
新零售项目介绍
资料
Day01_项目需求与技术架构
知识点01:课程内容大纲与学习目标
#课程内容大纲
大数据业务需求
企业中为什么开展大数据项目,为什么招人从事大数据开发
新零售项目背景
新零售的说法是什么意思
新零售项目业务流程
新零售项目业务需求
项目分析什么
大数据处理流程、技术选型、平台架构
一切围绕数据流转
常用软件功能介绍
大数据平台架构:Lambda、kappa
新零售项目架构
传统离线数仓架构 重要在于数仓的设计
“一招鲜,吃遍天”
大数据平台搭建方式
Cloudera Manager(CM)、CDH介绍
商业版大数据软件
新零售项目环境搭建
CM虚拟机导入
#学习目标
了解项目相关背景、业务流程、需求
(重点)掌握大数据处理流程、技术选型、平台架构
(重点)掌握理解新零售项目架构
了解大数据平台搭建方式
了解CM、CDH是什么
(重点)能够搭建使用项目的虚拟机环境知识点02:大数据业务需求
- 需求本质 通过对相关数据的处理和分析,提取隐藏在数据中的价值,为公司赚更多的钱。 这也是公司为什么愿意花钱招人、买装备投入大数据的核心原因。
- 数据分析
对公司中的业务数据进行分析处理,根据业务需求计算出各种指标,实现运营支撑。
赚取的实现途径:买卖产品或服务。
#1、需要更多新客户
方式:推广拉新
指标:广告播放量、点击量、注册量、推广渠道成本占比、转化比等
#2、让新用户消费
方式:优惠券、现金券等优惠活动(首单优惠30%、满100减20)
指标:登录次数、收藏次数、加入购物车次数、首单转化率
推荐系统:基于对用户数据的分析,构建用户画像,精准把握用户需求,实现精准推荐。
#兴趣爱好:颜色、品牌、价格区间、之前购买信息、当前搜索浏览信息
#3、让老用户留存
方式:解决用户痛点、迎合用户兴趣点
指标:退款次数、好评数、差评数、留存率、不同终端成交占比
#4、降低运营成本
指标:销售收入、成交额、退款额,再细分为不同维度不同粒度(不同渠道、不同终端、不同地区、不同日期)
风控系统:安全领域、金融领域
#统计分析一个恶意访问,拦截和屏蔽恶意访问
#信用风控知识点03:新零售背景
零售(Retailing):直接将商品或服务销售给个人消费者或最终消费者的商业活动。
随着经济和技术的发展,经历了多种不同形式的发展。
- 地摊、卖货郎
- 百货商店
- 超级市场
- 连锁商店
- 电子商务
- 新零售
线上服务、线下体验以及现代物流进行深度融合的零售新模式新零售分析的意义
1:企业在早期发展阶段,主要面对的是公司的存活问题和日常正常经营问题,对大数据分析的需求比较弱
2:当企业发展到一定阶段,则需要使用新的大数据分析平台对公司的历史数据进行统一的整合分析,从这些数据中发掘有价值的东西,为企业的未来提供科学的支撑,为决策者提供科学的决策支持
------------面试问题:介绍下你做的项目,这个可以作为开篇-------------------
3:本项目基于新零售的大数据分析,通过分析可以提高履单效率、减少运营成本、提高客户体验度,实现库存优化和增加营收的目标知识点04:新零售业务流程1(商品上架、单店铺订单)
- 商品上架
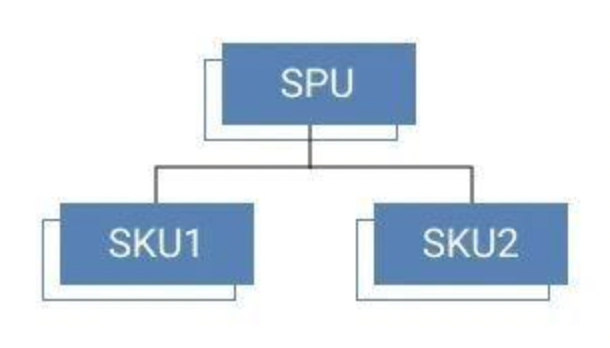
==SPU==(Standard Product Unit):标准化产品单元。是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。
==SKU==(Stock Keeping Unit):库存量单位。可以是以件、盒、托盘等为单位。SKU是物理上不可分割的最小存货单元。
举个栗子:
SPU:是拿来给用户购买商品==查询==的,比如: iPhone X。SPU只是代表型号,与规格,颜色和款式无关;
SKU:是用户点击进来展示的,==加上颜色,尺寸等属性==。一部手机一个SKU,如iPhone X 土豪金 64G 和 iPhone X 土豪金 128G的SKU是不同的。
SPU:iPhone X
SKU:土豪金 64G的iPhone X
你听到SPU就知道是哪个品牌的哪款机型手机
你听到SKU就知道是哪个品牌的哪款机型的什么配置的手机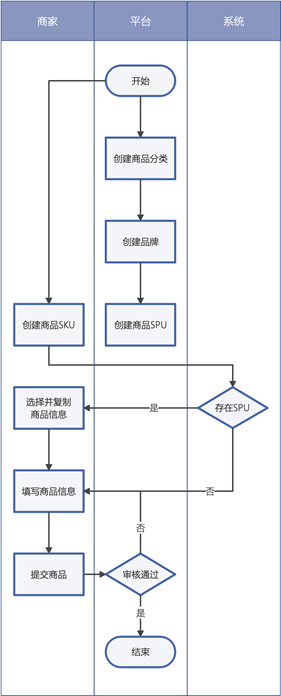
- 单店铺订单
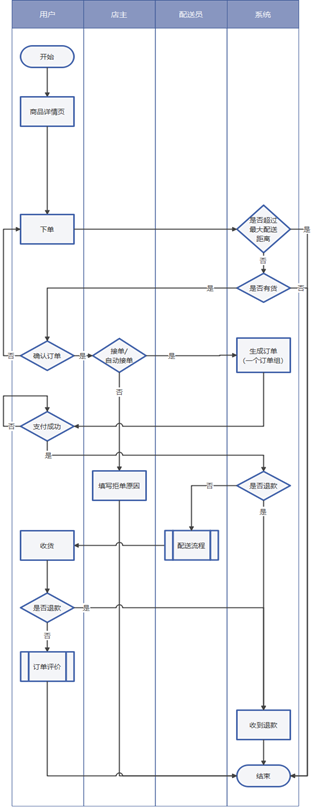
1、用户在商品详情页直接下单;
2、校验订单,是否超出最大配送距离、商品是否有货等;
3、用户确认订单,商家手动接单或自动接单;如果拒绝接单,填写拒单原因后订单结束;
4、系统生成订单:一个订单组下包含多个订单;
5、用户进行支付,支付失败则重新发起支付;
6、进入配送流程之前,先判断是否已发起退款,如申请退款则进入退款流程,否则进入配送流程;
7、当配送员送达订单时,配送流程结束。在用户确认收货时,如发现包裹(损坏、漏发、不想要)可申请退款,并交
8、由系统确认并直接退款;否则用户进行确认收货,对配送服务和商品进行评价,订单结束知识点05:新零售业务流程2(购物车订单、配送)

- 购物车订单
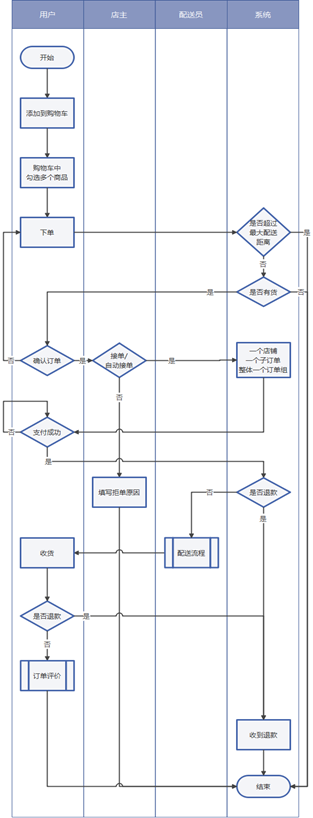
1、用户将多个店铺的商品添加到购物车后,在购物车下单;
2、校验订单,是否超出最大配送距离、商品是否有货等;
3、用户确认订单,商家手动接单或自动接单;如果拒绝接单,填写拒单原因后订单结束;
4、系统生成订单组:为了方便订单的优惠规则和配送费计算,一个店铺的商品生成一个子订单,多个子订单组成一个订单组;
5、用户进行支付,支付失败则重新发起支付;
6、进入配送流程之前,先判断是否已发起退款,如申请退款则进入退款流程,否则进入配送流程;
7、当配送员送达订单时,配送流程结束。在用户确认收货时,如发现包裹(损坏、漏发、不想要)可申请退款,并交由系统确认并直接退款;否则用户进行确认收货,对配送服务和商品进行评价,订单结束。- 配送
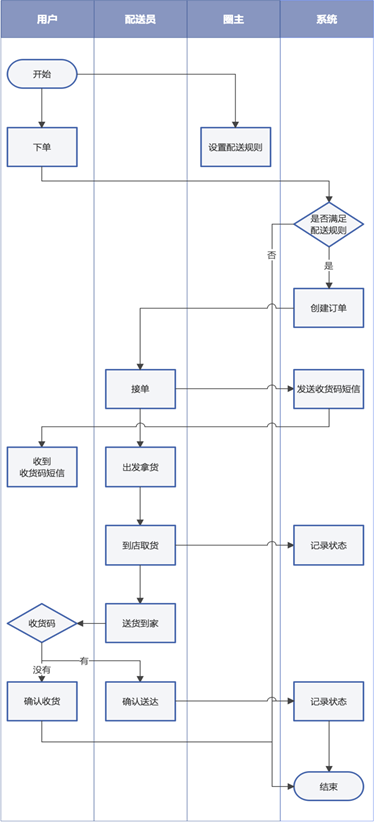
1、商圈圈主设定配送规则(平台审核):最低配送费用、每公里增加配送费用、最大配送距离等;
2、用户下单,系统判定是否满足最大配送距离,不满足则下单失败;
3、配送员接单,系统发送收货码给用户;
4、配送员到店取货,系统记录状态;
5、配送员送货到家,索取用户的收货码,并确认送达;或由客户主动完成订单;
6、订单结束。知识点06:新零售业务流程3(退款退货)
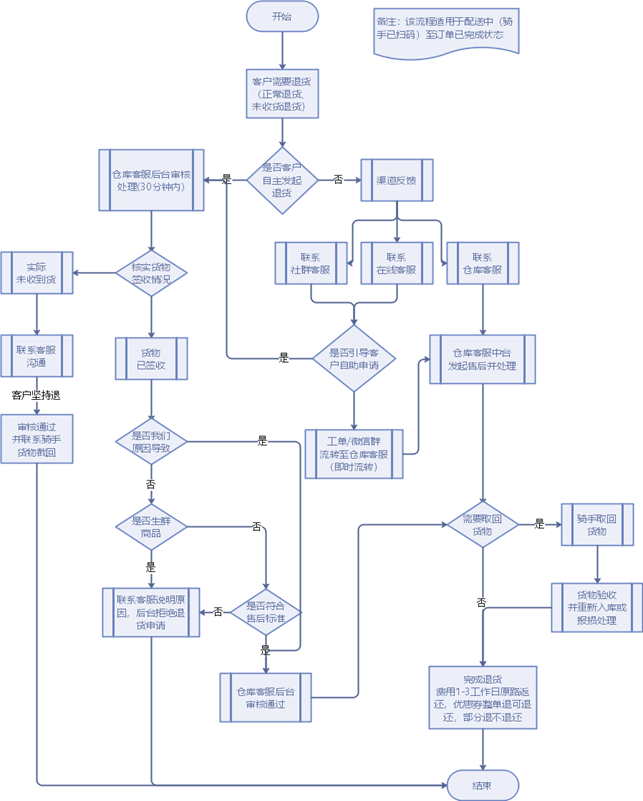
1、客户下单后且已处于配送中
2、如果用户因未收到货或正常退货原因而主动发起退货申请则交给仓库审核实际签收情况,如果是已签收申请退货,则判断是否因为卖方原因导致(是生鲜则拒绝退款,非生鲜时判断是否符合售后标准,不符合拒绝退款,符合售后标准时审核通过,判断是否取回货物,如果已取回则完成退货,如未取回则由骑手取回并验收重新入库已完成退货);如果未收到货则联系客户(重新发),此时客户坚持退款,则由仓库联系骑手截回货物再完成退货
3、如果非用户主动取消订单则交给渠道,并由渠道反映到客服(社群、400客服和仓客服),如果是社群客服和400客服时则引导用户自助取消订单,成功引导客户自助取消订单时(按照第2步流程走),否则由智齿工单或微缩群实时提交到仓客服,然后仓客服则通过中台系统来发起售后,并判断是否已取回货物,如未取回则联系骑手取回并验货重新入库已完成退货知识点07:新零售原始数据
- 概念
原始数据:指的就是业务数据,原始这个说法是相对大数据应用而言的,该项目的业务数据主要来自MySQL
原始数据按照子系统划分:订单模块、支付模块、店铺模块、商品模块、用户模块、系统配置模块、广告模块、促销模块和配送模块等,该项目重点给大家分析:订单模块、商品模块、用户模块、支付模块
首先面临的问题是:
业务系统的开展会源源不断产生很多业务数据,存储在哪里? MySQL中
什么样的系统适合存储业务数据? 关系型数据库(RDBMS: MySQL、Oracle、SQLServer,DB2、SQlite)
支撑业务的顺利开展? RDBMS主要是靠事务来保证业务的安全性- 存储问题
操作型处理: 联机事务处理OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对数据库就是增删改查。
在OLTP系统中,用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。
传统的关系型数据库系统(RDBMS)作为数据管理的主要手段,主要用于操作型处理。
RDBMS其实就是OLTP
 OLTP系统可以直接开展数据分析吗?可以,但是没必要。
OLTP系统可以直接开展数据分析吗?可以,但是没必要。
1、OLTP系统的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作,一般来说读的压力明显大于写的压力。 2、如果在OLTP环境直接开展各种分析,有以下问题需要考虑: 数据分析也是对数据进行读取操作,会让读取压力倍增; OLTP仅存储数周或数月的数据; 数据分散在不同系统不同表中,字段类型属性不统一;
- 相关表信息
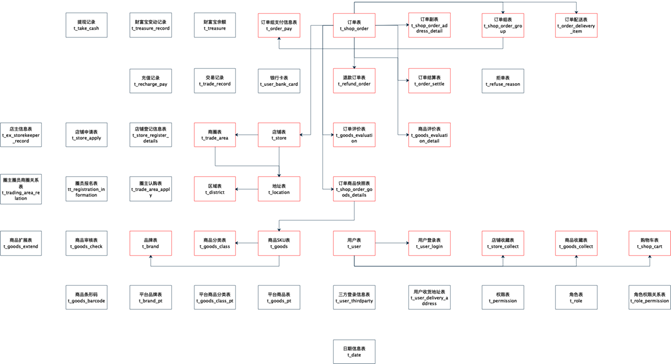
业务系统最大特点:表很多,表关系很复杂。可以根据主题相关性进行梳理。
- 订单相关

- 店铺相关

- 商品相关

- 用户、配置相关

知识点08:新零售项目业务需求
- 研发阶段
第一阶段
目标
1.完成10个hadoop集群节点的搭建工作
2.完成调度平台的搭建工作
3.完成基础数据迁移 mysql--> Hadoop平台
4.完成:销售模块的数据建模
5.能够满足业务对于基础销售的需求
资源
1.人员
项目经理一名
数据开发工程师三名
数据分析师2名
2.时间
3个月
-----------------------------------------------------------------------------------
第二阶段
目标
1.完成32个hadoop节点的扩容工作
2.完成相应内存计算平台presto集群的搭建
3.完成整个源系统的数据抽取工作
4.完成:销售模块、用户模块、商品模块、促销模块数据建模工作
5.满足公司日常运营的80%的数据需求和报表需求
6.支撑财务的成本和利润的核算
7.完成准实时数据的数据应用开发工作
资源
1.人员
项目经理一名
数据开发工程师四名
数据分析师3名
2.时间
4个月
课程中主要讲解销售、商品和用户三个模块。- 主题报表需求 面试问题:你的项目涉及到哪些主题:
- 销售主题
可分析的主要指标有:销售收入、平台收入、配送成交额、小程序成交额、安卓APP成交额、苹果APP成交额、PC商城成交额、订单量、参评单量、差评单量、配送单量、退款单量、小程序订单量、安卓APP订单量、苹果APP订单量、PC商城订单量。
维度有:日期、城市、商圈、店铺、品牌、大类、中类、小类。
指标 维度
select count(字段1),sum(字段2),avg(字段3) from A表 group by 字段1,字段2
select count(订单id),sum(销售额),avg(商品价格) from A表 group by 日期,城市- 商品主题
主要指标有:下单次数、下单件数、下单金额、被支付次数、被支付金额、被退款次数、被退款件数、被退款金额、被加入购物车次数、被加入购物车件数、被收藏次数、好评数、中评数、差评数。
维度有:商品、日期。- 用户主题
主要指标有:登录次数、收藏店铺数、收藏商品数、加入购物车次数、加入购物车金额、下单次数、下单金额、支付次数、支付金额。
维度有:用户、日期。- 数据与集群规模(面试问)
性能指标
对于报表展现的内容刷新,页面数据的请求到展现的过程总体时间不能超过5秒。
数据量
1 全量
经过4年左右的业务发展,整个数据平台的数据为35T左右,冗余存储量为105T。
2 增量
每日增量25G左右。
集群规模
40台服务器
操作系统 CentOS 7.5 x86 74
软件版本
java 1.8
hadoop 3.0.0+cdh6.2.1
hdfs 3.0.0+cdh6.2.1
Hive 2.1.1+cdh6.2.1
yarn 3.0.0+cdh6.2.1
zookeeper 3.4.5-cdh6.2.1
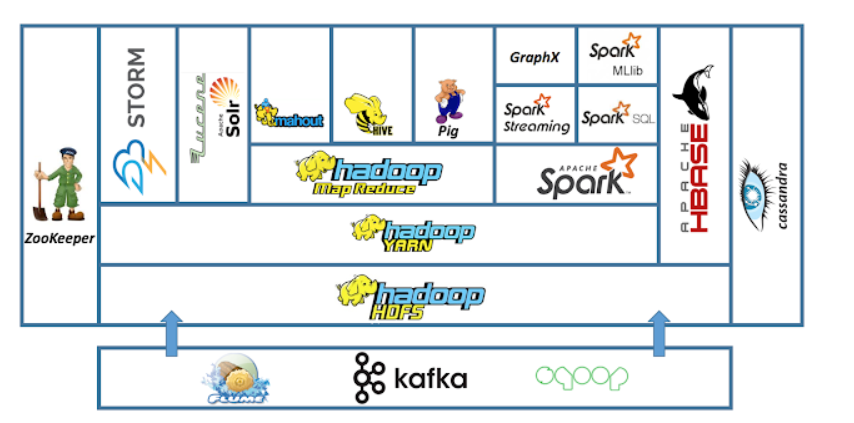
presto 0.245.1知识点09:大数据处理流程
大数据开发方向:
大数据离线分析,分析历史数据 -----》Hadoop、Hive、Sqoop、Spark
大数据实时分析,分析正在发生的数据 -----》Spark Streaming、Kafka、HBase、Flink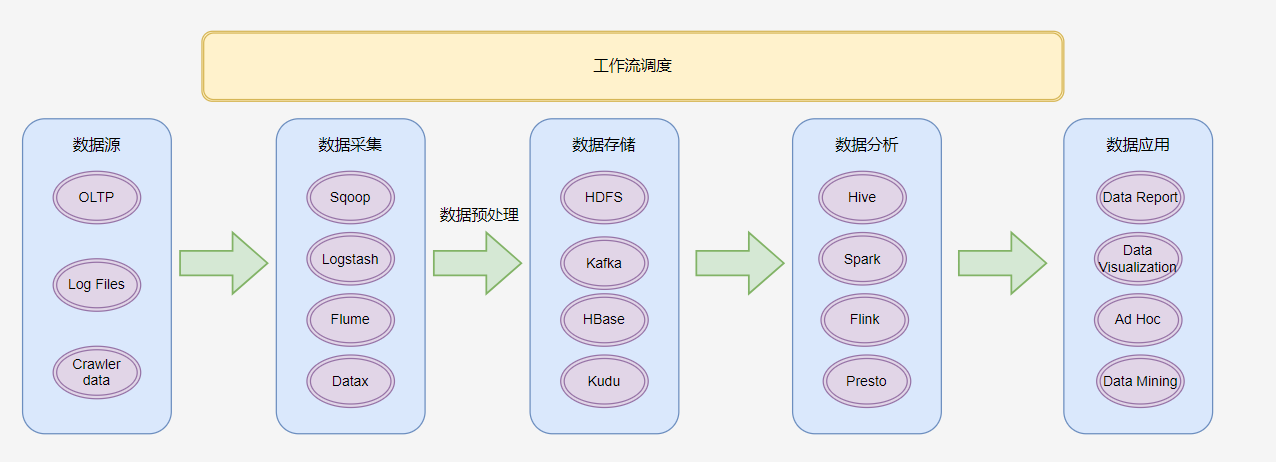
- 数据源
需要大家掌握,当下企业中,可供开展数据分析的数据到底有哪些种类,来自于哪里。
- 数据采集
关于具体含义要结合语境具体分析,明白语境中具体含义即可。
- 数据存储
大数据应用下,几乎都是分布式存储软件。
多台机器共同存储,分区机制、副本机制是核心的概念。
- 数据分析
数据分析是指用适当的分析方法及工具,对处理过的数据进行分析,提取有价值的信息,形成有效结论的过程。
由于数据分析多是通过软件来完成的,这就要求数据分析师不仅要掌握各种数据分析方法,还要熟悉数据分析软件的操作。- 数据应用
Data Report:数据报表,用表格、图型等格式来动态显示数据。
Data Visualization:数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。
Ad Hoc:即席查询。是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
Data Mining:数据挖掘。是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。- 工作流调度

指业务过程的部分或整体在计算机应用环境下的自动化。
是对工作流程及其各操作步骤之间业务规则的抽象、概括描述。
关键字:周期性执行 重复性执行知识点08:大数据常用技术选型

一、数据采集
Flume:实时数据流采集
Sqoop:离线数据库采集
Logstash:全场景数据采集工具
Datax:离线数据库采集
Canal:实时数据库采集
二、数据存储
Zookeeper:分布式协调服务,本质依旧是一个存储系统,只能存储少量数据。本职工作还是协调服务。
HDFS:分布式文件系统,以文件的方式来管理数据
Hive:数据仓库,将结构化数据文件映射成为表,提供类SQL查询分析功能。
Redis:纯内存式的KV结构的NoSQL数据库
Hbase:基于Hadoop的一个按列存储的NoSQL数据库
Kafka:分布式实时消息队列(MQ)
ElasticSearch:全文检索引擎
MySQL:关系型业务数据库
三、数据分析
MapReduce:离线批处理系统,第一代计算引擎
Hive:基于SQL的MapReduce/Tez/Spark引擎
Spark:分布式技术栈
Core:类似于MapReduce
SQL:类似于Hive
Streaming:流式实时计算
Structured Streaming 结构化流 实时计算
Flink:实时计算工具
Impala、Presto、Kylin:OLAP分析工具 查询速度快
四、其他工具
统一可视化终端UI:Hue
集群管理维护:Cloudera Manager、Ambari
任务流调度:Oozie、Azkaban、AirFlow
元数据管理:Atlas知识点09:当前行业的大数据平台架构
- Lambda架构:离线和实时是两套架构
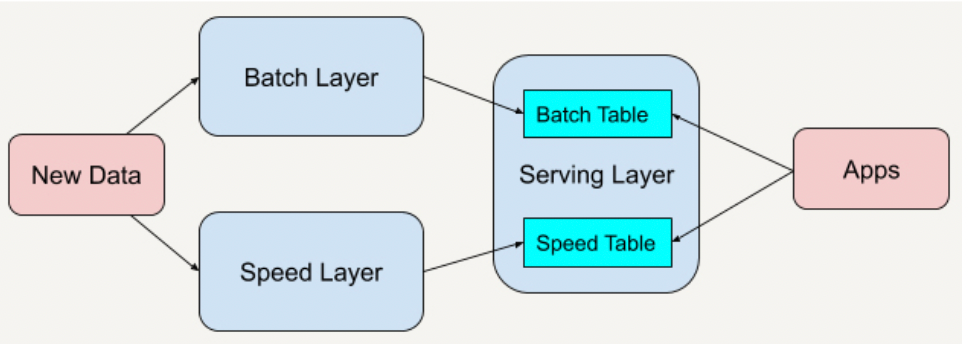
Lambda 架构(Lambda Architecture)是由 Twitter(推特)工程师南森·马茨(Nathan Marz)提出的大数据处理架构。这一架构的提出基于马茨在 BackType 和 Twitter 上的分布式数据处理系统的经验。
Lambda架构总共由三层系统组成:
批处理层(Batch Layer)
速度处理层(Speed Layer)
用于响应查询的服务层(Serving Layer)
=批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的,用于离线分析
拿到已经发生过数据,对数据的多少有提前的预知,不能对数据进行修改
=速度处理层会实时处理新来的大数据。速度层通过提供最新数据的实时视图来最小化延迟,用于实时分析
处理的是还没有发生和即将发生的数据,未来的数据什么样子及数据量有多少没有提前的预知,不能对数据进行修改
=所有在批处理层和速度层处理完的结果都输出存储在服务层中,服务层通过返回预先计算的数据视图或从速度层处理构建好数据视图来响应查询,批处理层和速度层分析后的结果可以存放在访问速度非常快的系统中,用于同一的查询和应用
虽然 Lambda 架构使用起来十分灵活,并且可以适用于很多的应用场景,但在实际应用的时候,Lambda 架构也存在着一些不足,主要表现在它的维护很复杂。
使用Lambda架构时,架构师需要维护两个复杂的分布式系统,并且保证他们逻辑上产生相同的结果输出到服务层中。- Kappa架构:流批一体架构
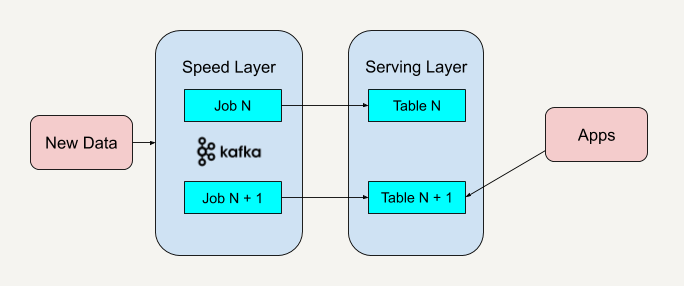
Kappa 架构是由 LinkedIn(领英) 的前首席工程师杰伊·克雷普斯(Jay Kreps)提出的一种架构思想。克雷普斯是几个著名开源项目(包括 Apache Kafka 和 Apache Samza 这样的流处理系统)的作者之一,也是现在 Confluent 大数据公司的 CEO。
Kappa 架构去掉了批处理层这一体系结构,而只保留了速度层。你只需要在业务逻辑改变又或者是代码更改的时候进行数据的重新处理。
因为 Kappa 架构只保留了速度层而缺少批处理层,在速度层上处理大规模数据可能会数据丢失的的情况发生,这就需要我们花费更多的时间在处理这些错误异常上面。知识点10:新零售项目架构
数据源:业务系统的Mysql数据库
数据抽取:使用Sqoop实现关系型数据库和大数据集群的双向同步
数据存储:HDFS
计算引擎:Hive、Presto
数据同步:Sqoop
工作流调度:Oozie几乎所有的大数据离线项目都是这一套数仓架构。核心就是数仓搭建、分层与模型。
知识点11:大数据平台搭建方式
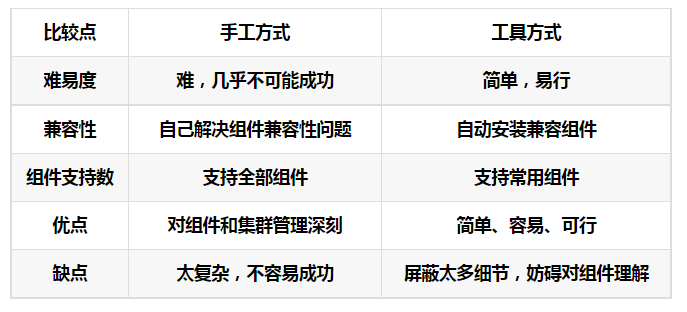
- 手动部署
优点
灵活性和安全性、自定义的程度最高
缺点
如果集群的机器比较多,安装和管理就比较麻烦
如果有一台的配置改变了,其他的都要手动同步
版本之间的兼容性问题考虑十分棘手 木桶短板效应
要求运维人员精通计算机底层和大数据应用- 集群管理工具部署
优点
由管理工具来实现批量化的同步操作:安装、配置 可以通过鼠标直接点击操作就可以完成配置
有监控管理:进程监控、资源监控
可以所有程序管理:不需要命令行,通过可视化界面来管理所有服务
缺点
Cloudera Manager:对很多非Cloudera公司的产品不兼容 大规模商业部署收费,本课程使用的就是CM
Ambari:Bug比较多,兼容性较差知识点12:Cloudera Manager介绍
https://www.cloudera.com/products/product-components/cloudera-manager.html
- 介绍
Cloudera Manager(简称CM)是Cloudera公司开发的一款大数据集群安装部署利器.
这款利器具有集群自动化安装、中心化管理、集群监控、报警等功能,使得安装集群从几天的时间缩短在几小时以内,运维人员从数十人降低到几人以内,极大的提高集群管理的效率。
cloudera manager有四大功能:
(1)管理:对集群进行管理,如添加、删除节点等操作。
(2)监控:监控集群的健康情况,对设置的各种指标和系统运行情况进行全面监控。
(3)诊断:对集群出现的问题进行诊断,对出现的问题给出建议解决方案。
(4)集成:对hadoop的多组件进行整合。- CM架构
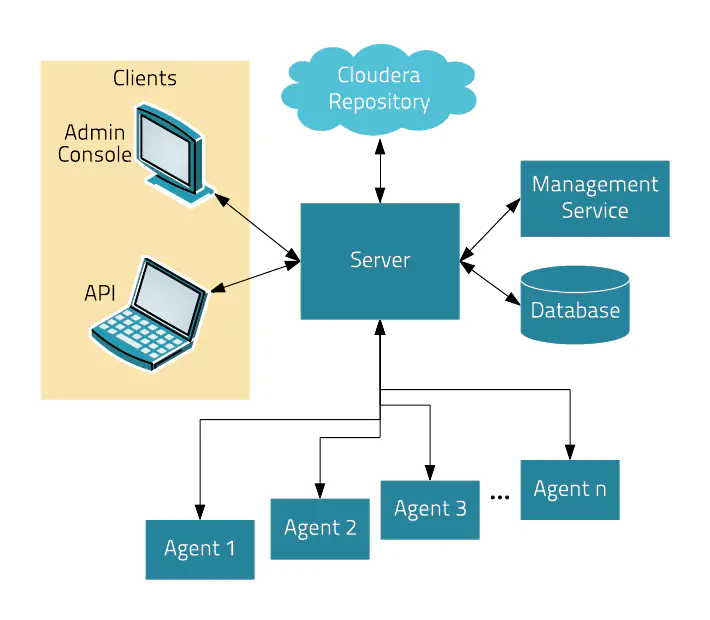
Server:Cloudera Manager的核心是Cloudera Manager Server。提供了统一的UI和API方便用户和集群上的CDH以及其它服务进行交互,能够安装配置CDH和其相关的服务软件,启动停止服务,维护集群中各个节点服务器以及上面运行的进程。
Agent:安装在每台主机上的代理服务。它负责启动和停止进程,解压缩配置,触发安装和监控主机
Management Service:执行各种监控、报警和报告功能的一组角色的服务
Database:CM自身使用的数据库,存储配置和监控信息
Cloudera Repository:云端存储库,提供可供Cloudera Manager分配的软件
Client:用于与服务器进行交互的接口,包含Admin Console和API
(1) Admin Console:管理员可视化控制台
(2) API:开发人员使用API可以创建自定义的Cloudera Manager应用程序课程附属资料中,提供了详细的从零开始安装CM集群以及在CM集群上搭建CDH环境。可供搭建参考。
知识点13:项目CM环境搭建(虚拟机导入)
详细图文步骤可以参考项目讲义。
虚拟机账户密码:root 123456
- 设置VMware虚拟机网络
课程提供的2台项目虚拟机采用的是vmnet8 NAT模式搭建
网段: 192.168.88.0/24
网关: 192.168.88.2- 设置windows本机虚拟网络配置(可选)
保证windows上的vmnet8虚拟网卡也是出于88网段。否则笔记本访问不了虚拟机。
- 虚拟机CPU、内存分配
如果两台虚拟机的CPU和内存总配置,已经超出了windows硬件的上限,要进行适当的调低,以避免windows蓝屏。
- CPU
CPU的分配,至少需要给windows留下1~2个逻辑处理器。- 内存
windows一共8G: 第一台4.5G(4608m),第二台1.5G(1536m),win10预留2G即可。
windows一共12G: 第一台6.5G(6656m),第二台3.5G(3584m),win10预留2G即可。
windows一共16G: 第一台7G(10752m),第二台5G(5120m),win10预留4G即可。
老师采用方案:
hadoop01: 内存:5632M(5.5G) CPU:2*2
hadoop02: 内存:4608M(4.5G) CPU:1*2
注意:如果资源分配感觉不满意,可以在正确关闭虚拟机之后,重新分配。- 打开虚拟机
注意,一定要选择 我已移动该虚拟机
- windows平台添加hosts映射信息
# C:\Windows\System32\drivers\etc\hosts
192.168.88.80 hadoop01
192.168.88.81 hadoop02- 修改Linux虚拟内存
- 虚拟内存swap介绍
如果你的服务器的总是报告内存不足,并且时常因为内存不足而引发服务被强制kill的话,在不增加物理内存的情况下,启用swap交换区作为虚拟内存是一个不错的选择。
swap是Linux中的虚拟内存,用于扩充物理内存不足而用来存储临时数据存在的。它类似于Windows中的虚拟内存。- hadoop01配置
# 1、创建一个swap文件,文件越大耗时越长,注意确保磁盘有足够的可用空间。
dd if=/dev/zero of=/home/swap bs=1024 count=5120000
# 2、将文件格式转换为swap格式的
mkswap /home/swap
# 3、文件分区挂载swap分区
swapon /home/swap
# 4、防止重启后swap分区变成0
vi /etc/fstab
/home/swap swap swap default 0 0
# 5、虚拟内存使用阈值
sysctl -w vm.swappiness=0
echo "vm.swappiness=0" >> /etc/sysctl.conf- hadoop02配置
# 1、创建一个swap文件,文件越大耗时越长,注意确保磁盘有足够的可用空间。
dd if=/dev/zero of=/home/swap bs=1024 count=3072000
# 2、将文件格式转换为swap格式的
mkswap /home/swap
# 3、文件分区挂载swap分区
swapon /home/swap
# 4、防止重启后swap分区变成0
vi /etc/fstab
/home/swap swap swap default 0 0
# 5、虚拟内存使用阈值
sysctl -w vm.swappiness=0
echo "vm.swappiness=0" >> /etc/sysctl.conf- CM Web UI页面
- CM 服务监控
这个服务比较吃内存,如果检测无误之后,可以关系该服务,不影响CDH的使用。
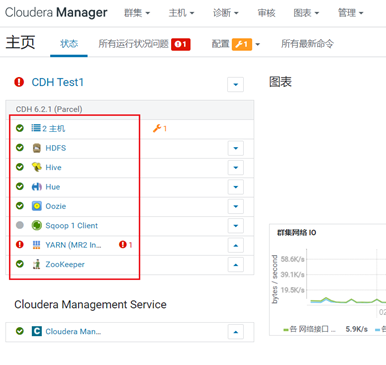
- CDH服务启动状态
注意启动后要等待一段时间,服务才会慢慢正常。
如果遇到个别服务长时间Error(红色叹号),可以手动重启单个服务:
- 虚拟机的正确关闭
使用完毕后,通过==[shutdown -h now]==命令来关闭服务器,不要挂起或强行断电。