day08_保险项目课程笔记
今日内容:
- 完成保费因子表计算操作
1. 计算保费相关指标
1.1 计算保费参数因子
- 需求一: 根据性别, 投保年龄, 缴费期 以及保单年度来统计其中23个保费参数因子指标
大约 63 分钟

今日内容:
今日内容:
整个保险产品, 在定价的时候, 并不是一次性成型的, 精算师需要将各种情况全部的考虑进入, 然后核算出一个保费的结果, 然后根据保费结果进行利润测算, 如果没有达到利润目标, 需要重新核算, 直到达到利润目标, 并且还要在市场上有一定的竞争力
今日内容:
Apache DolphinScheduler是一个分布式、去中心化、易扩展的可视化DAG工作流任务调度系统,类似于oozie
官网网站: [https://dolphinscheduler.apache.org/](https://dolphinscheduler.apache.org/)
今日内容:
作用: 对接数据源, 一般会和数据源保持相同的粒度, 数据源中有那些表, 那么我们的ODS层就需要构建有那些表, 与之一一对应
在hive中建表的时候, 需要思考那些点呢?
1- 表选择为内部表还是外部表呢?
判断标准: 表未来存储的数据, 我们是否具有绝对的控制权
项目中:
通过Spark SQL连接HIVE构建表, 由于是自己建表, 自己从数据库导入数据, 所有对数据具有控制权, 此时可以选择构建内部表或者是外部表, 建议构建内部表
2- 表是否需要使用分区表还是分桶表:
分区表: 在HIVE数仓体系中, 对数据量比较大的表, 或者每天都有新增或者更新的数据表, 一般构建的都是分区表
分桶表: 当需要对表数据进行采样操作的时候, 或者说每一天中数据量依然是非常庞大的,或者说每个分区下的数据依然也是非常庞大的, 为了能够进一步提升查询的性能, 可以选择构建分桶表
项目中:
除了投保信息表 客户信息表 理赔信息表 退保信息表比较庞大以外, 需要构建分区表, 其他的表主要都是一些配置型的表 数据体量不是特别的大, 可以不用构建分区表, 对于配置型表 后续可以直接选择覆盖处理即可, 这些表一般都不需要维护历史变化
而分桶表, 后续也不需要采样而且基于Spark SQL来处理 也不需要处理, 并不构建
在学习环境中, 为了方便一些, 后续会全部构建普通表
3- 表需要使用那种存储格式 以及压缩方案
ODS层: 一般来说都是TextFile 或者 ORC
说明: 如果后续构建表, 然后数据直接从HDFS上加载普通的文本文件数据, 此时一般构建为TextFile (load 加载, 此方式仅支持textFile), 以及通过 sqoop采集选择的是原生导入行为的, 一般构建textFile
如果能支持ORC导入, 一般建议构建为ORC格式
其他层次: 一般选择为ORC
项目中: 所有的层次都是基于ORC格式来存储, 对于ODS层, 基于sqoop的hcatalog模式来导入的
学习环境中: 所有层次都采用textFile, 对于ODS层, 由于sqoop使用apache原生版本测试, 导致对hcatalog支持不良好, 仅能使用原生方式导入, 在项目中不存在 因为是基于CDH版本 可以直接使用hcatalog模式
压缩方案: 数仓体系中, 一般我们选择主要是以SNAPPY为主, 对于ODS层这样数据量比较庞大的基础层, 可以选用 zlib/GZ这种可以压缩的更小的压缩方案
4- 对于表的字段的选择:
ODS层: 一般会和数据源的表保持相同的粒度 原有表有那些字段, 那么我们在ODS层建表中也有那些字段, 如果分区表,在此基础上添加分区字段即可, 分区字段一般以采集的周期为准
其他层次的建表: 没有固定方案, 主要参考当前计算的维度 和 指标来构建表, 以能够存储结果数据为准则来建表
今日内容:
存储数据的仓库, 主要是用于存储过去历史发生过的数据, 基于主题对数据进行分析操作, 通过对过去历史数据的分析,从而能够对未来提供决策支持
项目名称: 富华阳光人寿保险项目
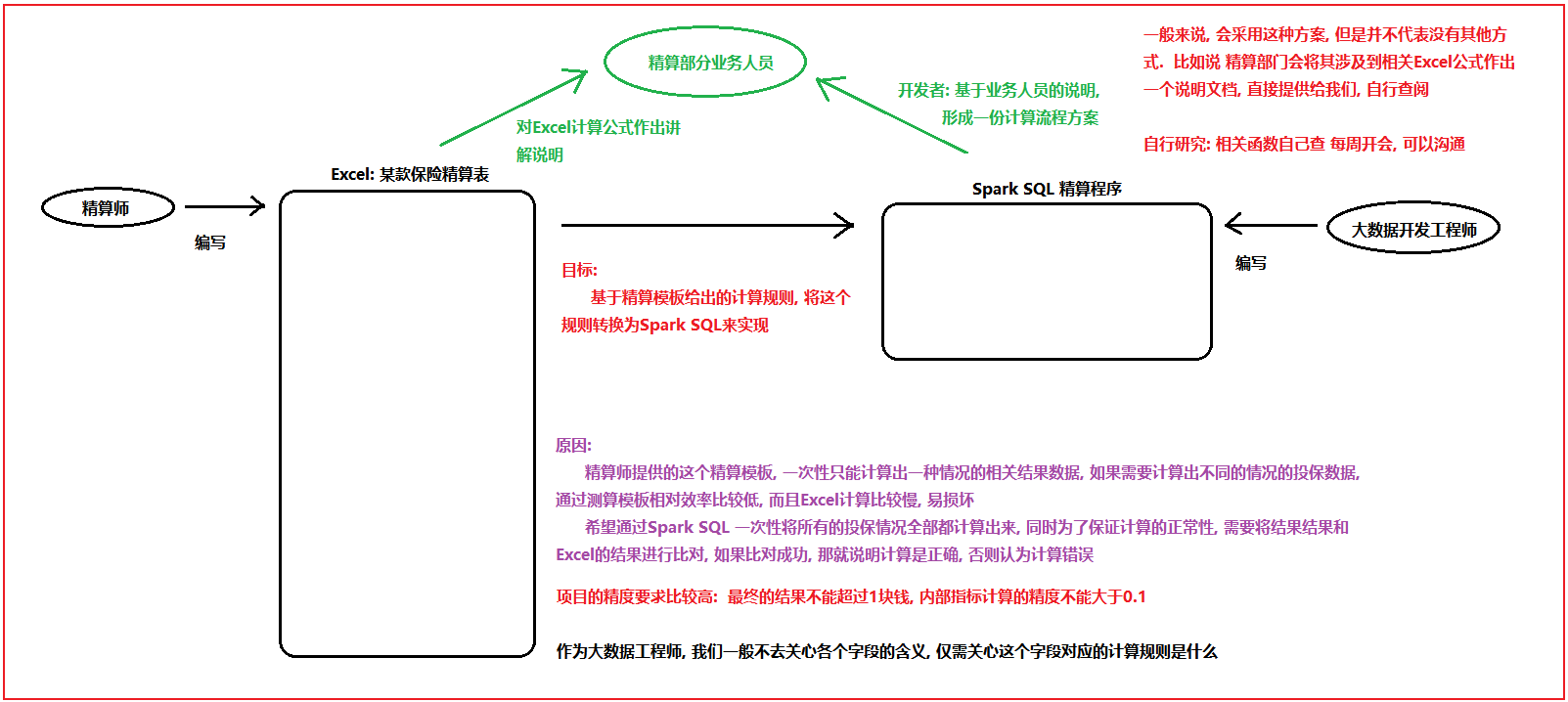
整个保险行业中, 最为核心的技术就是精算, 精算简单来说就是根据不同年龄以及保额来计算需要收取多少保费的问题, 精算出现改变了从早期通过经验判断的方案来确定保费的阶段, 让保险行业更加专业化, 精确化
精算行业并不仅仅解决保费的问题,包含有: 确定保险费率、应付意外损失的准备金、自留限额、未到期责任准备金和未决赔款准备金等方面,都力求采用更精确的方式取代以前的经验判断
保险精算学主要研究事故的出险规律、损失的分布规律、保费的厘定、保险产品的设计、准备金的提取、偿付能力等保险具体问题。