 或者 float的精度偏差问题)
解决方案: 添加一个spark的配置, 此配置用于保护精度, 禁止decimal类型进行四舍五入操作
set spark.sql.decimalOperations.allowPrecisionLoss=false; -- 是否允许进行精度损失(默认true)4.5 将金毛保费保存至目标表
- 1- 构建prem_cv结果表
-- 创建 金毛保费目标表
drop table if exists insurance_dw.prem_cv;
create table if not exists insurance_dw.prem_cv (
age_buy smallint comment '年投保龄',
sex string comment '性别',
ppp smallint comment '缴费期间',
prem_cv decimal(15, 7) comment '保单价值准备金毛保险费(Preuim)'
)comment '保单价值准备金毛保险费表' row format delimited
fields terminated by '\t';建表语句放置到_02_insurance_dw_create.sql
- 2- 执行导入操作
-- 将结果直接导入到金毛保费目标表
insert overwrite table insurance_dw.prem_cv
select
age_buy,
sex,
ppp,
prem_cv
from insurance_dw.cv_src18;
-- 校验金毛保费表:
select
*
from insurance_dw.prem_cv where ppp = 10 and age_buy = 25 and sex ='M' ;4.6 完成计算操作(19~23)
-- 计算步骤19~23
create or replace view insurance_dw.cv_src23 as
with cv_src19 as (
select
t1.*,
cast(
(t1.ppp_ - t1.expense) * t2.prem_cv
as decimal(17,12)) as np_,
cast(
t2.prem_cv
*
sum(t1.dx * (t1.ppp_ - t1.expense)) over(partition by t1.age_buy,t1.sex,t1.ppp order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
as decimal(17,12)) as pvnp,
cast(
if(
t1.policy_year = 1,
(
t1.sa
*
ifnull(sum(t1.ci_cx_ * t1.db1) over(partition by t1.age_buy,t1.sex,t1.ppp order by policy_year rows between 1 following and unbounded following) ,0)
+
0.5
*
(
t3.prem * t1.ci_cx_ * pow((1+t1.interest_rate_cv),0.25)
+
t1.sa * t1.db1 * t1.ci_cx_ * pow((1+t1.interest_rate_cv),-0.25)
)
)
/
t1.dx,
t1.sa
*
sum(t1.ci_cx_ * t1.db1) over(partition by t1.ppp,t1.sex,t1.age_buy order by policy_year rows between current row and unbounded following)
/
t1.dx
)
as decimal(17,12)) as pvdb1,
cast(
if(
t1.policy_year = 1,
(
t1.sa
*
ifnull(sum(t1.ci_cx_ * t1.db2) over(partition by t1.age_buy,t1.sex,t1.ppp order by policy_year rows between 1 following and unbounded following) ,0)
+
0.5
*
(
t3.prem * t1.ci_cx_ * pow((1+t1.interest_rate_cv),0.25)
+
t1.sa * t1.db2 * t1.ci_cx_ * pow((1+t1.interest_rate_cv),-0.25)
)
)
/
t1.dx,
t1.sa
*
sum(t1.ci_cx_ * t1.db2) over(partition by t1.ppp,t1.sex,t1.age_buy order by policy_year rows between current row and unbounded following)
/
t1.dx
)
as decimal(17,12)) as pvdb2,
cast(
t1.sa
*
sum(t1.dx * t1.db3) over(partition by t1.age_buy,t1.sex,t1.ppp order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
as decimal(17,12)) as pvdb3,
cast(
t3.prem
*
sum(t1.cx_ * t1.db4) over(partition by t1.age_buy,t1.sex,t1.ppp order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
as decimal(17,12)) as pvdb4,
cast(
t3.prem
*
sum(t1.ci_cx_ * t1.db5) over(partition by t1.age_buy,t1.sex,t1.ppp order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
as decimal(17,12)) as pvdb5
from insurance_dw.cv_src16 t1
join insurance_dw.cv_src18 t2 on t1.age_buy = t2.age_buy and t1.sex = t2.sex and t1.ppp = t2.ppp
join insurance_dw.prem_std12 t3 on t1.age_buy = t3.age_buy and t1.sex = t3.sex and t1.ppp = t3.ppp
),
cv_src20 as (
select
*,
if(
policy_year = 0,
null,
lead(pvdb1 + pvdb2 + pvdb3 + pvdb4 + pvdb5 - pvnp,1,0 ) over(partition by ppp,sex,age_buy order by policy_year)
) as pvr,
if(
ppp = 1, -- 趸(dun)交: 一次性完成后续所有的年的缴费
1,
if(
policy_year >= least(20,ppp),
1,
0.8 +policy_year * 0.8 / least(20,ppp)
)
) as rt
from cv_src19
),
cv_src21 as (
select
*,
cast(np_ * lag(rt,1,0) over(partition by age_buy,sex,ppp order by policy_year) as decimal(17,12)) as np,
cast(db3 * sa as decimal(17,12)) as sur_ben,
cast(
rt * greatest(
(pvr - lead(db3 * sa ,1,0) over(partition by age_buy,sex,ppp order by policy_year))
,
0
)
as decimal(17,12)) as cv_1b
from cv_src20
),
cv_src22 as (
select
*,
cv_1b + lead(sur_ben,1,0) over(partition by ppp,age_buy,sex order by policy_year) AS cv_1a
from cv_src21
)
select
*,
cast(
(
np
+
lag(cv_1b,1,0) over(partition by ppp,age_buy,sex order by policy_year)
+
cv_1a
) / 2
as decimal(17,12)) as cv_2
from cv_src22;
-- 校验步骤23:
select
*
from insurance_dw.cv_src23 where ppp = 30 and age_buy = 40 and sex ='M' ;4.7 将现金价值结果导入目标表
-- 将现金价值的结果数据灌入到目标表
insert overwrite table insurance_dw.cv_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate_cv,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
expense,
db1,
db2_factor,
db2,
db3,
db4,
db5,
np_,
pvnp,
pvdb1,
pvdb2,
pvdb3,
pvdb4,
pvdb5,
pvr,
rt,
np,
sur_ben,
cv_1a,
cv_1b,
cv_2
from insurance_dw.cv_src23;
-- 校验现金价值表
-- 19338 + 274 = 19612 条
select count(1) from insurance_dw.cv_src;
select
*
from insurance_dw.cv_src where ppp = 30 and age_buy = 40 and sex ='M';思考: 有那些可以优化点/难点呢?
1- decimal类型 出现精度问题
2- 相关的重复使用表,可以尝试配置缓存操作
3- 将视图切换为临时视图面试中讲法:
讲法1: 基于保费参数因子表的基础上完成现金价值的计算工作 (建议项目负责的点应该包含有保费计算和现金价值计算)
讲法2: 负责现金价值表相关指标精算计算, 其中37个指标都是独立完成的(不依赖与保费参数因子表) 适合于仅负责现金价值计算,不负责保费计算5. 准备金计算操作
5.1 需求分析
需求四: 统计各个投保年龄 各个性别 各个缴费期在不同的保单年度的相关的准备金指标计算 (总条数: 19338)
分析:
1- 准备金表的涉及到指标和维度: 10个维度 +33个指标
其中10个维度, 不需要处理的,可以对接保费参数因子表获取即可
33个指标:
直接从保费参数因子表获取的指标: 17个
死亡率qx
残疾死亡占死亡的比例kx
扣除残疾的死亡率qx_d
残疾率qx_ci
dx_d
dx_ci
有效保单数lx
健康人数lx_d
Cx
Cx~
Ci_Cx
Ci_Cx~
有效保单生存因子Dx
健康人数生存因子Dx_D
缴费期间PPP
保险期间BPP
长期护理保险金给付因子db2_factor
需要计算: 16
DB1,DB2,DB3,DB4,DB5
修正纯保费 np_
修正纯保费现值PVNP
PVDB1
PVDB2
PVDB3
PVDB4
PVDB5
准备金年末rsv1
准备金年初(未加当年初纯保费)rsv2
修正责任准备金年末 rsv1_re
修正责任准备金年初(未加当年初纯保费)rsv2_re
2- 额外添加了三个中间结果的字段,便于后续的指标统计:alpha beta prem_rsv
开发步骤:
1- 创建准备金结果表
2- 对接保费参数因子表,将不需要计算的维度和指标获取出来
3- 完成剩余的计算操作5.2 构建目标表
-- 准备金表
drop table if exists insurance_dw.rsv_src;
create table if not exists insurance_dw.rsv_src (
age_buy smallint comment '投保年龄',
nursing_age smallint comment '长期护理保险金给付期满年龄',
sex string comment '性别',
t_age smallint comment '满期年龄(Terminate Age)',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
interest_rate decimal(6, 4) comment '预定利息率(Interest Rate PREM&RSV)',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
policy_year smallint comment '保单年度',
age smallint comment '保单年度对应的年龄',
qx decimal(8,7) comment '死亡率',
kx decimal(8,7) comment '残疾死亡占死亡的比例',
qx_d decimal(8,7) comment '扣除残疾的死亡率',
qx_ci decimal(8,7) comment '残疾率',
dx_d decimal(8,7) comment '',
dx_ci decimal(8,7) comment '',
lx decimal(8,7) comment '有效保单数',
lx_d decimal(8,7) comment '健康人数',
cx decimal(8,7) comment '当期发生该事件的概率,如下指的是死亡发生概率',
cx_ decimal(8,7) comment '对Cx做调整,不精确的话,可以不做',
ci_cx decimal(8,7) comment '当期发生重疾的概率',
ci_cx_ decimal(8,7) comment '当期发生重疾的概率,调整',
dx decimal(8,7) comment '有效保单生存因子',
dx_d_ decimal(8,7) comment '健康人数生存因子',
ppp_ smallint comment '是否在缴费期间,1-是,0-否',
bpp_ smallint comment '是否在保险期间,1-是,0-否',
db1 decimal(12, 2) comment '残疾给付',
db2_factor decimal(8, 7) comment '长期护理保险金给付因子',
db2 decimal(12, 2) comment '长期护理保险金',
db3 decimal(12, 2) comment '养老关爱金',
db4 decimal(12, 2) comment '身故给付保险金',
db5 decimal(12, 2) comment '豁免保费因子',
np_ decimal(12, 2) comment '修正纯保费',
pvnp decimal(17, 7) comment '修正纯保费现值',
pvdb1 decimal(17, 7) comment '',
pvdb2 decimal(17, 7) comment '',
pvdb3 decimal(17, 7) comment '',
pvdb4 decimal(17, 7) comment '',
pvdb5 decimal(17, 7) comment '',
prem_rsv decimal(17, 7) comment '保险费(Preuim)',
alpha decimal(17, 7) comment '修正纯保费首年',
beta decimal(17, 7) comment '修正纯保费续年',
rsv1 decimal(17, 7) comment '准备金年末',
rsv2 decimal(17, 7) comment '准备金年初(未加当年初纯保费)',
rsv1_re decimal(17, 7) comment '修正责任准备金年末',
rsv2_re decimal(17, 7) comment '修正责任准备金年初(未加当年初纯保费)'
)comment '准备金表(到每个保单年度)' row format delimited
fields terminated by ',';放置到_02_insurance_dw_create.sql
5.3 完成保险准备金计算
1- 在项目中创建一个新的SQL脚本, 用于放置保险准备金的计算流程: _06_insurance_dw_rsv.sql
2- 编写SQL 完成统计计算操作
-- 完成计算保险准备金
set spark.sql.shuffle.partitions = 4;
set spark.sql.decimalOperations.allowPrecisionLoss=false;
-- 首先对接保费参数因子表, 将不需要的维度和指标获取出来
-- 步骤24
with rsv_src24 as (
select
t1.age_buy,
t1.Nursing_Age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t1.interest_rate,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
t1.cx,
t1.cx_,
t1.ci_cx,
t1.ci_cx_,
t1.dx,
t1.dx_d_,
t1.ppp_,
t1.bpp_,
t1.db2_factor,
cast(
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db1 * pow((1+t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db1
)
as decimal(17,12))as db1,
cast(
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db2 * pow((1+t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db2
)
as decimal(17,12))as db2,
cast(t1.sa * t1.db3 as decimal(17,12)) as db3,
cast(t2.prem * t1.db4 as decimal(17,12)) as db4,
cast(t2.prem * t1.db5 as decimal(17,12)) as db5,
t2.prem
from insurance_dw.prem_src10 t1
join insurance_dw.prem_std12 t2 on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
),
rsv_src25 as (
select
*,
cast(
sum(ci_cx_ * db1) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb1,
cast(
sum(ci_cx_ * db2) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb2,
cast(
sum(dx * db3) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb3,
cast(
sum(cx_ * db4) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb4,
cast(
sum(ci_cx_ * db5) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb5
from rsv_src24
),
rsv_src26 as (
select
ppp,
sex,
age_buy,
cast(
sum(
if(
policy_year = 1,
pvdb1 + pvdb2 +pvdb3 + pvdb4 +pvdb5,
0
)
)
/
sum(dx * ppp_)
*
sum(
if(policy_year = 1, dx,0)
)
as decimal(17,12)) as prem_rsv
from rsv_src25
group by ppp,sex,age_buy
),
rsv_src27 as (
select
t1.ppp,
t1.sex,
t1.age_buy,
t1.prem_rsv,
cast(
if(
t1.ppp = 1,
t1.prem_rsv,
sum(
if(
policy_year = 1,
((db1 + db2 + db5) * ci_cx_ + db3 * dx + cx_ * db4) / dx,
0
)
)
)
as decimal(17,12)) as alpha
from rsv_src26 t1 join rsv_src25 t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex
group by t1.ppp,t1.sex,t1.age_buy,t1.prem_rsv
),
rsv_src28 as (
select
t1.age_buy,
t1.sex,
t1.ppp,
t1.prem_rsv,
t1.alpha,
cast(
if(
t1.ppp =1,
0,
t1.prem_rsv
+
cast(
(t1.prem_rsv - t1.alpha)
/
sum(
if(
t2.policy_year >=2,
t2.dx * t2.ppp_,
0
)
)
as decimal(17,12))
*
sum(
if(t2.policy_year = 1 , t2.dx , 0)
)
)
as decimal(17,12)) as beta
from rsv_src27 t1 join rsv_src25 t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex
group by t1.age_buy,t1.sex,t1.ppp,t1.prem_rsv, t1.alpha
),
rsv_src29 as (
select
t1.*,
t2.alpha,
t2.prem_rsv,
t2.beta,
cast(
if(
t1.policy_year = 1,
t2.alpha,
least(t1.prem,t2.beta)
) * t1.ppp_
as decimal(17,12)) as np_
from rsv_src25 t1 join rsv_src28 t2
on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
),
rsv_src30 as (
select
*,
cast(
sum(dx * np_) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvnp
from rsv_src29
),
rsv_src31 as (
select
*,
lead(pvdb1 + pvdb2 + pvdb3 + pvdb4 +pvdb5 - pvnp,1,0) over(partition by ppp,sex,age_buy order by policy_year) as rsv1
from rsv_src30
),
rsv_src32 as (
select
*,
lag(rsv1,1,0) over(partition by ppp,sex,age_buy order by policy_year)
-
db3 as rsv2
from rsv_src31
),
rsv_src33 as (
select
t1.*,
greatest(t1.rsv1,t2.cv_1a) as rsv1_re,
greatest(t1.rsv2, lag(t2.cv_1b,1,0) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year) ) as rsv2_re
from rsv_src32 t1 join insurance_dw.cv_src23 t2
on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.policy_year = t2.policy_year and t1.age_buy = t2.age_buy
)
insert overwrite table insurance_dw.rsv_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
db1,
db2_factor,
db2,
db3,
db4,
db5,
np_,
pvnp,
pvdb1,
pvdb2,
pvdb3,
pvdb4,
pvdb5,
prem_rsv,
alpha,
beta,
rsv1,
rsv2,
rsv1_re,
rsv2_re
from rsv_src33;
-- 校验保险准备金
select count(1) from insurance_dw.rsv_src;
select
*
from insurance_dw.rsv_src where age_buy = 25 and sex='F' and ppp = 30;发现一个问题, 计算后, 返回NULL, 但是将精度保护关闭后, 我们发现, 值回来, 不是NULL
思考什么原因?
发生在decimal这个类型上, decimal最大长度为38位. 当计算超过38位后, 默认decimal会自动进行四舍五入的操作
但是,如果我们开启精度丢失保护后, 意味着不允许decimal类型自动进行四舍五入操作,一旦超过38位长度, 又不让精度损失, 那么decimal只能返回Null
思考: 那到底怎么计算的, 还超过这么大的长度呢? 你觉得 加 减 乘 除 那个操作会影响长度问题比较大呢? 除法
出现这个问题的最根本原因: 整个计算中出现多次乘除计算而导致的
如何解决呢?
1- 关闭精度处理 (不合适)
2- 针对内部计算的操作, 对执行除法的上下计算内容, 单独再次通过cast 进行小数位缩减5.4 使用另一种方式实现
-- 完成计算保险准备金
set spark.sql.shuffle.partitions = 4;
set spark.sql.decimalOperations.allowPrecisionLoss=false;
-- 首先对接保费参数因子表, 将不需要的维度和指标获取出来
-- 步骤24
with rsv_src24 as (
select
t1.age_buy,
t1.Nursing_Age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t1.interest_rate,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
t1.cx,
t1.cx_,
t1.ci_cx,
t1.ci_cx_,
t1.dx,
t1.dx_d_,
t1.ppp_,
t1.bpp_,
t1.db2_factor,
cast(
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db1 * pow((1+t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db1
)
as decimal(17,12))as db1,
cast(
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db2 * pow((1+t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db2
)
as decimal(17,12))as db2,
cast(t1.sa * t1.db3 as decimal(17,12)) as db3,
cast(t2.prem * t1.db4 as decimal(17,12)) as db4,
cast(t2.prem * t1.db5 as decimal(17,12)) as db5,
t2.prem
from insurance_dw.prem_src10 t1
join insurance_dw.prem_std12 t2 on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
),
rsv_src25 as (
select
*,
cast(
sum(ci_cx_ * db1) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb1,
cast(
sum(ci_cx_ * db2) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb2,
cast(
sum(dx * db3) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb3,
cast(
sum(cx_ * db4) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb4,
cast(
sum(ci_cx_ * db5) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvdb5
from rsv_src24
),
rsv_src26 as (
select
ppp,
sex,
age_buy,
cast(
sum(
if(
policy_year = 1,
pvdb1 + pvdb2 +pvdb3 + pvdb4 +pvdb5,
0
)
)
/
sum(dx * ppp_)
*
sum(
if(policy_year = 1, dx,0)
)
as decimal(17,12)) as prem_rsv
from rsv_src25
group by ppp,sex,age_buy
),
rsv_src27 as (
select
t1.ppp,
t1.sex,
t1.age_buy,
t1.prem_rsv,
cast(
if(
t1.ppp = 1,
t1.prem_rsv,
sum(
if(
policy_year = 1,
((db1 + db2 + db5) * ci_cx_ + db3 * dx + cx_ * db4) / dx,
0
)
)
)
as decimal(17,12)) as alpha
from rsv_src26 t1 join rsv_src25 t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex
group by t1.ppp,t1.sex,t1.age_buy,t1.prem_rsv
),
rsv_src28 as (
select
t1.age_buy,
t1.sex,
t1.ppp,
t1.prem_rsv,
t1.alpha,
cast(
if(
t1.ppp =1,
0,
t1.prem_rsv
+
cast(
(t1.prem_rsv - t1.alpha)
/
sum(
if(
t2.policy_year >=2,
t2.dx * t2.ppp_,
0
)
)
as decimal(17,12))
*
sum(
if(t2.policy_year = 1 , t2.dx , 0)
)
)
as decimal(17,12)) as beta
from rsv_src27 t1 join rsv_src25 t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex
group by t1.age_buy,t1.sex,t1.ppp,t1.prem_rsv, t1.alpha
),
rsv_src29 as (
select
t1.*,
t2.alpha,
t2.prem_rsv,
t2.beta,
cast(
if(
t1.policy_year = 1,
t2.alpha,
least(t1.prem,t2.beta)
) * t1.ppp_
as decimal(17,12)) as np_
from rsv_src25 t1 join rsv_src28 t2
on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
),
rsv_src30 as (
select
*,
cast(
sum(dx * np_) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx
as decimal(17,12)) as pvnp
from rsv_src29
),
rsv_src31 as (
select
*,
lead(pvdb1 + pvdb2 + pvdb3 + pvdb4 +pvdb5 - pvnp,1,0) over(partition by ppp,sex,age_buy order by policy_year) as rsv1
from rsv_src30
),
rsv_src32 as (
select
*,
lag(rsv1,1,0) over(partition by ppp,sex,age_buy order by policy_year)
-
db3 as rsv2
from rsv_src31
),
rsv_src33 as (
select
t1.*,
greatest(t1.rsv1,t2.cv_1a) as rsv1_re,
greatest(t1.rsv2, lag(t2.cv_1b,1,0) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year) ) as rsv2_re
from rsv_src32 t1 join insurance_dw.cv_src23 t2
on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.policy_year = t2.policy_year and t1.age_buy = t2.age_buy
)
insert overwrite table insurance_dw.rsv_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
db1,
db2_factor,
db2,
db3,
db4,
db5,
np_,
pvnp,
pvdb1,
pvdb2,
pvdb3,
pvdb4,
pvdb5,
prem_rsv,
alpha,
beta,
rsv1,
rsv2,
rsv1_re,
rsv2_re
from rsv_src33;
-- 校验保险准备金
select count(1) from insurance_dw.rsv_src;
select
*
from insurance_dw.rsv_src where age_buy = 25 and sex='F' and ppp = 30;相关的优化点:
通过窗口函数的方式, 替换掉原有的group by的方式, 从而让整个效率提升了 30%
思考: 是不是就是group by的效果没有窗口函数效率高呢? 并不是的
当下的主要原因:
场景: 计算中间结果的时候,需要用到之前的聚合前的结果数据, 同时聚合后,后续的指标也需要使用聚合前和聚合后的数据
如果此种操作使用group by 会频繁的进行join操作, 会和聚合前的数据不断的进行关联操作, 同时在计算聚合后的相关指标的时候, 也需要和聚合前的数据进行关联 当计算的时候,会导致频繁进行join处理操作以及group by操作,而使用窗口, 不需要执行group by,也不需要进行 join, 可以直接对接一个表, 基于横向迭代计算操作,不断处理, 这样可以减少Join的次数,减少了group by 从而减少了shuffle,达到了提升Spark的shuffle的运行效率6. APP层计算操作
6.1 保险精算表生成
此表是银保监会需要的数据表, 在进行精算计算的时候, 需要将此表结果计算出来, 最终将其提交给银保监会
结果表字段的说明: policy_actuary表
实操:
- 1- 在sparksql_script 中创建一个SQL脚本, 专门用于放置app层建表语句
- 文件名: _03_insurance_create_app.sql
- 2- 在APP层构建目标表:
-- 构建精算系统结果表
drop table if exists insurance_app.policy_actuary;
create table if not exists insurance_app.policy_actuary (
age_buy smallint comment '投保年龄',
sex string comment '性别',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
policy_year smallint comment '保单年度',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
cv_1a decimal(17, 7) comment '现金价值年末(生存给付前)',
cv_1b decimal(17, 7) comment '现金价值年末(生存给付后)',
sur_ben decimal(17, 7) comment '生存金',
np decimal(17, 7) comment '修匀净保费',
rsv2_re decimal(17, 7) comment '修正责任准备金年初(未加当年初纯保费)',
rsv1_re decimal(17) comment '修正责任准备金年末',
np_ decimal(12) comment '修正纯保费'
) comment '产品精算数据表'
row format delimited fields terminated by '\t';- 3- 编写SQL 完成需求(后续会有其他的操作, 这里的SQL仅仅为了演示需求实现, 并没有执行)
insert overwrite table insurance_app.policy_actuary
select
cv.age_buy,
cv.sex,
cv.ppp,
cv.bpp,
cv.policy_year,
cv.sa,
cv.cv_1a,
cv.cv_1b,
cv.sur_ben,
cv.np,
rsv.rsv2_re,
rsv.rsv1_re,
rsv.np_
from insurance_dw.cv_src cv join insurance_dw.rsv_src rsv
on cv.age_buy = rsv.age_buy and cv.sex = rsv.sex and cv.ppp = rsv.ppp and cv.policy_year = rsv.policy_year; 希望当精算系统的33个步骤全部计算完成后, 直接抽取出结果表数据, 灌入APP层对应的精算结果表, 同时还需要将这个结果表导出到MySQL数据库, 以便于后续应用方来对数据进行应用(比如: 报送银保监会 BI看板 深度挖掘计算 用户画像....)
如何做呢?
方式一: Apache SQOOP 完成数据导出操作 (暂时不用)
方式二: 通过 Spark SQL来对接MYSQL代码实现:
# 3- 生成精算结果表数据, 并将结果表数据导入到HIVE 和 MySQL
df_actuary = spark.sql("""
select
cv.age_buy,
cv.sex,
cv.ppp,
cv.bpp,
cv.policy_year,
cv.sa,
cv.cv_1a,
cv.cv_1b,
cv.sur_ben,
cv.np,
rsv.rsv2_re,
rsv.rsv1_re,
rsv.np_
from insurance_dw.cv_src cv join insurance_dw.rsv_src rsv
on cv.age_buy = rsv.age_buy and cv.sex = rsv.sex and cv.ppp = rsv.ppp and cv.policy_year = rsv.policy_year;
""")
# 优化操作, 设置缓存
df_actuary.cache().count()
# 3.1 灌入到HIVE中:
df_actuary.write.saveAsTable('insurance_app.policy_actuary', mode='overwrite')
# 3.2 灌入到MySQL
# create database if not exists insurance_olap charset utf8;
df_actuary.write.jdbc(
url='jdbc:mysql://node1:3306/insurance_olap?useUnicode=true&characterEncoding=utf8',
table='policy_actuary',
mode='overwrite',
properties={'user': 'root', 'password': '123456'}
)
# 4. 关闭会话
spark.stop()6.2 计算某个月份各个客户应交保费
需求:
1、 请结合客户投保详情表,计算当月客户的精算现金价值、准备金信息和现在的应交保费。
2、 每月统计一次
3、 结果按月分区
目标表的字段说明: policy_result表
实操:
- 1-构建目标表:
- 建表语句需要放置在 _03_insurance_app_create.sql
-- 客户保单精算结果表
drop table if exists insurance_app.policy_result;
create table if not exists insurance_app.policy_result (
pol_no STRING COMMENT '保单号',
user_id string comment '客户id',
name string comment '姓名',
sex string comment '性别',
birthday string comment '出生日期',
ppp string comment '缴费期',
age_buy bigint comment '投保年龄',
buy_datetime string comment '投保日期',
insur_name STRING COMMENT '保险名称',
insur_code STRING COMMENT '保险代码',
province string comment '所在省份',
city string comment '所在城市',
direction String comment '所在区域',
bpp smallint comment '保险期间,保障期',
policy_year smallint comment '保单年度',
sa decimal(12, 2) comment '保单年度基本保额',
cv_1a decimal(17, 7) comment '现金价值给付前',
cv_1b decimal(17, 7) comment '现金价值给付后',
sur_ben decimal(17, 7) comment '生存给付金',
np decimal(17, 7) comment '纯保费(CV.NP)',
rsv2_re decimal(17, 7) comment '年初责任准备金',
rsv1_re decimal(17, 7) comment '年末责任准备金',
np_ decimal(12, 2) comment '纯保费(RSV.np_) ',
prem_std decimal(14, 6) comment '每期交保费',
prem_thismonth decimal(14, 6) comment '本月应交保费'
) comment '客户保单精算结果表'
partitioned by (month string)
row format delimited fields terminated by '\t';- SQL实现:
首先 先创建一个app层的SQL脚本文件 : _07_insurance_app.sql
编写SQL: (未完待续)
-- 开启非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 计算某个月份各个客户应交保费 例如: 计算 2022-10月份
insert overwrite table insurance_app.policy_result partition (month)
select
t1.pol_no,
t1.user_id,
t2.name,
t2.sex,
t2.birthday,
t1.ppp,
t1.age_buy,
t1.buy_datetime,
t1.insur_name,
t1.insur_code,
t2.province,
t2.city,
t2.direction,
t3.bpp,
t3.policy_year,
t3.sa,
t3.cv_1a,
t3.cv_1b,
t3.sur_ben,
t3.np,
t3.rsv2_re,
t3.rsv1_re,
t3.np_,
t4.prem as prem_std,
if(
t5.pol_no is not null,
-1,
if(
substr(t1.buy_datetime,6,2) = substr('2022-10',6,2) and t3.policy_year <= t1.ppp,
t4.prem,
0
)
) as prem_thismonth,
'2022-10' as month
from insurance_ods.policy_benefit t1
join insurance_ods.policy_client t2 on t1.user_id = t2.user_id
join insurance_app.policy_actuary t3
on t1.age_buy = t3.age_buy
and t2.sex = t3.sex
and t1.ppp = t3.ppp
and t3.policy_year = floor(months_between('2022-10',t1.buy_datetime) / 12) + 1
join insurance_dw.prem_std t4
on t1.ppp = t4.ppp and t1.age_buy = t4.age_buy and t2.sex = t4.sex
left join insurance_ods.policy_surrender t5
on t1.pol_no = t5.pol_no;
-- 校验当月应交保费信息:
select * from insurance_app.policy_result where prem_thismonth = -1 and substr(buy_datetime,6,2) = '10' ;
/*
-- 思考: 用户需要在什么时候缴纳保费呢?
情况1: 用户投保的月份 和 当前要计算的月份是一致的
情况2: 保单年度 必须 要 小于等于缴费期
情况3: 用户不能退保
*/
-- 如何推算用户的保单年度呢?
/*
假设用户在 2020年 8月 5号 购买的保险
请问 2022年 7月份, 属于第几个保单年度呢? 第二个保单年度
请问 2022年 8月份, 属于第几个保单年度呢? 第三个保单年度
请问 2022年 9月份, 属于第几个保单年度呢? 第三个保单年度
months_between(当前时间, 之前时间) --> 计算两个时间之间相差多少个月
floor: 表示向下取整
ceil: 表示向上取整
*/
select floor(months_between('2022-08-04','2020-08-05') / 12) + 1 as months;
/*
思考: 什么时候, 用户需要缴纳保费了呢?
*/6.3 计算保费收入增长率
需求:
1、每月计算一次。下月初计算上月的数据。
2、当月保费收入增长率prem_incre_rate= (当月末保费收入-上月末保费收入)/上月末保费收入
3、例:2021年1月31日,个险渠道保费收入为100元, 2021年2月28日,个险保费收入为110元,则,个险保费收入增长率 = (110-100)/100 = 10%
目标表
| month | 统计月份 | 分区字段 |
|---|---|---|
| prem | 本月保费收入 | 对policy_result的本月的prem_thismonth求和 |
| last_prem | 上月保费收入 | 对policy_result的上月的prem_thismonth求和 |
| prem_incre_rate | 保费收入增长率 | (本月保费收入-上月保费收入)/ 上月保费收入 |
- 1- 构建目标表:
--保费收入增长率
drop table if exists insurance_app.app_agg_month_incre_rate;
CREATE TABLE if not exists insurance_app.app_agg_month_incre_rate
(
prem DECIMAL(24, 6) comment '本月保费收入',
last_prem DECIMAL(24, 6) comment '上月保费收入',
prem_incre_rate DECIMAL(6, 4)comment '保费收入增长率'
) partitioned by (month string comment '月份')
comment '保费收入增长率表' row format delimited fields terminated by '\t';- 2- SQL实现
-- 计算保费收入增长率
with t1 as (
select
sum(
if(
month = '2022-09' and prem_thismonth > 0 ,
prem_thismonth,
0
)
) as prem,
sum(
if(
month = '2022-08' and prem_thismonth > 0 ,
prem_thismonth,
0
)
) as last_prem
from insurance_app.policy_result where month = '2022-08' or month = '2022-09'
)
insert overwrite table insurance_app.app_agg_month_incre_rate partition (month)
select
prem,
last_prem,
cast((prem - last_prem) / last_prem * 100 as decimal(12,4)) as prem_incre_rate,
'2022-09' as month
from t1;6.4 计算首年保费与保费收入比
需求:
1、每月计算一次。下月初计算上月的数据。
2、first_of_total_prem= 首年保费收入/保费收入
目标表字段:
| month | 统计月份 | |
|---|---|---|
| first_prem | 首年保费 | |
| total_prem | 已经收取的所有保费 | 1、如果在缴费期内正常缴费,则取已经交过的所有保费。2、如果已经缴纳完毕,则取总体交过的所有保费。3、如果在缴费期内退保,取退保前缴纳的所有保费。 |
| first_of_total_prem | 首年保费与保费收入比 | 首年保费收入/保费收入 |
建表操作:
drop TABLE if exists insurance_app.app_agg_month_first_of_total_prem;
CREATE TABLE if not exists insurance_app.app_agg_month_first_of_total_prem
(
first_prem DECIMAL(24, 6),
total_prem DECIMAL(24, 6),
first_of_total_prem DECIMAL(8, 6)
) partitioned by (month string comment '月份')
comment '首年保费与保费收入比表' row format delimited fields terminated by '\t';计算操作
-- 计算首年保费与保费收入比: 2022-09
-- 首年保费: 用户第一次买保险所缴纳的费用, 一共产生了多少个保单, 把每个保单的保费加在一起就是首年保费
-- 总保费: 保费 * 实际缴费年数
with t1 as (
select
sum(t1.prem_std) as first_prem,
sum(
least(
t1.prem_std * t1.policy_year,
t1.prem_std * t1.ppp,
t1.prem_std * (floor(months_between(t2.elapse_date,t1.buy_datetime) / 12) + 1)
)
) as total_prem
from (select * from insurance_app.policy_result where month = '2022-09') as t1
left join insurance_ods.policy_surrender t2 on t1.pol_no = t2.pol_no
)
select
first_prem,
total_prem,
cast(first_prem / total_prem * 100 as decimal(17,4)) as first_of_total_prem,
'2022-09' as month
from t1;
-- 思考: 如何计算总保费? 核心计算用户实际缴费年数
/*
三种情况. 选择其中最小的即可
情况1: 用户保单年度 <= 缴费期 计算: 保费 * 保单年度
情况2: 用户保单年度 > 缴费期 计算: 保费 * 缴费期
情况3: 如果用户在没到缴费期之前, 就已经退保 计算: 保费 * 截止到退保的实际保单年度
思考: 假设 用户在 2001年 05 月份 购买保险 缴费期 20年 在2021年08月份退保了 计算的时候 2022-09月份
保费 * 保单年度 22年
保费*缴费期 20
保费 * 退保的实际保单年度 21年
*/6.5 个人营销渠道的件均保费
需求:
1、每月计算一次。下月初计算上月的数据。
2、个人营销渠道的件均保费 premium per policy of individual marketing channel
个人营销渠道的件均保费=(本月的)个人营销渠道的首年原保费收入÷(本月的)个人营销渠道的新单件数
解释:个人营销渠道的件均保费是指个人营销渠道的首年原保费收入与新单件数的比值。
目标表:
| insur_code | 保险代码 | |
|---|---|---|
| insur_name | 保险名称 | |
| prem_per_pol | 个人营销渠道的件均保费 | |
| month | 月份 |
drop TABLE if exists insurance_app.app_agg_month_premperpol;
CREATE TABLE if not exists insurance_app.app_agg_month_premperpol
(
insur_code string comment '保险代码',
insur_name string comment '保险名称',
prem_per_pol DECIMAL(38, 2) comment '个人营销渠道的件均保费'
) partitioned by (month string comment '月份')
comment '个人营销渠道的件均保费' row format delimited fields terminated by '\t';SQL实现操作
-- 个人营销渠道的件均保费: 每一款保险 首年保费与 保单数量 计算平均每个保单保费
insert overwrite table insurance_app.app_agg_month_premperpol partition (month)
select
insur_code,
insur_name,
cast(sum(prem_std) / count(pol_no) as decimal(17,4)) as prem_per_pol,
'2022-09' as month
from insurance_app.policy_result where month = '2022-09'
group by insur_code,insur_name;6.6 死亡发生率和残疾发生率
需求:
死亡发生率 =在月末时点,统计每个年龄的人群,按一岁一组,计算其中历史所有发生过死亡的保单数/所有的有效保单
残疾发生率 =在月末时点,统计每个年龄的人群,按一岁一组,计算其中历史所有发生过残疾的保单数/所有的有效保单
死亡发生率和残疾发生率表结构说明:
| insur_code | 保险代码 | |
|---|---|---|
| insur_name | 保险名称 | |
| age | 年龄 | |
| sg_cnt | 发生身故的保单数 | |
| sc_cnt | 发生伤残的保单数 | |
| all_cnt | 所有有效保单数 | |
| sg_rate | 死亡发生率 | |
| sc_rate | 残疾发生率 | |
| month | 月份 |
建表
DROP TABLE if exists insurance_app.app_agg_month_mort_dis_rate;
CREATE TABLE if not exists insurance_app.app_agg_month_mort_dis_rate
(
insur_code string comment '保险代码',
insur_name string comment '保险名称',
age int,
sg_rate decimal(8,6),
sc_rate decimal(8,6)
) partitioned by (month string comment '月份')
comment '死亡发生率和残疾发生率表' row format delimited fields terminated by '\t';SQL实现:
-- 死亡发生率和残疾发生率
with t1 as (
select
t1.insur_name,
t1.insur_code,
(t1.age_buy + floor(months_between(t2.claim_date,t1.buy_datetime) / 12)) as age,
count(
if(
t2.claim_item like 'sc%',
t1.pol_no,
NULL
)
) as sc_cnt,
count(
if(
t2.claim_item like 'sg%',
t1.pol_no,
NULL
)
) as sg_cnt,
count(t1.pol_no) as total_age_cnt
from (select * from insurance_app.policy_result where month = '2022-09') t1
left join insurance_ods.claim_info t2 on t1.pol_no = t2.pol_no
group by t1.insur_name,t1.insur_code,(t1.age_buy + floor(months_between(t2.claim_date,t1.buy_datetime) / 12))
),
t2 as (
select
insur_name,
insur_code,
age,
sc_cnt,
sg_cnt,
sum(total_age_cnt) over(partition by insur_code order by age rows between unbounded preceding and unbounded following) as total_cnt
from t1
)
insert overwrite table insurance_app.app_agg_month_mort_dis_rate partition (month)
select
insur_name,
insur_code,
age,
cast(sg_cnt / total_cnt * 100 as decimal(17,4)) as sg_rate,
cast(sc_cnt / total_cnt * 100 as decimal(17,4)) as sc_rate,
'2022-09' as month
from t2 where age is not null;
-- 注意: 此处按照年龄分组, 年龄实际为发生理赔的年龄6.7 新业务价值率
需求:
1、每月计算一次。下月初计算上月的数据。
2、新业务价值率(NBEV,New Business Embed Value)= PV(预期各年利润) / 首年保费收入
3、对一个产品的一个保单的业务价值率而言,它存在prem_std_real表中。
4、对一个产品的多张保单而言,
第1张单,期交保费100元,新业务价值率是10%
第2张单,期交保费是200元,新业务价值率是20%
则新业务价值率 = (10010% + 200 20%) / 300 = 16.67%
目标表:
| insur_code | 保险代码 | |
|---|---|---|
| insur_name | 保险名称 | |
| nbev | 新业务价值率 | |
| month | 月份 |
drop table if exists insurance_app.app_agg_month_nbev;
create table if not exists insurance_app. app_agg_month_nbev
(
insur_code string comment '保险代码',
insur_name string comment '保险名称',
nbev decimal(38,11) comment '新业务价值率'
) partitioned by (month string comment '月份')
comment '新业务价值率表' row format delimited fields terminated by '\t';sql实现:
-- 计算新业务价值率:
insert overwrite table insurance_app.app_agg_month_nbev partition (month = '2022-09')
select
t1.insur_code,
t1.insur_name,
sum(t1.prem_std * t2.nbev) / sum(t1.prem_std) as nbev
from (select * from insurance_app.policy_result where month = '2022-09' ) t1
join insurance_ods.prem_std_real t2 on t1.sex = t2.sex and t1.ppp = t2.ppp and t1.age_buy = t2.age_buy
group by t1.insur_code,t1.insur_name6.8 高净值客户比例
需求:
1、每月计算一次。下月初计算上月的数据。
2、高净值客户,指填写的信息里,年收入超过1000万的客户
3、高净值客户比例= 高净值客户 / 总客户。例如100个客户,高净值客户10个,则高净值客户比例 = 10/100 = 10%
目标表:
| high_net_rate | 高净值客户比例 | |
|---|---|---|
| month | 月份 |
drop table if exists insurance_app.app_agg_month_high_net_rate;
create table if not exists insurance_app.app_agg_month_high_net_rate(
high_net_rate decimal(8, 6) comment '高净值客户比例'
) partitioned by (month string comment '月份')
comment '高净值客户比例表' row format delimited fields terminated by '\t';SQL:
-- 计算高净值客户的比例
with t1 as(
select
count(distinct t1.user_id) as total_cnt,
count( distinct
if(
t2.income >= 10000000,
t2.user_id,
NULL
)
) as hight_cnt
from (select * from insurance_app.policy_result where month = '2022-09' ) t1
join insurance_ods.policy_client t2 on t1.user_id = t2.user_id
)
insert overwrite table insurance_app.app_agg_month_high_net_rate partition (month = '2022-09')
select
hight_cnt / total_cnt * 100 as high_net_rate
from t1;6.9 各地区的汇总保费
需求:
1、 每月计算一次。下月初计算上月的数据。
2、 依据精算数据表policy_result的当月数据,按区域分组,统计当月时刻的总投保人数,当月收取的保费汇总,当月时刻的总现金价值,总生存金,总准备金。
目标表:
| direction | 所在区域 |
|---|---|
| sum_users | 总投保人数 |
| sum_prem | 当月保费汇总 |
| sum_cv_1b | 总现金价值 |
| sum_sur_ben | 总生存金 |
| sum_rsv2_re | 总准备金 |
| month | 月份 |
drop table if exists insurance_app.app_agg_month_dir;
create table if not exists insurance_app.app_agg_month_dir
(
direction string comment '所在区域',
sum_users bigint comment '总投保人数',
sum_prem decimal(24) comment '当月保费汇总',
sum_cv_1b decimal(27,2) comment '总现金价值',
sum_sur_ben decimal(27) comment '总生存金',
sum_rsv2_re decimal(27,2) comment '总准备金'
) partitioned by (month string comment '月份')
comment '各地区的汇总保费表' row format delimited fields terminated by '\t';sql:
-- 各地区的汇总保费
insert overwrite table insurance_app.app_agg_month_dir partition (month)
select
direction,
count(distinct user_id) as sum_users,
sum(
if(
prem_thismonth > 0,
prem_thismonth,
0
)
) as sum_prem,
sum(cv_1b) as sum_cv_1b,
sum(sur_ben) as sum_sur_ben,
sum(rsv2_re) as sum_rsv2_re,
'2022-09' as month
from insurance_app.policy_result where month = '2022-09'
group by direction;7. 项目上线至Yarn平台
7.1 精算系统部署操作
在精算系统中, 主要是用于计算: 保费参数因子, 保费 现金价值 保险准备金, 同时整个计算流程还包含有自定义函数, 所有说我们整个精算系统是基于PY脚本统一的调度SQL脚本来执行
部署精算系统 本质上, 就是在部署PY脚本,最终通过Spark-submit来提交PY脚本 将其部署到Yarn平台上
准备工作: 在上线之前, 将相关的脚本, 修改为部署前的状态, 同时在上线前, 还需要对程序进行测试操作
1- 将SQL脚本中所有的中间测试的SQL全部删除, 仅保留关键性的测试SQL即可
- 说明: 保留查询目标表的SQL. 其余查询SQL全部删除
2- 将脚本中设置的相关参数全部删除, 可以先移植到py脚本统一设置, 后续放置到spark-sumit中
3- 将所有的视图, 以及表, 全部切换为临时视图
4- 将使用超过1次以上的视图, 全部设置缓存
5- 执行PY脚本, 整体测试,查看是否OK
上线部署:
1- 调整python脚本中, 关于Master设置操作
- 方案: 要不直接删除master参数配置, 要不将其修改为yarn
2- 将所有的配置参数, 全部剔除, 后续在外部通过命令的方式设置即可
.config("spark.sql.shuffle.partitions", 4) \
.config("spark.sql.decimalOperations.allowPrecisionLoss", False) \
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node1:9083") \- 3- 编写一个shell脚本, 用于提交Spark程序
- 脚本文件: _insurance_FIAA.sh
- 放置位置: _03_sh_spark 目录中
#!/bin/bash
export SPARK_HOME=/export/server/spark/
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--conf "spark.sql.shuffle.partitions=12" \
--conf "spark.sql.decimalOperations.allowPrecisionLoss=false" \
--conf "spark.sql.warehouse.dir=hdfs://node1:8020/user/hive/warehouse" \
--conf "hive.metastore.uris=thrift://node1:9083" \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
--jars /export/data/workspace/ky05_itcast_insurance/_04_software/mysql-connector-java-5.1.32.jar \
--driver-cores 1 \
--driver-memory 1G \
--executor-cores 2 \
--executor-memory 4G \
--num-executors 2 \
--queue default \
/export/data/workspace/ky05_itcast_insurance/main/insurance_FIAA_main.py- 4- 测试shell脚本是否可以正常的运行
cd /export/data/workspace/ky05_itcast_insurance/_03_sh_spark
dos2unix _insurance_FIAA.sh
sh _insurance_FIAA.sh- 5- 测试成功后, 可以将这个脚本替换为cluster模式, 然后将其设置到DS中,进行调度管理即可
方案一: 不定时方案, 通过接口触发的方式以及手动触发的方式来进行
接口触发方式:
DS整个调度任务, 配置完成后, 是可以通过编写代码的方式, 通过代码的方式请求DS的对应的接口地址, 从而执行调度任务, 这样可以与业务系统进行组合, 形成一套完整的程序, 一旦检测到相关的精算系统配置业务表发生了变化, 立即触发采集工作, 以及立即触发重新执行精算计算的工作
好处: 实时性更强一些
手动触发模式: 当业务端相关精算配置表发生变更后, 业务人员会通知我们进行重新处理, 我们进行手动触发执行一次即可
适用于: 长期都不会任何的变化情况
方案二: 基于定时执行(推荐)
一般和数据采集的定时调度的周期保持一致, 比如数据擦剂一天一次, 然后后续的精算系统的处理也是一天一次
甚至 可以将精算系统直接配置到数据采集的后续节点上可能出现的错误:
原因: 缺少连接MySQL数据库的驱动包
如何放置驱动包?
需要将驱动添加到以下几个位置中:
1- anaconda的python的pyspark的jars目录下: pycharm在右键运行的时候, 会优先从这个目录下加载jar包
BASE环境: /root/anaconda3/lib/python3.8/site-packages/pyspark/jars/
虚拟环境: /root/anaconda3/envs/虚拟环境名称/lib/python3.8/site-packages/pyspark/jars/
2- spark的家路径的jars目录下: 主要是用于spark-submit提交到到local或者spark集群模式的时候, 以及如果在本地运行, 设置spark的家目录环境, 也同样会加载这个目录下的jar包
/export/server/spark/jars/
3- HDFS的spark的jars目录下: 主要是用于通过spark-submit 提交到Yarn集群的时候
hdfs://node1:8020/spark/jars 目录下
说明:
以上三个环境, 适合于添加经常使用的jar包, 如果是一些不经常使用的jar包, 测试可以只在方式一中或者是方式二尝试添加即可. 后续部署上线在通过spark-submit 使用 --jars 来执行相关的jar包即可7.2 APP层部署操作
整个APP层相关的统计指标计算操作, 都是通过一个SQL脚本来实现的, 并不需要向精算系统一样, 需要使用一个PY脚本来处理, 思考: 如何运行这个SQL脚本呢?
回顾:
请问如果是一个HIVE的SQL脚本, 如何运行呢?
hive -S -e | -f
如果运行SQL语句:
./hive -e 'sql语句'
如果运行SQL脚本文件:
./hive -f 'sql脚本文件'
-S : 表示静默执行在 spark中, 如何运行SQL脚本呢? 同样也提供了类似的操作: spark-sql
同样对于APP层调度操作, 也是需要构建一个SHELL脚本, 然后使用DS完成整个调度管理操作
目前整个SQL的脚本中, 用于计算了某一个固定的月份, 但是实际上每月执行一次, 每月处理的月份都是不一样的, 需要动态的传递
- 构建SHELL脚本
思考1: 如何自动获取当月 上个月 和 上上个月的日期呢? 比如现在 2022-10 2022-09 2022-08
当月: date +'%Y-%m'
上个月: date -d '-1 month' +'%Y-%m'
上上个月: date -d '-2 month' +'%Y-%m'
思考2: 在shell脚本中, 如何获取外部传递参数呢?
$#: 获取外部传递了多少个参数
$N: 获取第几个参数 例如 $1 表示获取第一个参数
思考3: 当执行shell脚本的时候, 如果外部传递了一个当月的月份信息, 请根据当月月份获取其上月和上上也的日期
传递参数: 2022-05
this_month=$1
last_month=`date -d "${this_month}-01 -1 month" +'%Y-%m'`
before_last_month=`date -d "${this_month}-01 -2 month" +'%Y-%m'`
思考4: 如何在shell脚本编写if判断语句:
功能: 当外部传递参数了, 按照外部参数来处理, 如果没有传递, 自动获取当月 上月和上上月日期
if [ $# == 1 ]
then
this_month=$1
last_month=`date -d "${this_month}-01 -1 month" +'%Y-%m'`
before_last_month=`date -d "${this_month}-01 -2 month" +'%Y-%m'`
else
this_month=`date +'%Y-%m'`
last_month=`date -d '-1 month' +'%Y-%m'`
before_last_month=`date -d '-2 month' +'%Y-%m'`
fi编写shell脚本:
- shell脚本文件名: _insurance_app.sh
- 放置位置: _03_sh_spark目录中
#!/bin/bash
export SPARK_HOME=/export/server/spark/
if [ $# == 1 ]
then
this_month=$1
last_month=`date -d "${this_month}-01 -1 month" +'%Y-%m'`
before_last_month=`date -d "${this_month}-01 -2 month" +'%Y-%m'`
else
this_month=`date +'%Y-%m'`
last_month=`date -d '-1 month' +'%Y-%m'`
before_last_month=`date -d '-2 month' +'%Y-%m'`
fi
app_sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table insurance_app.policy_result partition (month)
select
t1.pol_no,
t1.user_id,
t2.name,
t2.sex,
t2.birthday,
t1.ppp,
t1.age_buy,
t1.buy_datetime,
t1.insur_name,
t1.insur_code,
t2.province,
t2.city,
t2.direction,
t3.bpp,
t3.policy_year,
t3.sa,
t3.cv_1a,
t3.cv_1b,
t3.sur_ben,
t3.np,
t3.rsv2_re,
t3.rsv1_re,
t3.np_,
t4.prem as prem_std,
if(
t5.pol_no is not null,
-1,
if(
substr(t1.buy_datetime,6,2) = substr('${this_month}',6,2) and t3.policy_year <= t1.ppp,
t4.prem,
0
)
) as prem_thismonth,
'${this_month}' as month
from insurance_ods.policy_benefit t1
join insurance_ods.policy_client t2 on t1.user_id = t2.user_id
join insurance_app.policy_actuary t3
on t1.age_buy = t3.age_buy
and t2.sex = t3.sex
and t1.ppp = t3.ppp
and t3.policy_year = floor(months_between('${this_month}',t1.buy_datetime) / 12) + 1
join insurance_dw.prem_std t4
on t1.ppp = t4.ppp and t1.age_buy = t4.age_buy and t2.sex = t4.sex
left join insurance_ods.policy_surrender t5
on t1.pol_no = t5.pol_no;
with t1 as (
select
sum(
if(
month = '${last_month}' and prem_thismonth > 0 ,
prem_thismonth,
0
)
) as prem,
sum(
if(
month = '${before_last_month}' and prem_thismonth > 0 ,
prem_thismonth,
0
)
) as last_prem
from insurance_app.policy_result where month = '${before_last_month}' or month = '${last_month}'
)
insert overwrite table insurance_app.app_agg_month_incre_rate partition (month)
select
prem,
last_prem,
cast((prem - last_prem) / last_prem * 100 as decimal(12,4)) as prem_incre_rate,
'${last_month}' as month
from t1;
"
${SPARK_HOME}/bin/spark-sql -S \
--master yarn \
--deploy-mode client \
--conf "spark.sql.shuffle.partitions=12" \
--conf "spark.sql.decimalOperations.allowPrecisionLoss=false" \
--conf "spark.sql.warehouse.dir=hdfs://node1:8020/user/hive/warehouse" \
--conf "hive.metastore.uris=thrift://node1:9083" \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
--driver-cores 1 \
--driver-memory 1G \
--executor-cores 2 \
--executor-memory 4G \
--num-executors 2 \
--queue default \
-e "${app_sql}"- 测试通过OK后, 将部署模式更改为cluster, 最终将其放置到DS中进行定时调度即可, 定时调度周期为月(每月的月初1号执行)
注意: 事情还没有处理完成, 目前APP层脚本运行完成后, 数据都是在APP层对应的表中, 后续需要将APP层表数据导出到应用方指定的关系型数据库, 例如 MySQL
使用什么实现呢? sqoop
- 1- 先在MySQL中创建表
create table if not exists insurance_olap.policy_result (
pol_no varchar(200) COMMENT '保单号',
user_id varchar(200) comment '客户id',
name varchar(200) comment '姓名',
sex varchar(200) comment '性别',
birthday varchar(200) comment '出生日期',
ppp varchar(200) comment '缴费期',
age_buy bigint comment '投保年龄',
buy_datetime varchar(200) comment '投保日期',
insur_name varchar(200) COMMENT '保险名称',
insur_code varchar(200) COMMENT '保险代码',
province varchar(200) comment '所在省份',
city varchar(200) comment '所在城市',
direction varchar(200) comment '所在区域',
bpp smallint comment '保险期间,保障期',
policy_year smallint comment '保单年度',
sa decimal(12, 2) comment '保单年度基本保额',
cv_1a decimal(17, 7) comment '现金价值给付前',
cv_1b decimal(17, 7) comment '现金价值给付后',
sur_ben decimal(17, 7) comment '生存给付金',
np decimal(17, 7) comment '纯保费(CV.NP)',
rsv2_re decimal(17, 7) comment '年初责任准备金',
rsv1_re decimal(17, 7) comment '年末责任准备金',
np_ decimal(12, 2) comment '纯保费(RSV.np_) ',
prem_std decimal(14, 6) comment '每期交保费',
prem_thismonth decimal(14, 6) comment '本月应交保费',
month varchar(20) comment '月份'
) comment '客户保单精算结果表';- 编写sqoop脚本: _insurance_app_export.sh 放置在 _02_sh_sqoop目录中
#!/bin/bash
export SQOOP_HOME=/export/server/sqoop/
if [ $# == 1 ]
then
this_month=$1
else
this_month=`date +'%Y-%m'`
fi
${SQOOP_HOME}/bin/sqoop export \
--connect 'jdbc:mysql://node1:3306/insurance_olap?useUnicode=true&characterEncoding=utf8' \
--username root \
--password 123456 \
--table policy_result \
--fields-terminated-by '\t' \
--export-dir "/user/hive/warehouse/insurance_app.db/policy_result/month=${this_month}" \
-m 1可以在一个shell脚本中写多个sqoop的命令
整个编写后, 也是同样可以放置到DS上进行定时运行操作的
8- 项目的常见的面试题
1- 请简单介绍一下你最近做的这个项目 (请讲述你比较熟悉的项目...)
如何介绍项目: 5分钟
1.1 描述项目基本情况(什么行业的项目, 项目的背景)
背景: 本次项目是一个保险公司的重构项目, 之前整个项目是基于Oracle计算的, 后来管理这个项目的程序员离职了, 我们到了之后, 发现Oracle计算过程非常复杂的, 而且利用大量的存储过程, 导致我们维护非常麻烦的, 不好维度, 所以项目老大想更换一种新的方式完成整个精算计算操作, 所以后续采用spark SQL 来进行计算实现操作, 对计算流程进行了拆解, 简化难度, 提升维护性, 以及提升效率
1.2 描述出项目的架构: 技术架构 和 数据流转流程 (结合在一起来说)
1.3 描述出在本次项目, 我主要负责那一部分计算操作:
可选负责:
0- 基础数据采集操作
1- 负责保费参数因子计算 以及后续的保费计算
2- 负责现金价值指标计算
3- 负责保险准备金计算操作
4- 负责 行业业务指标统计分析
可组合:
0-1-2-4 : 适用于从0开始进入项目
0-1-3-4 : 适用于从0开始进入项目
0-1-4: 适用于从0开始进入项目, 中途接触了其他项目,后续又回来的
1-3-4 : 适合中期进入项目
1-2-4:适合中期进入项目
3-4 : 适合中期进入项目
2- 结合着项目描述, 面试官会挑选它所感兴趣, 并且也是你所负责的点, 进行深入询问:
例如:
保费参数因子是什么呢? 如何完成保费参数因子计算 ?
1- 描述保费因子主要是做什么? 支撑后续的保费 保险准备金 以及现金价值计算的基础表
2- 计算流程: 详细描述出具体的操作流程
2.1 - 首先精算师提供了Excel测算模板
2.2 - 接着根据测试模板确定涉及到维度和指标
2.3 - 对指标进行分析发现, 各项指标计算存在互相依赖, 需要进行迭代计算
2.4 - 如果每个指标计算都是有比较负责的规则, 所以我先了解计算规则, 将规则形成计算流程图,在形成过程中, 与精算部分由比较深入沟通, 了解每一个指标计算方案
2.5 - 根据形成计算流程图, 开始进行指标计算, 整个计算采用横向迭代计算方案, 每一步计算操作, 都通过spark SQL 构建视图临时保存起来, 逐步往下进行, 同时在计算过程中, 使用自定义UDAF函数, 完成一些比较负责的迭代计算操作
2.6 最终完成保费参数因子表计算操作, 将结果灌入到目标表中, 共计涉及到23个指标
3- 在整个计算过程中, 是否存在一些计算的难点, 或者 你认为整个计算操作, 你觉得最闪光在哪里? 经历最大挑战是什么?
可将难点: 展示能力地方
1- 自定义UDAF函数 : 遇到什么问题, 当时先采用什么方案解决的, 然后没解决掉, 有更换其他的方式, 怎么做的, 最后解决了
2- 数据量比较大, shuffle分区:
3- 精度问题
4- 缓存优化 临时窗口使用
5- group by 转换为窗口
4- 项目真实性的问题: 不难 但是容易答不出来
5- 相关原理性问题: -- 有很多了 spark hadoop hive zookeeper
pyspark的程序执行流程
Driver的job的调度流程
spark SQL的调度流程