01:课程回顾
02:课程目标
【模块一:消费分配策略】
03:【掌握】基本规则及分配策略
- 目标:掌握Kafka消费者组中多个消费者的分配规则
- 实施
- 问题
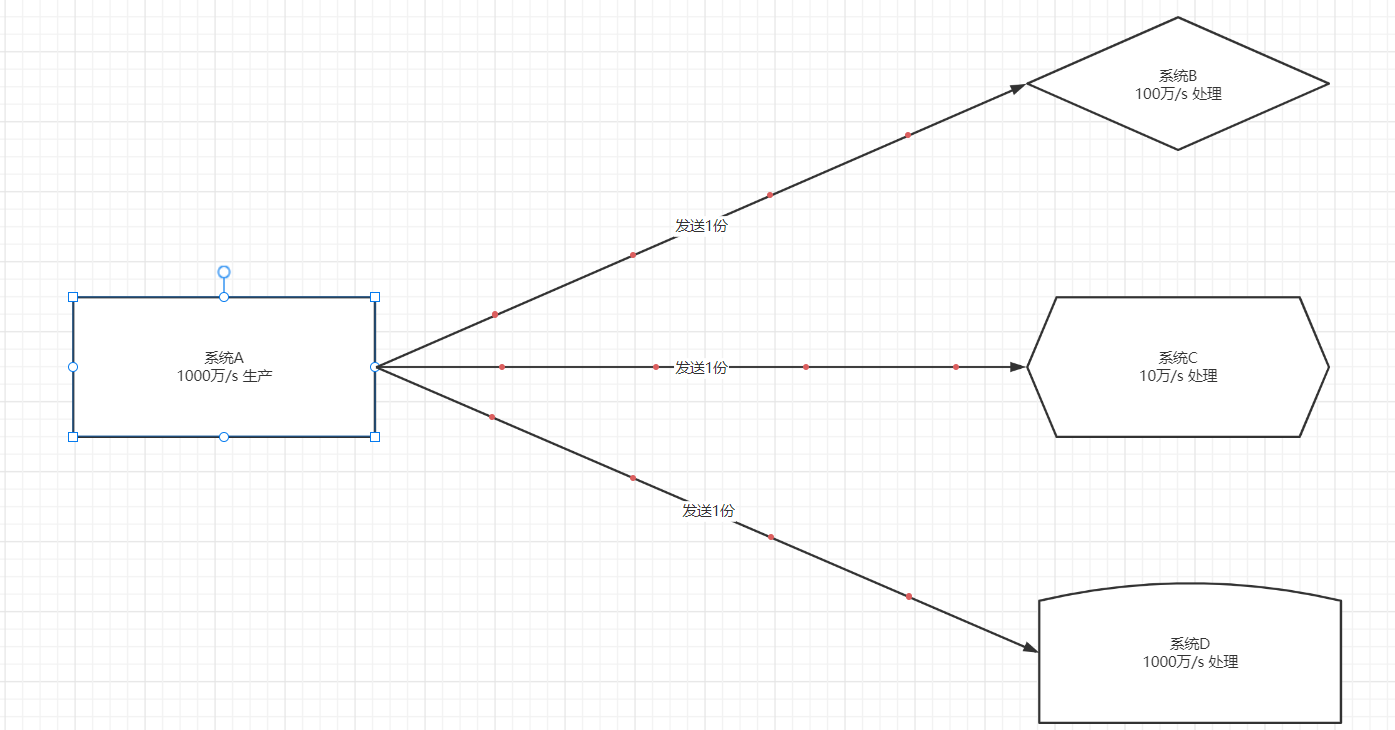
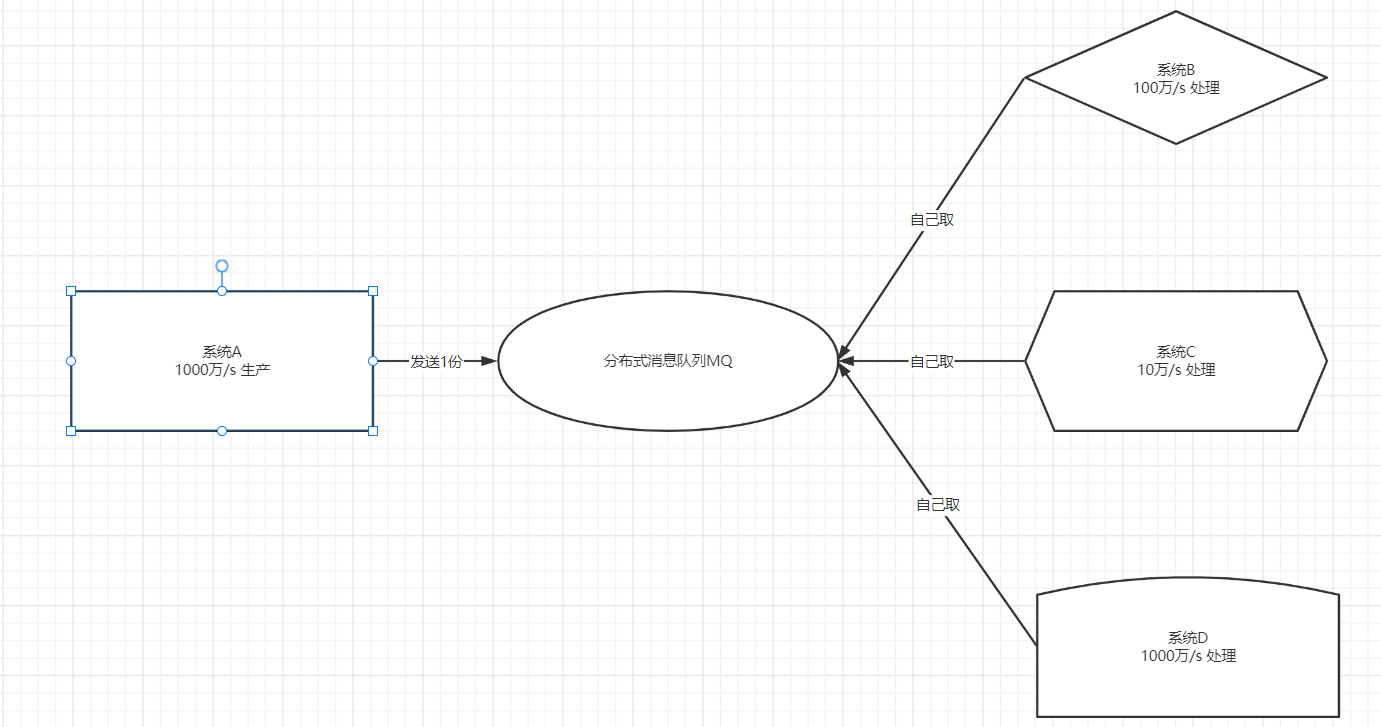
- 1-多个topic多个分区,一个消费者组有多个消费者,Kafka是怎么自动分配保证负载均衡?
- 消费者组:CG1=>多个消费者:C1、C2、C3
- 订阅多个Topic:Topic1 Topic2 Topic3 =>每个Topic都有多个分区
- 2-如果有一个消费者C1故障,超过一定时间没有恢复,这个消费者A原来负责的分区怎么分摊给别的消费者?
- C1故障以后,C1负责的分区,怎么重新分配效率更高?
- 1-多个topic多个分区,一个消费者组有多个消费者,Kafka是怎么自动分配保证负载均衡?
- 基本规则
- 一个分区的数据只能由这个消费者组中的某一个消费者消费
- 一个消费者可以消费多个分区的数据
- 分配策略:决定了多个分区如何分配给多个消费者
- 属性:
partition.assignment.strategy = org.apache.kafka.clients.consumer.RangeAssignor - RangeAssignor:范围分配,默认的分配策略
- RoundRobinAssignor:轮询分配,常见于Kafka2.0之前的版本
- 属性:
- 问题
大约 29 分钟