
python_pandas包
day05_pandas相关内容
1. pandas的基本介绍
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
- Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
- Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;当我们学会Pandas之后,再学习Spark就更加简单快速
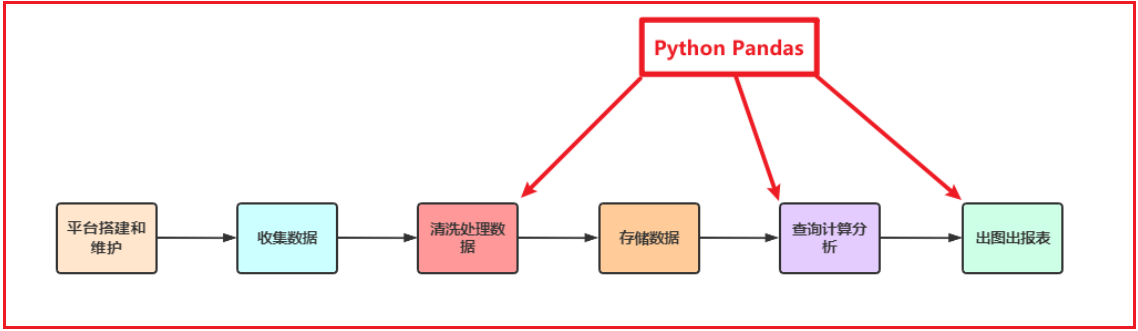
- Pandas在整个数据开发的流程中的应用场景
- 在大数据场景下,数据在流转的过程中,Python Pandas丰富的API能够更加灵活、快速的对数据进行清洗和处理
- Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
适用场景:
- 数据量大到excel严重卡顿,且又都是单机数据的时候,我们使用pandas
- pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用pandas
2. 安装pandas的库
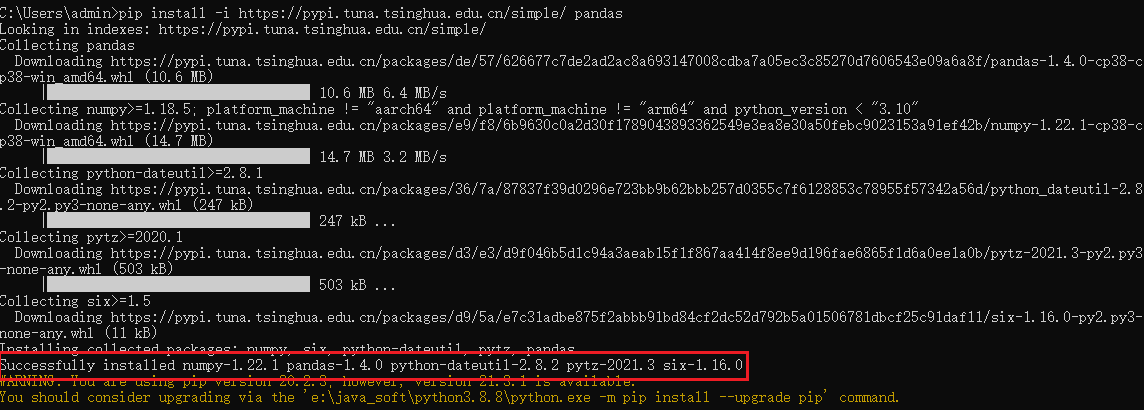
打开cmd界面, 执行 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
- https://pypi.tuna.tsinghua.edu.cn/simple/ 此地址为清华镜像的地址, 在国内下载python相关包的时候建议使用此地址
- 类似于: java中 下载 maven的jar包, 一般会设置 阿里云镜像地址
说明:
在安装python环境的时候, 除了基于之前直接安装python解析器方案, 其实安装python还有一些其他的操作,
比如说, 我们可以通过anaconda 方式来进行安装,
anaconda: 数据科学库
包含了python环境, 以及包含了非常多数据科学相关的库, 全部的集成在了一起, 如果是基于anaconda安装的时候, 很多的数据科学库就不需要自己安装了, anaconda都自带, 其中pandas其实就是anaconda库中一员
anaconda提供了虚拟环境方案, 可以在一个操作系统中, 安装不同版本的python环境, 各个环境之间还相对独立3. pandas的初体验
- 1-将资料中提供的数据集导入到data目录中

- 2- 创建python脚本, 导入pandas库
import pandas as pd- 3- 基于pandas加载数据
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )- 4- 基于pandas完成相关查询:
# 查询中国的GDP
china_gdp = df[df.country=='中国'] # df.country 选中名为country的列
china_gdp.head(10) # 显示前10条数据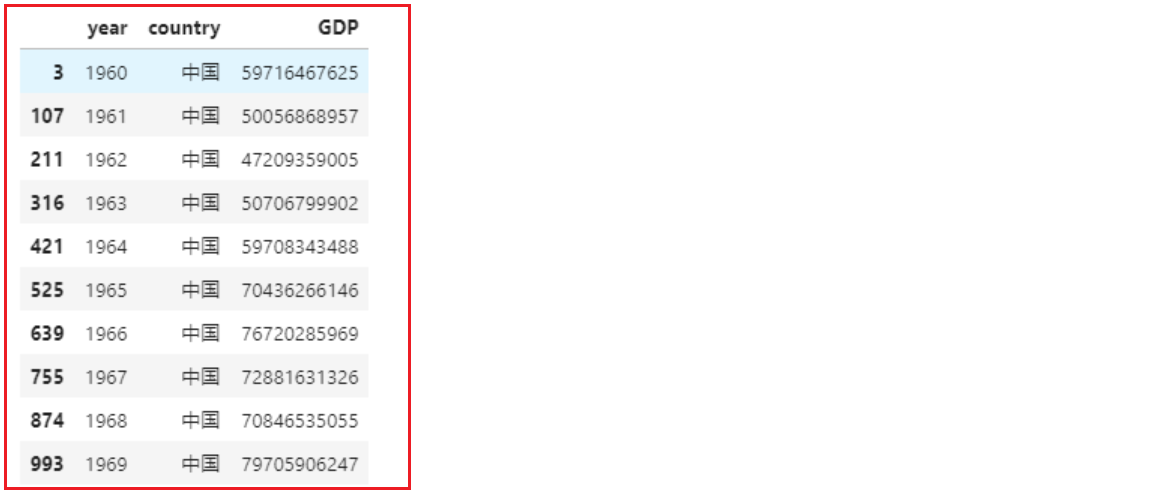
4. pandas的数据类型
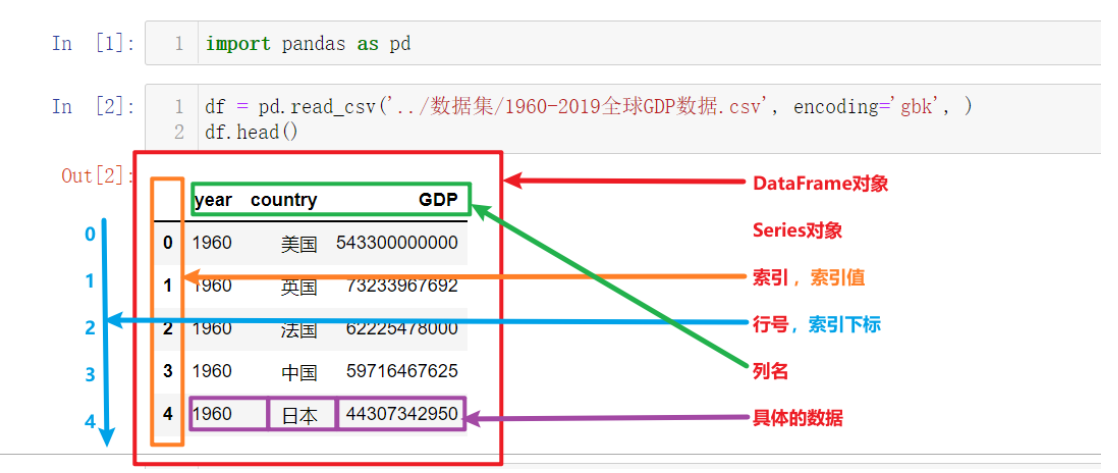
上图为上一节中读取并展示出来的数据,以此为例我们来讲解Pandas的核心概念,以及这些概念的层级关系:
- DataFrame: 表示的就是一个二维表
- Series: 每一个series可以理解为就是一列数据
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
- 索引列
- Series: 每一个series可以理解为就是一列数据
其中最核心的就是Pandas中的两个数据结构:DataFrame和Series
在一个dataFrame下, 是由多个series组成的
4.1 series对象
Series也是Pandas中的最基本的数据结构对象,下文中简称s对象;是DataFrame的列对象,series本身也具有索引。
Series是一种类似于一维数组的对象,由下面两个部分组成:
- values:一组数据(numpy.ndarray类型)
- index:相关的数据索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
4.1.1 创建Series对象
- 1- 导入pandas
import pandas as pd- 2- 通过list列表来创建
# 使用默认自增索引
s2 = pd.Series([1, 2, 3])
print(s2)
# 自定义索引
s3 = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
s3
结果为:
0 1
1 2
2 3
dtype: int64
A 1
B 2
C 3
dtype: int64- 3- 使用字典或元组创建series对象
#使用元组
tst = (1,2,3,4,5,6)
pd.Series(tst)
#使用字典:
dst = {'A':1,'B':2,'C':3,'D':4,'E':5,'F':6}
pd.Series(dst)4.1.2 Series对象常用API
构造一个series对象
s4 = pd.Series([i for i in range(6)], index=[i for i in 'ABCDEF'])
s4
# 返回结果如下
A 0
B 1
C 2
D 3
E 4
F 5
dtype: int64- 1- series对象常用属性和方法
# s对象有多少个值,int
len(s4)
s4.size
# s对象有多少个值,单一元素构成的元组 (6,)
s4.shape
# 查看s对象中数据的类型
s4.dtypes
# s对象转换为list列表
s4.tolist()
# s对象的值 array([0, 1, 2, 3, 4, 5], dtype=int64)
s4.values
# s对象的值转换为列表
s4.values.tolist()
# s对象可以遍历,返回每一个值
for i in s4:
print(i)
# 下标获取具体值
s4[1]
# 返回前2个值,默认返回前5个
s4.head(2)
# 返回最后1个值,默认返回后5个
s4.tail(1)
# 获取s对象的索引 Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
s4.index
# s对象的索引转换为列表
s4.index.to_list()
# s对象中数据的基础统计信息
s4.describe()
# 返回结果及说明如下
#count 6.000000 # s对象一共有多少个值
#mean 2.500000 # s对象所有值的算术平均值
#std 1.870829 # s对象所有值的标准偏差
#min 0.000000 # s对象所有值的最小值
#25% 1.250000 # 四分位 1/4位点值
#50% 2.500000 # 四分位 1/2位点值
#75% 3.750000 # 四分位 3/4位点值
#max 5.000000 # s对象所有值的最大值
#dtype: float64
# 标准偏差是一种度量数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。
# 四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。
# seriest对象转换为df对象
s4.to_frame()
s4.reset_index()4.1.3 Series 对象的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
两个Series之间计算,索引值相同的元素之间会进行计算;索引不同的元素最终计算的结果会填充成缺失值,用NaN表示
- Series和数值型变量计算
s4 * 5
# 返回结果如下
A 0
B 5
C 10
D 15
E 20
F 25
dtype: int64- 索引完全相同的两个Series对象进行计算
s4
# 构造与s4索引相同的s对象
s5 = pd.Series([10]*6, index=[i for i in 'ABCDEF'])
s5
# 两个索引相同的s对象进行运算
s4 + s5
# 返回结果如下
A 0
B 1
C 2
D 3
E 4
F 5
dtype: int64
A 10
B 10
C 10
D 10
E 10
F 10
dtype: int64
A 10
B 11
C 12
D 13
E 14
F 15
dtype: int64- 索引不同的两个s对象运算
s4
# 注意s6的最后一个索引值和s4的最后一个索引值不同
s6 = pd.Series([10]*6, index=[i for i in 'ABCDEG'])
s6
s4 + s6
# 返回结果如下
A 0
B 1
C 2
D 3
E 4
F 5
dtype: int64
A 10
B 10
C 10
D 10
E 10
G 10
dtype: int64
A 10.0
B 11.0
C 12.0
D 13.0
E 14.0
F NaN
G NaN
dtype: float644.2 DataFrame
4.2.1 创建DF对象
DataFrame的创建有很多种方式
- Serires对象转换为df:上一小节中学习了
s.to_frame()以及s.reset_index() - 读取文件数据返回df:在之前的学习中我们使用了
pd.read_csv('csv格式数据文件路径')的方式获取了df对象 - 使用字典、列表、元组创建df:接下来就展示如何使用字段、列表、元组创建df
- 使用字典加列表创建df,使默认自增索引
df1_data = {
'日期': ['2021-08-21', '2021-08-22', '2021-08-23'],
'温度': [25, 26, 50],
'湿度': [81, 50, 56]
}
df1 = pd.DataFrame(data=df1_data)
df1
# 返回结果如下
日期 温度 湿度
0 2021-08-21 25 81
1 2021-08-22 26 50
2 2021-08-23 50 56- 使用列表加元组创建df,并自定义索引
df2_data = [
('2021-08-21', 25, 81),
('2021-08-22', 26, 50),
('2021-08-23', 27, 56)
]
df2 = pd.DataFrame(
data=df2_data,
columns=['日期', '温度', '湿度'],
index = ['row_1','row_2','row_3'] # 手动指定索引
)
df2
# 返回结果如下
日期 温度 湿度
row_1 2021-08-21 25 81
row_2 2021-08-22 26 50
row_3 2021-08-23 27 564.2.2 DataFrame对象常用API
- DataFrame对象常用API与Series对象几乎相同
# 返回df的行数
len(df2)
# df中数据的个数
df2.size
# df中的行数和列数,元组 (行数, 列数)
df2.shape
# 返回列名和该列数据的类型
df2.dtypes
# 返回nparray类型的2维数组,每一行数据作为一维数组,所有行数据的数组再构成一个二维数组
df2.values
# 返回df的所有列名
df2.columns
# df遍历返回的只是列名
for col_name in df2:
print(col_name)
# 返回df的索引对象
df2.index
# 返回第一行数据,默认前5行
df2.head(1)
# 返回倒数第1行数据,默认倒数5行
df2.tail(1)
# 返回df的基本信息:索引情况,以及各列的名称、数据数量、数据类型
df2.info() # series对象没有info()方法
# 返回df对象中所有数字类型数据的基础统计信息
# 返回对象的内容和Series.describe()相同
df2.describe()
# 返回df对象中全部列数据的基础统计信息
df2.describe(include='all')4.2.3 DataFrame对象的运算
当DataFrame和数值进行运算时,DataFrame中的每一个元素会分别和数值进行运算,但df中的数据存在非数值类型时不能做加减法运算
两个DataFrame之间、以及df和s对象进行计算,和2个series计算一样,会根据索引的值进行对应计算:当两个对象的索引值不能对应时,不匹配的会返回NaN
- df和数值进行运算
f2 * 2 # 不报错
df2 + 1 # 报错,因为df2中有str类型(Object)的数据列- df和df进行运算
# 索引完全不匹配
df1 + df2
# 构造部分索引和df2相同的新df
df3 = df2[df2.index!='row_3']
df3
# 部分索引相同
df2 + df3
# 返回结果如下
日期 温度 湿度
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
row_1 NaN NaN NaN
row_2 NaN NaN NaN
row_3 NaN NaN NaN
日期 温度 湿度
row_1 2021-08-21 25 81
row_2 2021-08-22 26 50
日期 温度 湿度
row_1 2021-08-212021-08-21 50.0 162.0
row_2 2021-08-222021-08-22 52.0 100.0
row_3 NaN NaN NaN4.3 pandas的数据类型
- df或s对象中具体每一个值的数据类型有很多,如下表所示
| Pandas数据类型 | 说明 | 对应的Python类型 |
|---|---|---|
| Object | 字符串类型 | string |
| int | 整数类型 | int |
| float | 浮点数类型 | float |
| datetime | 日期时间类型 | datetime包中的datetime类型 |
| timedelta | 时间差类型 | datetime包中的timedelta类型 |
| category | 分类类型 | 无原生类型,可以自定义 |
| bool | 布尔类型 | True,False |
| nan | 空值类型 | None |
- 可以通过下列API查看s对象或df对象中数据的类型
s1.dtypes
df1.dtypes
df1.info() # s对象没有info()方法5. pandas多格式数据读写
常用读写文件函数清单
| 文件格式 | 读取函数 | 写入函数 |
|---|---|---|
| xlsx | pd.read_excel | df.to_excel |
| xls | pd.read_excel | df.to_excel |
| csv | pd.read_csv | df.to_csv |
| tsv | pd.read_csv | df.to_csv |
| json | pd.read_json | to_json |
| html | pd.read_html | df.to_html |
| sql | pd.read_sql | df.to_sql |
| 剪贴板 | df.read_clipboard | df.to_clipboard |
5.1 写文件
数据准备
# 使JupyterNotebook单个cell可以有多个输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
# 导包 加载数据集
import pandas as pd
# 构造df数据集
df = pd.DataFrame(
[
['1960-5-7', '刘海柱', '职业法师'],
['1978-9-1', '赵金龙', '大力哥'],
['1984-12-27', '周立齐', '窃格瓦拉'],
['1969-1-24', '于谦', '相声皇后']
],
columns=['birthday', 'name', 'AKA']
)
df- 以写入csv文件为例
df.to_csv('./写文件.csv') # 此时应该在运行代码的相同路径下就生成了一个名为“写文件.csv”的文件 注意:执行df.to_csv()时,文件需要关闭才能写入,不然会报 PermissionError: [Errno 13] Permission denied: 'xxxx.csv'的异常
5.2 读文件
以读取csv文件为例
df = pd.read_csv('./写文件.csv')
df
index_col 参数指定索引
index_col参数可以在读文件的时候指定列作为返回dataframe的索引,两种用法如下: * 通过列下标指定为索引 * 通过列名指定为索引- 通过列下标指定为索引
index_col=[列下标]
df = pd.read_csv('./写文件.csv', index_col=[0]) df- 通过列名指定为索引
index_col=['列名']
df = pd.read_csv('./写文件.csv', index_col=['Unnamed: 0']) df- 通过列下标指定为索引

parse_dates 参数指定列解析为时间日期类型
parse_dates参数可以在读文件的时候解析时间日期类型的列,两种作用如下: - 将指定的列解析为时间日期类型 - 通过列下标解析该列为时间日期类型 - 通过列名解析该列为时间日期类型 - 将df的索引解析为时间日期类型- 通过列下标解析该列为时间日期类型
parse_dates=[列下标]
pd.read_csv('./写文件.csv').info() pd.read_csv('./写文件.csv', parse_dates=[1]).info()- 通过列下标解析该列为时间日期类型

- 通过列名解析该列为时间日期类型
parse_dates=[列名]
pd.read_csv('./写文件.csv').info()
pd.read_csv('./写文件.csv', parse_dates=['birthday']).info()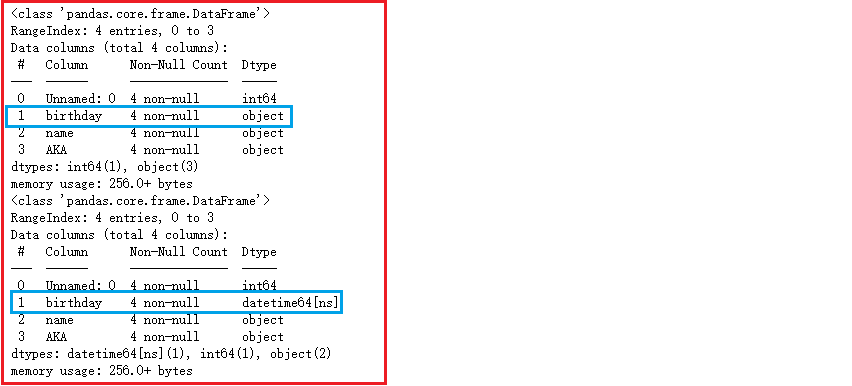
- 将df的索引解析为时间日期类型
parse_dates=True
df = pd.read_csv('./写文件.csv', index_col=[1], parse_dates=True)
df
df.index
- encoding 参数 指定编码格式
常见的编码格式有:ASCII、GB2312、UTF8、GBK 等
pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk').head()
- sep参数, 指定字段之间的分隔符号
默认的分隔符号为逗号, 当文件中的字段之间的分隔符号不是逗号的时候, 我们可以采用此参数来调整
pd.read_csv('../数据集/csv示例文件.csv', sep='\t', index_col=[0])
5.3 读写数据库
以MySQL数据库为例,此时默认你已经在本地安装好了MySQL数据库。如果想利用pandas和MySQL数据库进行交互,需要先安装与数据库交互所需要的python包
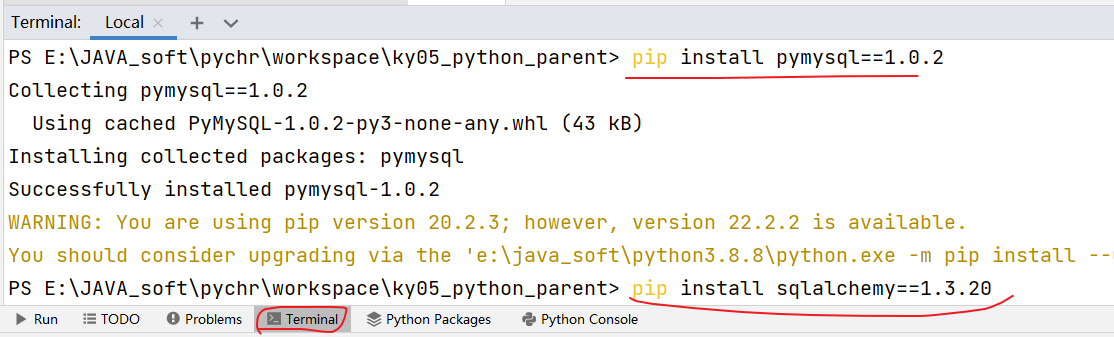
pip install pymysql==1.0.2
# 如果后边的代码运行提示找不到sqlalchemy的包,和pymysql一样进行安装即可
pip install sqlalchemy==1.3.20- 准备要写入数据库的数据
import pandas as pd
df = pd.read_csv('../数据集/csv示例文件.csv', sep='\t', index_col=[0])
df
- 创建数据库操作引擎对象并指定数据库
# 需要安装pymysql,部分版本需要额外安装sqlalchemy
# 导入sqlalchemy的数据库引擎
from sqlalchemy import create_engine
# 创建数据库引擎,传入uri规则的字符串
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
# mysql+pymysql://root:chuanzhi@127.0.0.1:3306/test?charset=utf8
# mysql 表示数据库类型
# pymysql 表示python操作数据库的包
# root:chuanzhi 表示数据库的账号和密码,用冒号连接
# 127.0.0.1:3306/test 表示数据库的ip和端口,以及名叫test的数据库
# charset=utf8 规定编码格式- 将数据写入MySQL数据库
# df.to_sql()方法将df数据快速写入数据库
df.to_sql('test_pdtosql', engine, index=False, if_exists='append')
# 第一个参数为数据表的名称
# 第二个参数engine为数据库交互引擎
# index=False 表示不添加自增主键
# if_exists='append' 表示如果表存在就添加,表不存在就创建表并写入- 此时我们就可以在本地test库的test_pdtosql表中看到写入的数据

从数据库中加载数据:
- 读取整张表, 返回dataFrame
# 指定表名,传入数据库连接引擎对象 pd.read_sql('test_pdtosql', engine- 使用SQL语句获取数据,返回dataframe
# 传入sql语句,传入数据库连接引擎对象 pd.read_sql('select name,AKA from test_pdtosql', engine)

6. dataFrame数据的增删改查操作
- 导包并加载数据:
import pandas as pd
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )
df2 = df.head()6.1 增加列
- 方式一: 通过直接赋值的方式添加新列
# 拷贝一份df
df3 = df2.copy()
# 一列数据都是固定值
df3['new col 1'] = 33
# 新增列数据数量必须和行数相等
df3['new col 2'] = [1, 2, 3, 4, 5]
df3['new col 3'] = df3.year * 2
# 分别查看增加数据列之后的df和原df
df3
df2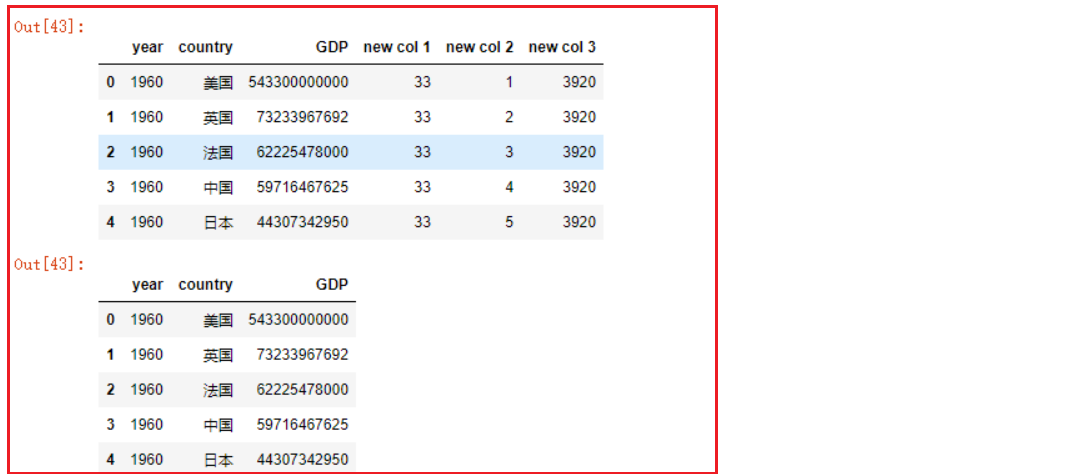
- 方式二: df.assign函数添加列
# 1. 新列名=单个数据或一组数据,一组数据的数量必须和df的行数相同
df2.assign(new0=66)
# df2.assign(new1=[1, 2, 3, 4]) # 报错
df2.assign(new1=[1, 2, 3, 4, 5])
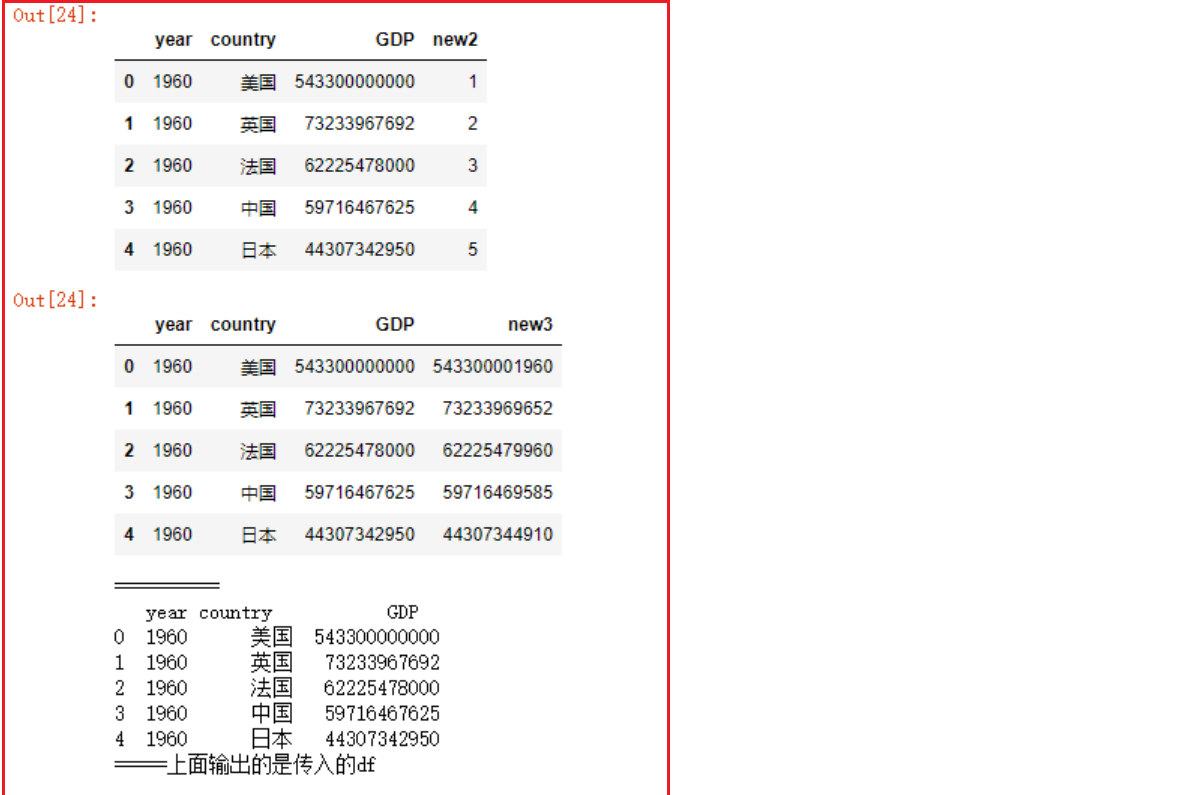
# 2.1 新列名=Series对象,该s对象的索引和df索引一致
s = pd.Series([1, 2, 3, 4, 5])
df2.assign(new2=s)
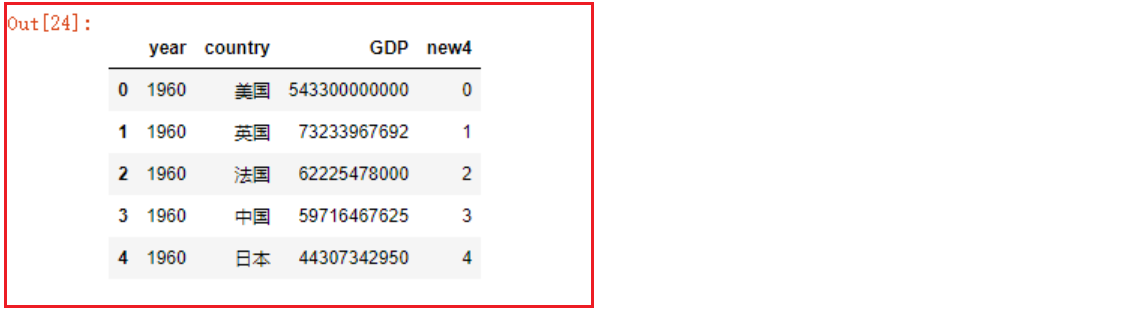
# 2.2 新列名=Series对象
df2.assign(new3=df2.year+df2.GDP)
# 3. 新列名=自定义函数名
# 该自定义函数必须接收df作为参数
# 该自定义函数可以返回:
# 3.1.单个数据
# 3.2.一组数量和df的行数相同的数据
# 3.3.和df索引相同的Series对象
def foo(df):
# 函数必须接收一个参数,该参数就是被传入的df对象
print('='*10)
print(df)
print('='*5 + '上面输出的是传入的df')
ret = df.index.values
# 可以返回一个变量
# return 'hahah'
# 也可以返回一组变量
return ret
df2.assign(new4=foo)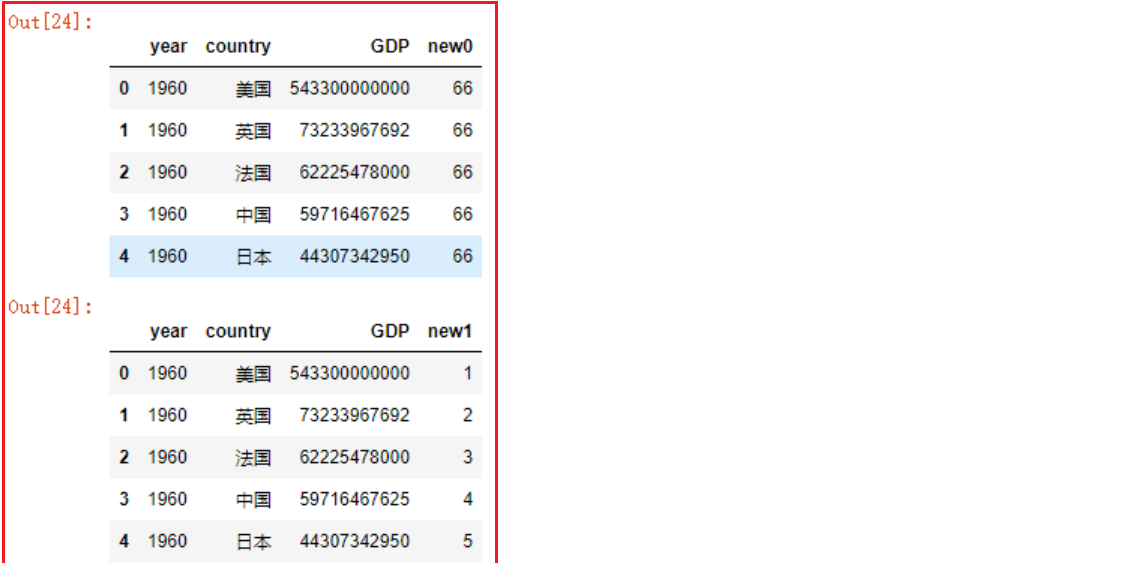
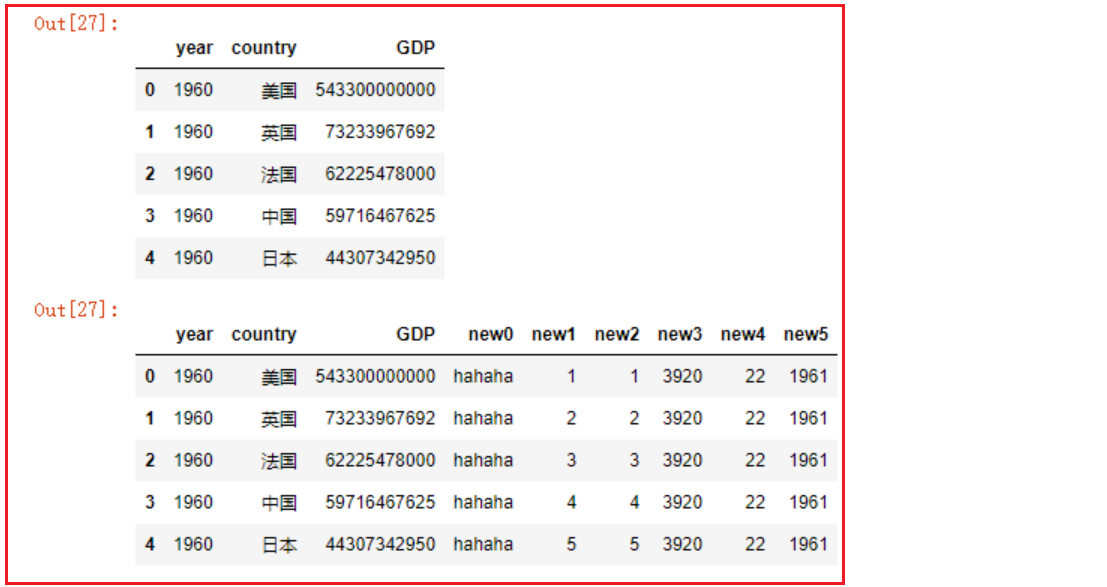
- df.assign函数可以同时添加多列
df2
def foo(df):
return 22
def bar(df):
return df.year + 1
df2.assign(
new0='hahaha',
new1=[1, 2, 3, 4, 5],
new2=pd.Series([1, 2, 3, 4, 5]),
new3=df.year*2,
new4=foo,
new5=bar
)
6.2 删除与去重
- 1- df.drop删除行数据
df3.drop([0]) # 默认删除行
df3.drop([0, 2, 4]) # 可以删除多行
df3.GDP.drop([0, 2]) # 对series对象按索引删除- 2- df.drop删除列数据
- df.drop默认删除指定索引值的行;如果添加参数
axis=1,则删除指定列名的列
- df.drop默认删除指定索引值的行;如果添加参数
df3.drop(['new col 3'], axis=1)- 3- 使用del删除指定的列
- 注意区别:
- del是直接永久删除原df中的列【慎重使用】
- drop是返回删除后的df或seires,原df或seires没有被修改
- 注意区别:
del df3['new col 3']
df3
# 重复运行本段代码将会报错,因为df3中的指定列在第一次运行时就被删除了- 4- Dataframe数据去重
# 添加一部分重复的数据
df4 = df2.append(df2).reset_index(drop=True)
# 实施去重操作
df4.drop_duplicates()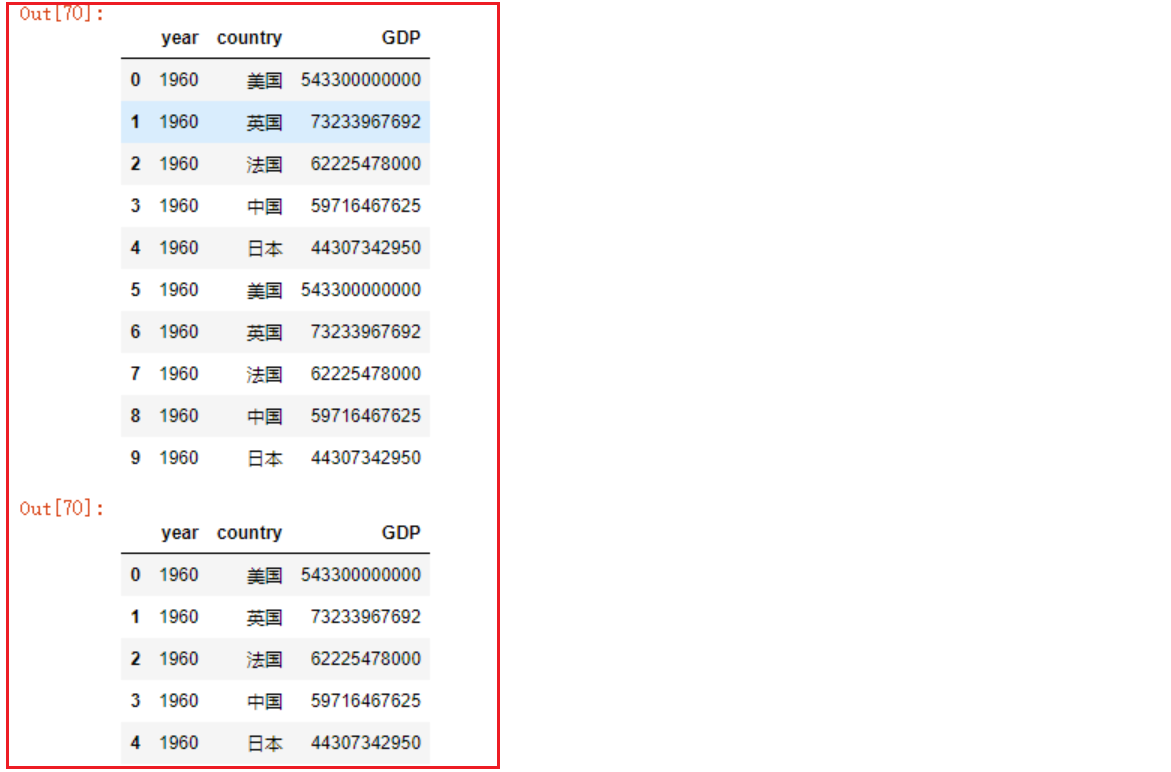
- 5- series去重
方式一:
df4.country.drop_duplicates()
# 返回结果如下
0 美国
1 英国
2 法国
3 中国
4 日本
Name: country, dtype: object
方式二:
df4.country.unique()
# 返回结果如下
array(['美国', '英国', '法国', '中国', '日本'], dtype=object)6.3 修改DataFrame中的数据
- 1- df.assign替换列
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )
df5 = df.head()
df5
df5 = df5.assign(GDP=66) # 可以接收单变量或列表、数组
df5
df # 此时原始的df不会发生改变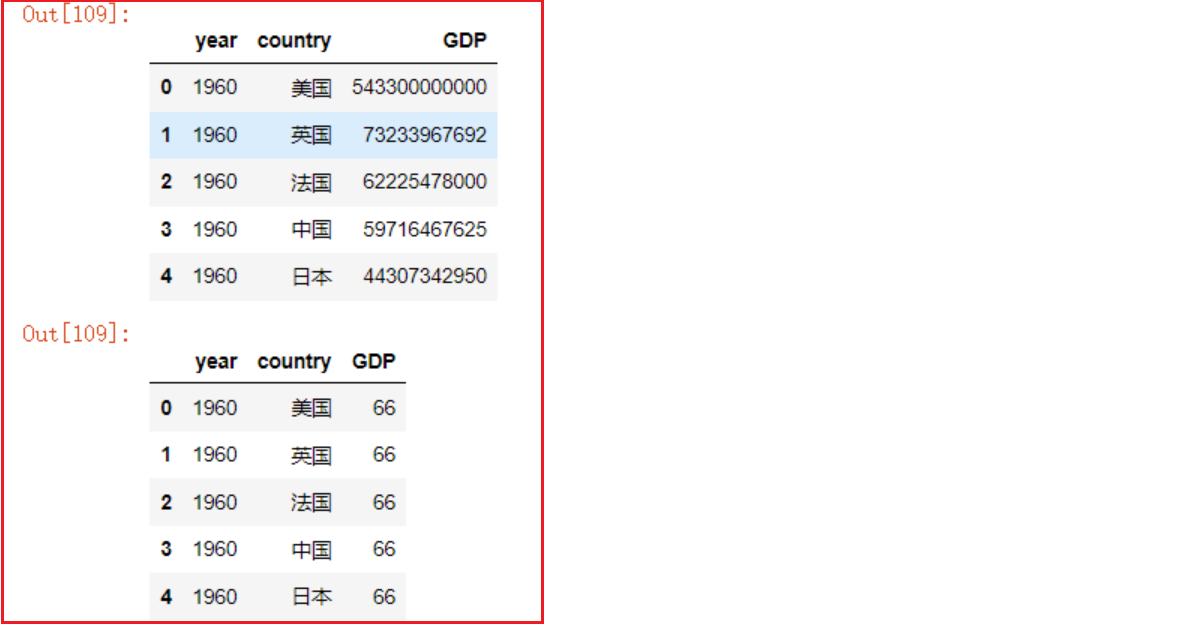
- 2- 直接对原始的DF进行赋值修改处理
- 一般不建议直接修改操作
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )
df5 = df.head()
df5
df5['GDP'] = [5, 4, 3, 2, 1]
df5
df # 此时原始的df会发生改变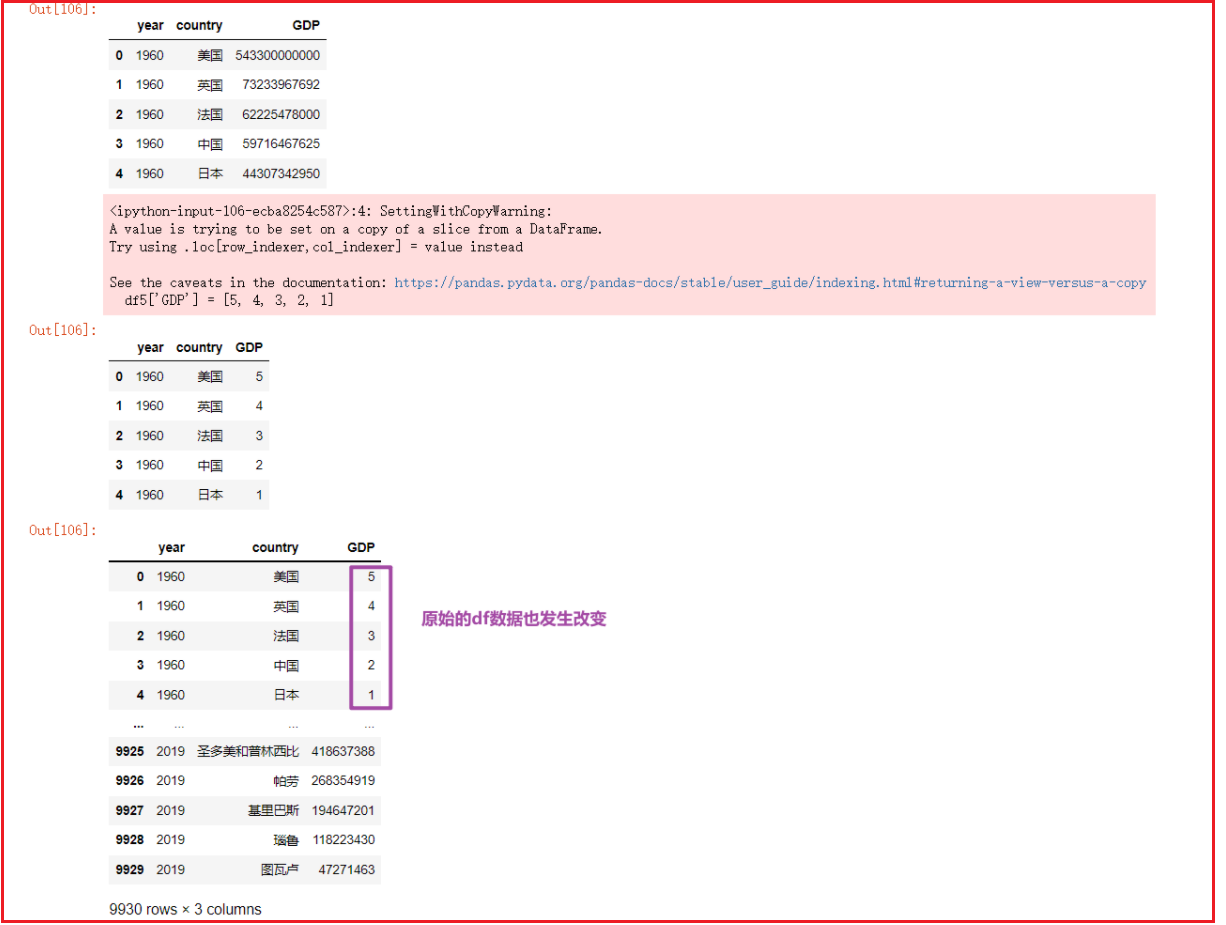
- 3- replace函数替换数据
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )
df6 = df.head()
df6
# series对象替换数据,返回的还是series对象,不会对原来的df造成修改
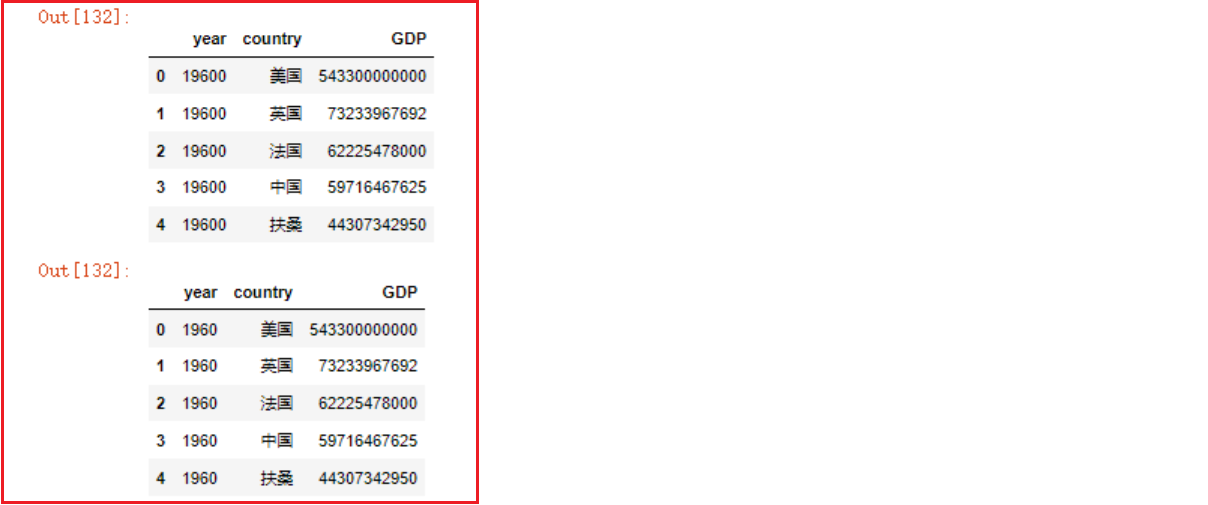
df6.year.replace(1960, 19600)
# 如果加上inplace=True参数,则会修改原始df
df6.country.replace('日本', '扶桑', inplace=True)
df6
# df也可以直接调用replace函数,用法和s.replace用法一致,只是返回的是df对象
df6.replace(1960, 19600)
df6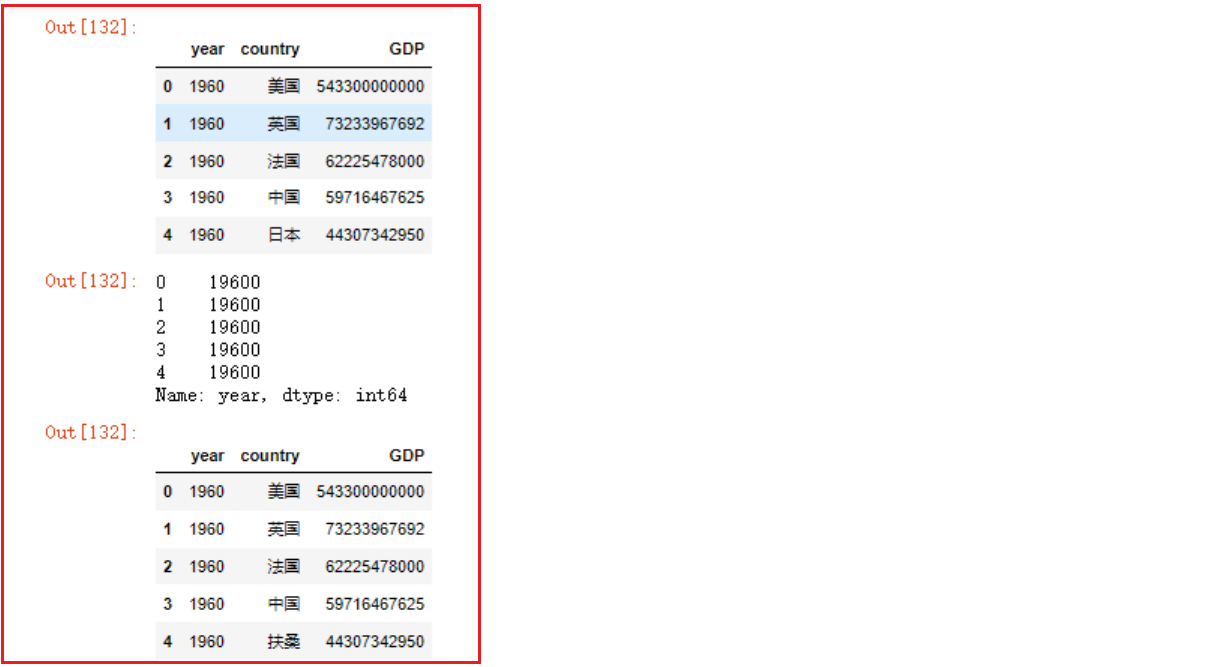
6.4 查询dataFrame中的数据
1- 从前从后取多行数据
- head()
# 导包 import pandas as pd # 加载csv数据,指定gbk编码格式来读取文件,返回df df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk') # 默认取前5行数据 df.head() df.head(10) # 倒数10行- tail()
# 默认取后5行数据 df.tail() df2 = df.tail(15) # 倒数15行 df22- 获取一列或多列数据
- 获取一列数据
df[col_name]等同于df.col_name
df2['country'] df2.country # 注意!如果列名字符串中间有空格的,只能使用df['country']这种形式- 获取多列数据
df[[col_name1,col_name2,...]]
df2[['country', 'GDP']] # 返回新的df- 获取一列数据
3- 索引下标切片取行
df[start:stop:step]:
df[start:stop:step]==df[起始行下标:结束行下标:步长], 遵循左包右闭原则(包含起始行,不包含结束行),步长默认为1
df4 = df.head(10) # 取原df前10行数据作为df4,默认自增索引由0到9
df4[0:3] # 取前3行
df4[:5:2] # 取前5行,步长为2
df4[1::3] # 取第2行到最后所有行,步长为3
4- 查询函数获取子集: df.query()
df.query(判断表达式)可以依据判断表达式返回的符合条件的df子集- 与
df[布尔值向量]效果相同 - 特别注意
df.query()中传入的字符串格式
- 示例:
df3.query('country=="帕劳"') df3[df3['country']=='帕劳']

- 查询中国, 美国 日本 三国 2015年至2019年的数据
df.query('country=="中国" or country=="日本" or country=="美国"').query('year in ["2015", "2016", "2017", "2018", "2019"]')
df.query('(country=="中国" or country=="日本" or country=="美国") and year in ["2015", "2016", "2017", "2018", "2019"]')
5- 排序函数
- sort_values函数: 按照指定的一列或多列的值进行排序
# 按GDP列的数值由小到大进行排序 df2.sort_values(['GDP']) # 按GDP列的数值由大到小进行排序 df2.sort_values(['GDP'], ascending=False) # 倒序, ascending默认为True # 先对year年份进行由小到大排序,再对GDP由小到大排序 df2.sort_values(['year', 'GDP'])- rank函数:
- rank函数用法:
DataFrame.rank()或Series.rank()- rank函数返回值:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
- rank函数包含有6个参数:
- axis:设置沿着哪个轴计算排名(0或者1),默认为0按纵轴计算排名
- numeric_only:是否仅仅计算数字型的columns,默认为False
- na_option :NaN值是否参与排序及如何排序,固定参数:keep top bottom
- keep: NaN值保留原有位置
- top: NaN值全部放在前边
- bottom: NaN值全部放在最后
- ascending:设定升序排还是降序排,默认True升序
- pct:是否以排名的百分比显示排名(所有排名与最大排名的百分比),默认False
- method:排名评分的计算方式,固定值参数,常用固定值如下:
- average : 默认值,排名评分不连续;数值相同的评分一致,都为平均值
- min : 排名评分不连续;数值相同的评分一致,都为最小值
- max : 排名评分不连续;数值相同的评分一致,都为最大值
- dense : 排名评分是连续的;数值相同的评分一致
df2
df2.rank()
df2.rank(axis=0)
df2.rank(numeric_only=True) # 只对数值类型的列进行统计
df2.rank(ascending=False) # 降序
df2.rank(pct=True) # 以最高分作为1,放回百分数形式的评分,pct参数默认为False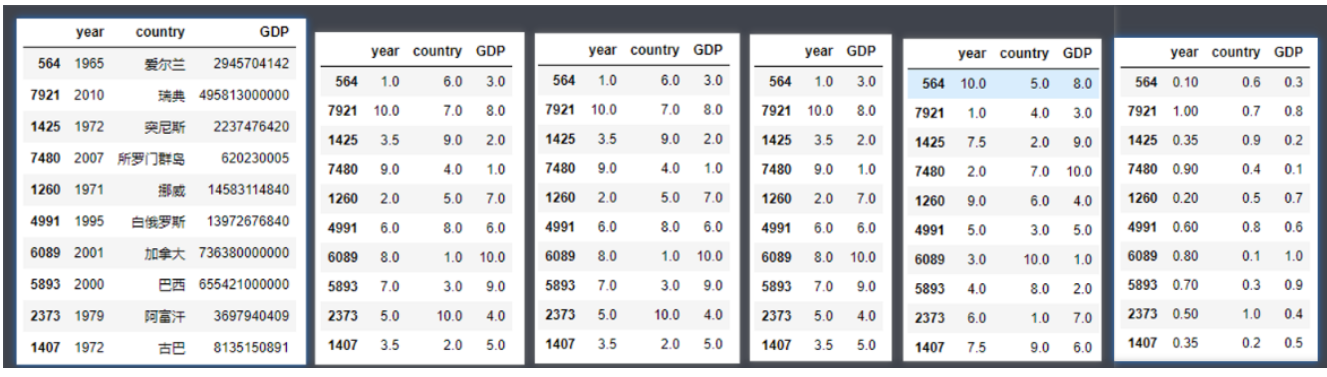
df2.rank(method='average')
df2.rank(method='min')
df2.rank(method='max')
df2.rank(method='dense')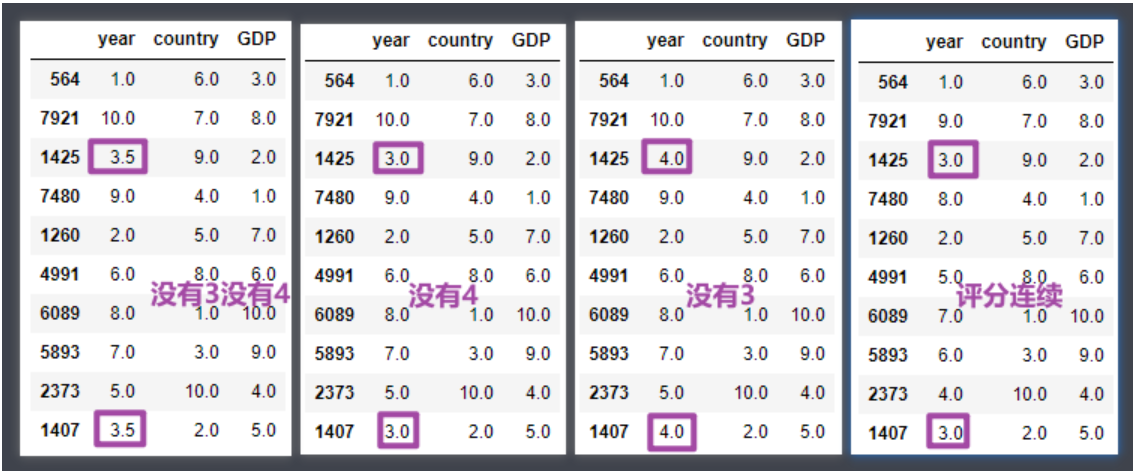
- 6- 聚合函数:
常用聚合函数有:
- min 最小值
- max 最大值
- mean 平均值
- sum 求和
- count 求个数
- min函数
df2.min()
df2['year'].min()- max函数
df2.max()
df2['year'].max()- mean 平均值
df2.mean()
df2['year'].mean()
df2['GDP'].mean()7. DataFrame数据分组操作
数据准备
- 加载优衣库的销售数据集,包含了不同城市优衣库门店的所有产品类别的销售记录,数据字段说明如下
- store_id 门店随机id
- city 城市
- channel 销售渠道 网购自提 门店购买
- gender_group 客户性别 男女
- age_group 客户年龄段
- wkd_ind 购买发生的时间(周末,周间)
- product 产品类别
- customer 客户数量
- revenue 销售金额
- order 订单数量
- quant 购买产品的数量
- unit_cost 成本(制作+运营)
# 导包 加载数据集
import pandas as pd
df = pd.read_csv('../数据集/uniqlo.csv')- 1- df.groupby分组函数返回分组对象
【基于一列进行分组】
# 基于顾客性别分组
gs = df.groupby(['gender_group'])
gs
gs['city']
# 返回结果如下
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001B1DA988B80>
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000001B1DB2B4FA0> 【基于多列进行分组】
# 基于顾客性别、不同城市分组
gs2 = df.groupby(['gender_group', 'city'])
gs2
# 返回结果如下
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001B1DB24F1F0>2- 分组后获取各个组内的数据
- 2.1 取出每组第一条或最后一条数据
gs2 = df.groupby(['gender_group', 'channel']) gs2.first() # 取出每组第一条数据 gs2.last() # 取出每组最后一条数据
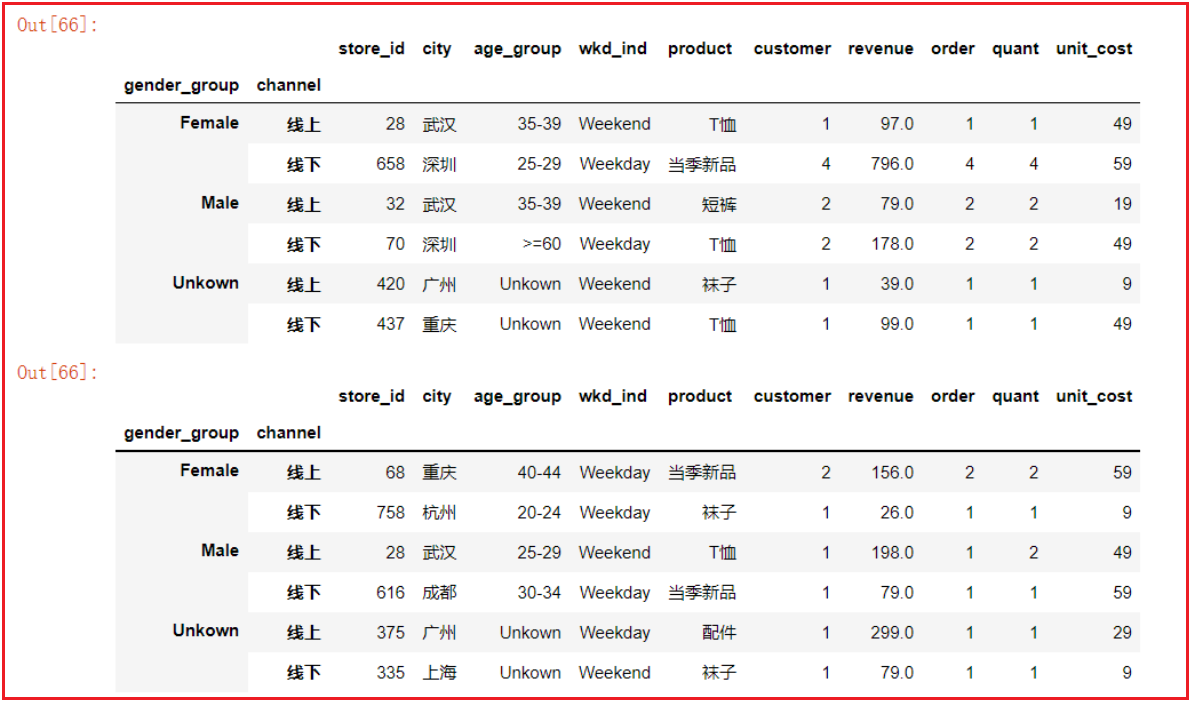
- 2.2 - 按分组依据获取其中一组
gs2.get_group(('Female', '线上'))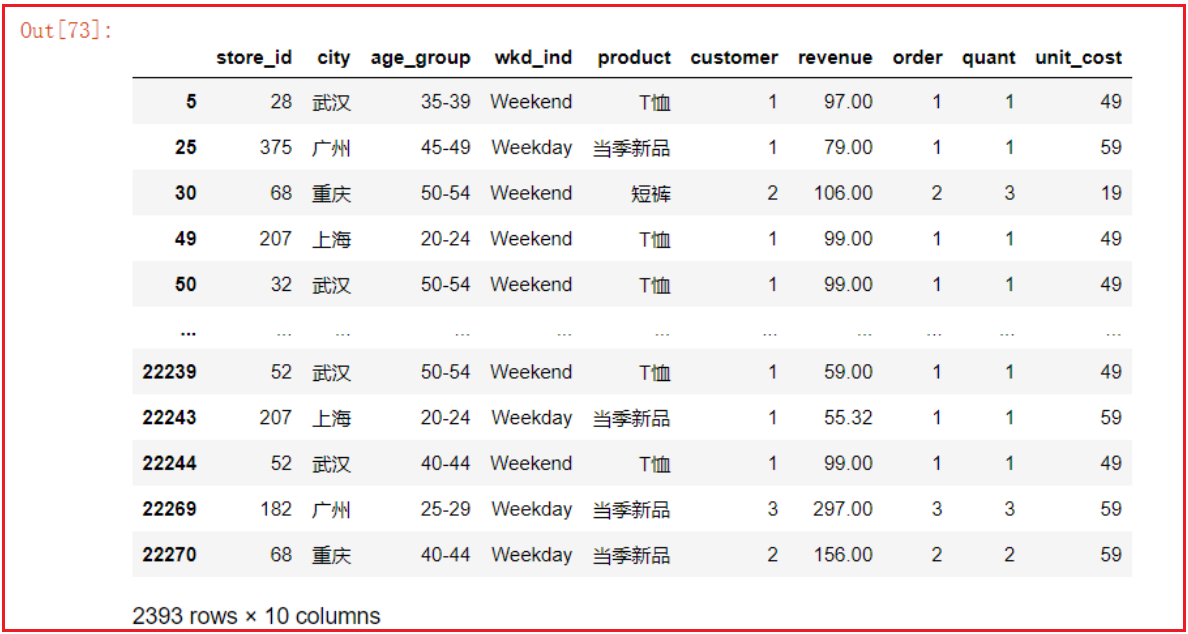
3- 分组聚合
- 格式:分组后对多列分别使用不同的聚合函数
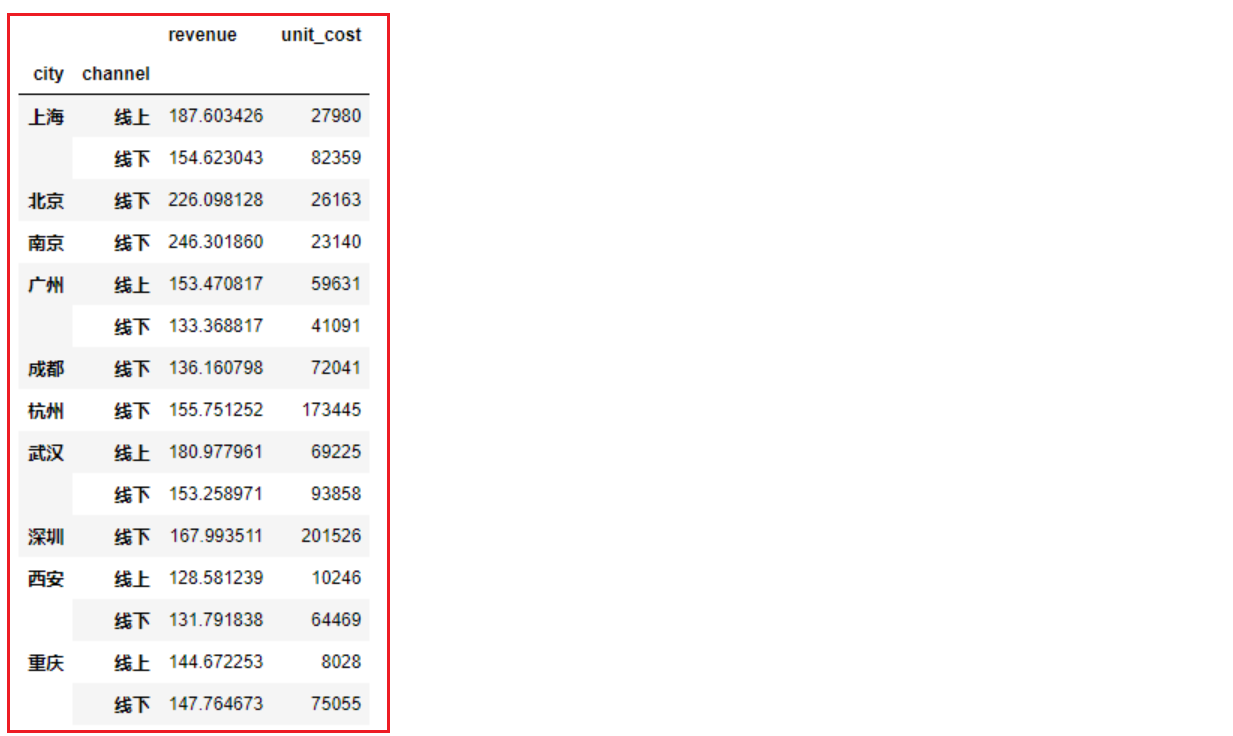
df.groupby(['列名1', '列名2']).agg({ '指定列1':'聚合函数名', '指定列2':'聚合函数名', '指定列3':'聚合函数名' })- 按城市和线上线下划分,分别计算销售金额的平均值、成本的总和
df.groupby(['city', 'channel']).agg({ 'revenue':'mean', 'unit_cost':'sum' })
分组过滤操作
- 格式:
df.groupby(['列名1',...]).filter( lambda x: dosomething returun True or False )
案例: 按城市分组,查询每组销售金额平均值大于200的全部数据
df.groupby(['city']).filter(lambda s: s['revenue'].mean() > 200)
df.groupby(['city'])['revenue'].filter(lambda s: s.mean() > 200)