
DWS、Presto
资料
1. DWS层实现
- 新零售数仓分层图

- DWS
- 名称:数据服务层 service
- 功能:按主题划分,形成日统计的宽表,轻度汇总提前聚合操作。
- 解释:轻度提前聚合说的是先聚合出日的指标,后续可以上卷出周、月、年的指标。
dws这里,主题终于出现了~~~
一个主题所需要的指标、维度,可能往往需要多个DWB层的宽表共同参与计算才能得出。甚至还需要之前层如dwd等参与计算。
- 使用DataGrip在Hive中创建dws层
-- 创建DWS层的数据库
drop database if exists yp_dws cascade ;
create database if not exists yp_dwsDWS层: 基于主题统计分析, 此层一般是用于最细粒度(日)的统计操作
比如说:
以年 月 日 来统计, 在DWS层 仅需要按照日进行统计相关的指标即可, 进行提前聚合
在DM层: 进行上卷统计, 将 月 和年 基于日的统计宽表 计算得出
思考: 为什么不直接在DWS层根据原始表直接将 年 月 日 都统计好呢, 为什么要先统计日呢, 这样有什么好处?
主要原因, 是为了提升后续进行上卷统计的效率
如果说直接针对原始表, 假设每天有 100w条数据, 进行每日统计, 每天计算都要累计算100w次, 如果按照月来统计, 一个月有30天, 面对是30*100w数据量进行统计, 这样越上统计, 效率越差
如果先按照 日进行统计, 此时 一个月的统计结果数据, 只有30条数据, 在统计月份的时候, 每个中数据量也就只有30条的累加操作, 统计年, 也就只有300多条累加操作
DWS DM
日(100万条) 月(30条累加) 年(365条累加)
如果要进行提前聚合操作, 不能对数据进行去重统计, 比如要统计用户量, 分别统计 每天 每月 和每年本次DWS层以上, 共计有三个主题的, 分别为销售主题, 商品主题, 和 用户主题, 在实际面试中, 可以只负责其中一个主题或者二个主题即可, 无需全部负责, 但是学习中, 希望讲三个主题全部搞定
DWS层以下的层次中, 仅负责其中一个业务模块或者二个业务模块 完整的处理工作即可
销售主题的日统计宽表
可分析的主要指标有:销售收入、平台收入、配送成交额、小程序成交额、安卓APP成交额、苹果APP成交额、PC商城成交额、订单量、参评单量、差评单量、配送单量、退款单量、小程序订单量、安卓APP订单量、苹果APP订单量、PC商城订单量。 (count ,sum)
维度有:日期、城市、商圈、店铺、品牌、大类、中类、小类。
维度组合:
日期
日期+城市
日期+城市+商圈
日期+城市+商圈+店铺(自己写)
日期+品牌
日期+大类
日期+大类+中类
日期+大类+类+小类
16*8 = 128个需求指标结果分析, 当前需要统计的这些维度和指标, 需要涉及到那些表, 以及涉及到那些字段呢?
维度字段 :
-- DWD层订单明细宽表
日期: dwb_order_detail: dt
-- DWD层店铺明细宽表
城市: dwb_shop_detail: city_id 和 city_name
商圈: dwb_shop_detail: trade_area_id 和 trade_area_name
店铺: dwb_shop_detail: store_name 和 id
-- 商品明细宽表
品牌: dwb_goods_detail: brand_id,brand_name
大类: dwb_goods_detail: max_class_name 和 max_class_id
中类: dwb_goods_detail: mid_class_name 和 mid_class_id
小类: dwb_goods_detail: min_class_name 和 min_class_id
指标字段:
单量相关指标: 订单宽表 中 order_id ---》count(order_id)
--订单量、参评单量、差评单量、配送单量、退款单量
-- 小程序订单量、安卓APP订单量、苹果APP订单量、PC商城订单量。
销售收入(小程序, 安卓, 苹果, pc端): 订单宽表 中 order_amount ----》sum(order_amount)
-- 销售收入、小程序成交额、安卓APP成交额、苹果APP成交额、PC商城成交额 (
平台收入:订单宽表 plat_fee ---->sum(plat_fee)
-- 平台收入
配送费: 订单宽表 delivery_fee ---->sum(delivery_fee)
--配送成交额
涉及表:
dwb_order_detail 和 dwb_goods_detail 和 dwb_shop_detail
关联条件:
订单表.store_id = 店铺表.id
订单表.goods_id = 商品表.id
where条件:
1- 保证必须是支付状态: is_pay = 1
2- 保证订单状态: order_state 不能是 1(以下单, 没有付款) 或者 7(已取消)
可以说: 订单宽表, 就是当前主题的事实表, 其他的两个宽表其实就是维度表首先: 先创建DWS层, 销售主题日统计宽表(维度字段+指标字段 + 经验字段)
-- 16*8 = 128个需求指标结果
-- 在此我们需要将销售主体128个指标都保存到该表
城市 商圈 订单量 销售额
北京 三里屯 1000万 10个亿
-- 销售主题日统计宽表
DROP TABLE IF EXISTSyp_dws.dws_sale_daycount;
CREATE TABLEyp_dws.dws_sale_daycount(
-- 维度字段
city_id string COMMENT '城市id',
city_name string COMMENT '城市name',
trade_area_id string COMMENT '商圈id',
trade_area_name string COMMENT '商圈名称',
store_id string COMMENT '店铺的id',
store_name string COMMENT '店铺名称',
brand_id string COMMENT '品牌id',
brand_name string COMMENT '品牌名称',
max_class_id string COMMENT '商品大类id',
max_class_name string COMMENT '大类名称',
mid_class_id string COMMENT '中类id',
mid_class_name string COMMENT '中类名称',
min_class_id string COMMENT '小类id',
min_class_name string COMMENT '小类名称',
-- 经验字段: 用于标记每一条数据是按照哪个维度计算出来的
group_type string COMMENT '分组类型:store,trade_area,city,brand,min_class,mid_class,max_class,all',
-- =======日统计=======
-- 销售收入
sale_amt DECIMAL(38,2) COMMENT '销售收入',
-- 平台收入
plat_amt DECIMAL(38,2) COMMENT '平台收入',
-- 配送成交额
deliver_sale_amt DECIMAL(38,2) COMMENT '配送成交额',
-- 小程序成交额
mini_app_sale_amt DECIMAL(38,2) COMMENT '小程序成交额',
-- 安卓APP成交额
android_sale_amt DECIMAL(38,2) COMMENT '安卓APP成交额',
-- 苹果APP成交额
ios_sale_amt DECIMAL(38,2) COMMENT '苹果APP成交额',
-- PC商城成交额
pcweb_sale_amt DECIMAL(38,2) COMMENT 'PC商城成交额',
-- 成交单量
order_cnt BIGINT COMMENT '成交单量',
-- 参评单量
eva_order_cnt BIGINT COMMENT '参评单量comment=>cmt',
-- 差评单量
bad_eva_order_cnt BIGINT COMMENT '差评单量negtive-comment=>ncmt',
-- 配送成交单量
deliver_order_cnt BIGINT COMMENT '配送单量',
-- 退款单量
refund_order_cnt BIGINT COMMENT '退款单量',
-- 小程序成交单量
miniapp_order_cnt BIGINT COMMENT '小程序成交单量',
-- 安卓APP订单量
android_order_cnt BIGINT COMMENT '安卓APP订单量',
-- 苹果APP订单量
ios_order_cnt BIGINT COMMENT '苹果APP订单量',
-- PC商城成交单量
pcweb_order_cnt BIGINT COMMENT 'PC商城成交单量'
)
COMMENT '销售主题日统计宽表'
PARTITIONED BY(dt STRING)
ROW format delimited fields terminated BY '\t'
stored AS orc tblproperties ('orc.compress' = 'SNAPPY');日期+城市 统计相关指标
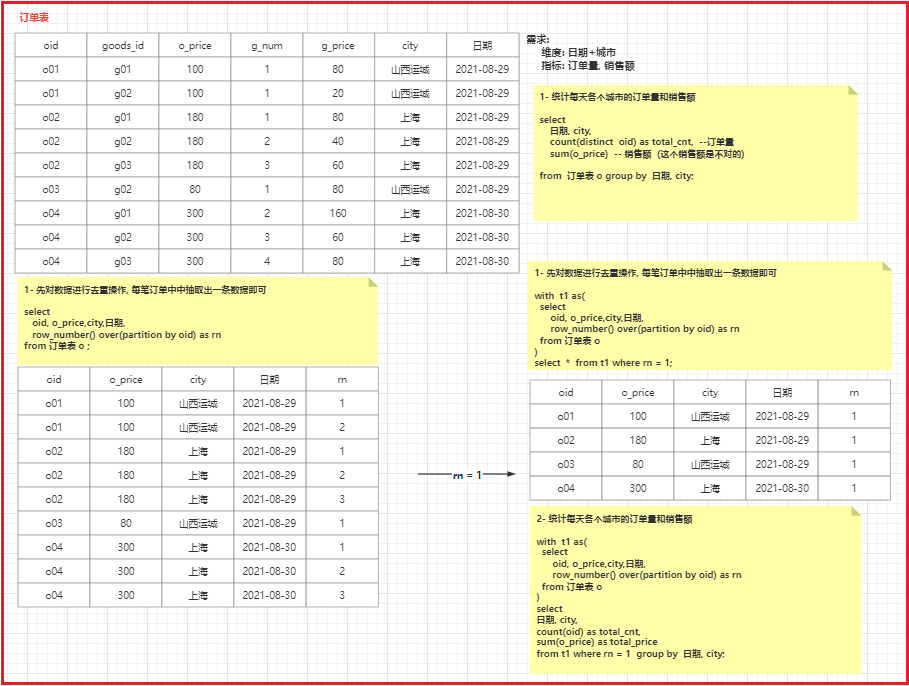
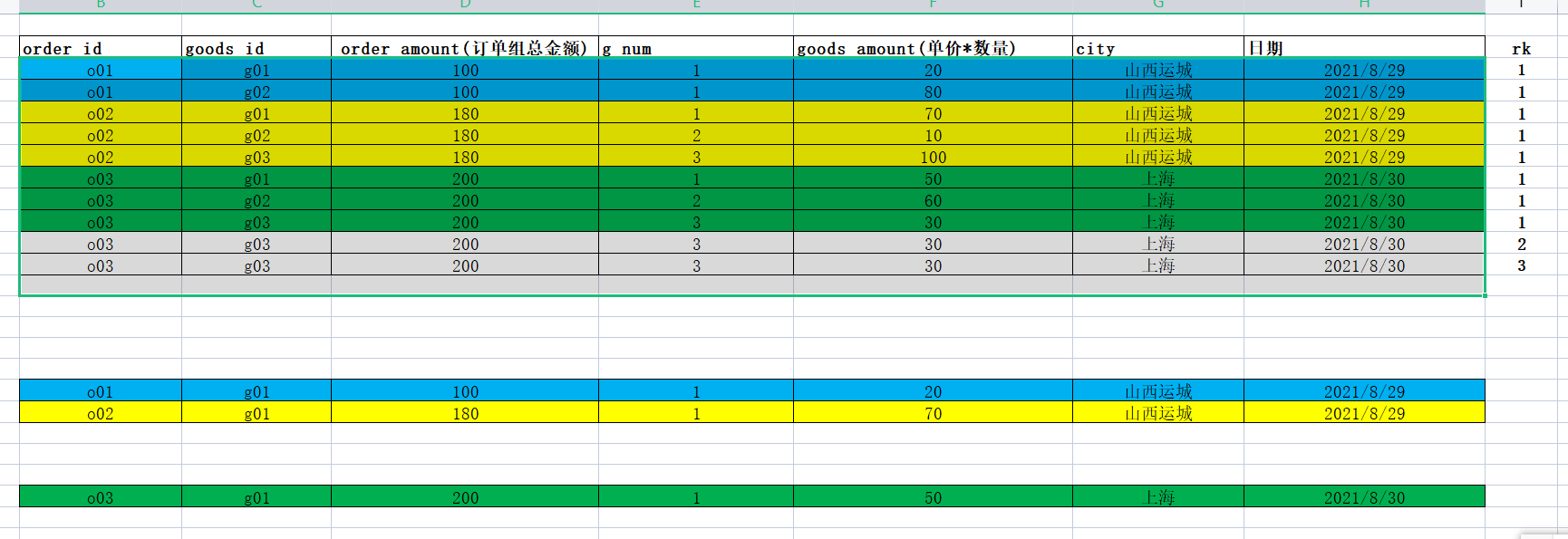
用户下一个订单组, 后台会基于商铺将订单组拆分为多个子订单,每个子订单都是属于一个店铺
一个子订单中, 会有多个商品. 而多个商品隶属于是一个店铺的 所以 一个子订单中city一定是一样的
订单组:
1001 信息
1001 信息
1001 信息
1002 信息
1002 信息
1003 信息
---------------------老师课堂代码-----------------------------
--分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 第一件事:将DWB层的三张明细宽表join
-- 第二件事:将join之后的表进行去重
-- 第三件事:将去重后的表进行统计分析
with t1 as (
select
-- 维度字段
substr(o.create_date, 1, 10) as dt,
s.province_id,
s.province_name,
s.city_id,
s.city_name,
-- 指标字段:
o.order_id, -- 订单id 计算订单量
o.order_amount, -- 订单销售收入
o.plat_fee, -- 平台利润
o.delivery_fee, -- 配送运费
-- 用于判断的字段
o.order_from,
o.evaluation_id, -- 评价表 id 如果不为null, 说明订单有评价信息的
o.delievery_id, -- 配送表id
o.geval_scores, -- 评分信息
o.refund_id,
row_number() over (partition by o.order_id) as rk
from (select * from yp_dwb.dwb_order_detail where is_pay = 1 and order_state not in (1, 7)) o -- 谓词下推
left join yp_dwb.dwb_shop_detail s on o.store_id = s.id
left join yp_dwb.dwb_goods_detail g on o.goods_id = g.id
)
insert overwrite table yp_dws.dws_sale_daycount partition(dt)
select
city_id,
city_name,
null as trade_area_id, -- 商圈id ,这个维度统计没有
null as trade_area_name,
null as store_id,
null as store_name,
null as brand_id,
null as brand_name,
null as max_class_id,
null as max_class_name,
null as mid_class_id,
null as mid_class_name,
null as min_class_id,
null as min_class_name,
'city' as group_type, -- select * from 宽表 where group_type = 'city'
-- 指标
-- 收入指标
-- 在hive中,sum遇到null值会当成0来处理,但是有些计算引擎就不是这样,所以这里我们还是需要对null值做判断
sum(coalesce(order_amount,0)) as sale_amt, -- 销售收
sum(coalesce(plat_fee,0)) as plat_amt, -- 平台收入
sum(coalesce(delivery_fee)) as deliver_sale_amt,
-- 不同平台的销售额
sum(if(order_from = 'miniapp' ,coalesce(order_amount,0),0)) as mini_app_sale_amt,
sum(if(order_from = 'android' ,coalesce(order_amount,0),0)) as android_sale_amt,
sum(if(order_from = 'ios' ,coalesce(order_amount,0),0)) as ios_sale_amt,
sum(if(order_from = 'pcweb' ,coalesce(order_amount,0),0)) as pcweb_sale_amt,
-- 订单量
count(order_id) as order_cnt, -- 订单量
count(evaluation_id) as eva_order_cnt, -- 参评单量 count( if(evaluation_id is not null,order_id, null ) )
count(if(evaluation_id is not null and geval_scores < 6,order_id,null)) as bad_eva_order_cnt, -- 差评单量
count(if(delievery_id is not null ,order_id,null)) as deliver_order_cnt, -- 配送单量: 订单必须是已经被配送了 如果配送了, 属于配送单
count(if(delievery_id is not null ,order_id,null)) as refund_order_cnt,
-- 不同平台的订单量
count(if(order_from = 'miniapp' ,order_id,null)) as miniapp_order_cnt,
count(if(order_from = 'android' ,order_id,null)) as android_order_cnt,
count(if(order_from = 'ios' ,order_id,null)) as ios_order_cnt,
count(if(order_from = 'pcweb' ,order_id,null)) as pcweb_order_cnt,
dt
from t1
where t1.rk = 1
group by t1.dt, t1.province_id, t1.province_name, t1.city_id, t1.city_name;
----------------------参考代码-------------------------------
-- 统计 日期 + 城市 来统计16个指标
with t1 as (
select
-- 维度字段
substr(o.create_date,1,10) as dt,
s.province_id,
s.province_name ,
s.city_id ,
s.city_name ,
-- 指标字段:
o.order_id, -- 订单id 计算订单量
o.order_amount , -- 订单销售收入
o.plat_fee , -- 平台利润
o.delivery_fee, -- 配送运费
-- 用于判断的字段
o.order_from ,
o.evaluation_id, -- 评价表 id 如果不为null, 说明订单有评价信息的
o.delievery_id, -- 配送表id
o.geval_scores, -- 评分信息
o.refund_id,
-- 去重操作
row_number() over(partition by o.order_id) as rn
fromyp_dwb.dwb_order_detail o
left joinyp_dwb.dwb_shop_detail s
on o.store_id = s.id
left joinyp_dwb.dwb_goods_detail g
on o.goods_id = g.id
where o.is_pay = 1 and o.order_state not in(1,7)
)
insert into tableyp_dws.dws_sale_daycount partition(dt)
select
-- 维度信息
city_id ,
city_name,
null as trade_area_id,
null as trade_area_name,
null as store_id,
null as store_name,
null as brand_id,
null as brand_name,
null as max_class_id,
null as max_class_name,
null as mid_class_id,
null as mid_class_name,
null as min_class_id,
null as min_class_name,
'city' as group_type,
-- 指标
-- 收入指标
sum(COALESCE(order_amount,0)) as sale_amt , -- 销售收入
sum(COALESCE(plat_fee,0)) as plat_amt , -- 平台收入
sum(COALESCE(delivery_fee,0)) as deliver_sale_amt, -- 配送成交额
sum( if( order_from = 'miniapp', COALESCE(order_amount,0) ,0 ) ) as mini_app_sale_amt,
sum( if( order_from = 'android', COALESCE(order_amount,0) ,0 ) ) as android_sale_amt,
sum( if( order_from = 'ios', COALESCE(order_amount,0) ,0 ) ) as ios_sale_amt,
sum( if( order_from = 'pcweb', COALESCE(order_amount,0) ,0 ) ) as pcweb_sale_amt,
-- 订单量
count(order_id) as order_cnt,
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了,需要进行统计
count( if(evaluation_id is not null,order_id, null ) ) as eva_order_cnt, -- 参评单量
-- 差评单量:
count( if(evaluation_id is not null and geval_scores <=6 ,order_id, null ) ) as bad_eva_order_cnt,
-- 配送单量: 订单必须是已经被配送了 如果配送了, 属于配送单
count( if(delievery_id is not null, order_id,null)) as deliver_order_cnt,
-- 退款单量: 如果退款id不为null, 认为此订单进行过退款操作(业务: 不判断是否退款成功)
count( if(refund_id is not null , order_id,null) ) as refund_order_cnt,
count( if(order_from = 'miniapp', order_id,null) ) as miniapp_order_cnt,
count( if(order_from = 'android', order_id,null) ) as android_order_cnt,
count( if(order_from = 'ios', order_id,null) ) as ios_order_cnt,
count( if(order_from = 'pcweb', order_id,null) ) as pcweb_order_cnt,
dt
from t1 where rn = 1
group by dt, province_id,province_name ,city_id ,city_name ;coalesce用法
-- coalesce用法
-- coalesce函数如果有多个参数,会返回这个参数中第一个不是null的值
select coalesce(null,null,123,null);
select coalesce(111,null,123,null);
select coalesce(null,null,null,null,null,null,null,888,null,null,null,999,null,null,null);
select coalesce(order_amount,0);
select coalesce(888,0); -- 返回 888
select coalesce(null,0); -- 返回 0日期+城市+商圈统计相关指标
一个子订单中一定是属于一家商铺的, 一个商铺必须是在某一个城市的, 一个城市位置必然是属于某一个商圈的
-- 设置一些hive运行参数信息
--分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
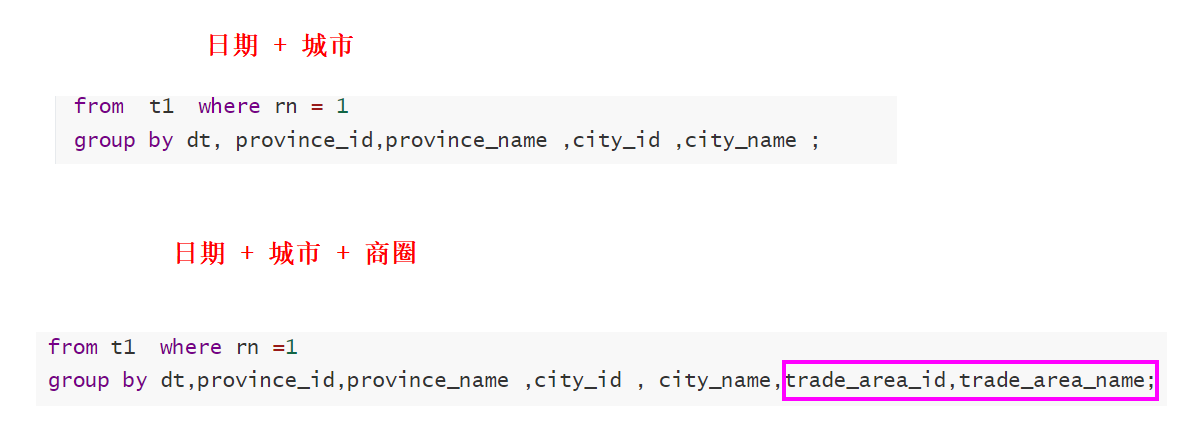
-- 统计 日期 + 城市 + 商圈 来统计16个指标
with t1 as (
select
-- 维度字段
substr(o.create_date,1,10) as dt,
s.province_id,
s.province_name ,
s.city_id ,
s.city_name ,
s.trade_area_id,
s.trade_area_name,
-- 指标字段:
o.order_id, -- 订单id 计算订单量
o.order_amount , -- 订单销售收入
o.plat_fee , -- 平台利润
o.delivery_fee, -- 配送运费
-- 用于判断的字段
o.order_from ,
o.evaluation_id, -- 评价表 id 如果不为null, 说明订单有评价信息的
o.delievery_id, -- 配送表id
o.geval_scores, -- 评分信息
o.refund_id,
-- 去重操作
row_number() over(partition by o.order_id) as rn
fromyp_dwb.dwb_order_detail o
left joinyp_dwb.dwb_shop_detail s
on o.store_id = s.id
left joinyp_dwb.dwb_goods_detail g
on o.goods_id = g.id
where o.is_pay = 1 and o.order_state not in(1,7)
)
insert into tableyp_dws.dws_sale_daycount partition(dt)
select
-- 维度信息
city_id ,
city_name,
trade_area_id,
trade_area_name,
null as store_id,
null as store_name,
null as brand_id,
null as brand_name,
null as max_class_id,
null as max_class_name,
null as mid_class_id,
null as mid_class_name,
null as min_class_id,
null as min_class_name,
'trade_area' as group_type,
-- 指标
-- 收入指标
sum(COALESCE(order_amount,0)) as sale_amt , -- 销售收入
sum(COALESCE(plat_fee,0)) as plat_amt , -- 平台收入
sum(COALESCE(delivery_fee,0)) as deliver_sale_amt, -- 配送成交额
sum( if( order_from = 'miniapp', COALESCE(order_amount,0) ,0 ) ) as mini_app_sale_amt,
sum( if( order_from = 'android', COALESCE(order_amount,0) ,0 ) ) as android_sale_amt,
sum( if( order_from = 'ios', COALESCE(order_amount,0) ,0 ) ) as ios_sale_amt,
sum( if( order_from = 'pcweb', COALESCE(order_amount,0) ,0 ) ) as pcweb_sale_amt,
-- 订单量
count(order_id) as order_cnt,
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了,需要进行统计
count( if(evaluation_id is not null,order_id, null ) ) as eva_order_cnt, -- 参评单量
-- 差评单量:
count( if(evaluation_id is not null and geval_scores <=6 ,order_id, null ) ) as bad_eva_order_cnt,
-- 配送单量: 订单必须是已经被配送了 如果配送了, 属于配送单
count( if(delievery_id is not null, order_id,null)) as deliver_order_cnt,
-- 退款单量: 如果退款id不为null, 认为此订单进行过退款操作(业务: 不判断是否退款成功)
count( if(refund_id is not null , order_id,null) ) as refund_order_cnt,
count( if(order_from = 'miniapp', order_id,null) ) as miniapp_order_cnt,
count( if(order_from = 'android', order_id,null) ) as android_order_cnt,
count( if(order_from = 'ios', order_id,null) ) as ios_order_cnt,
count( if(order_from = 'pcweb', order_id,null) ) as pcweb_order_cnt,
dt
from t1 where rn =1
group by dt,province_id,province_name ,city_id , city_name,trade_area_id,trade_area_name;[*]日期+城市 和 日期 + 商圈 不同之处
- 维度字段不同
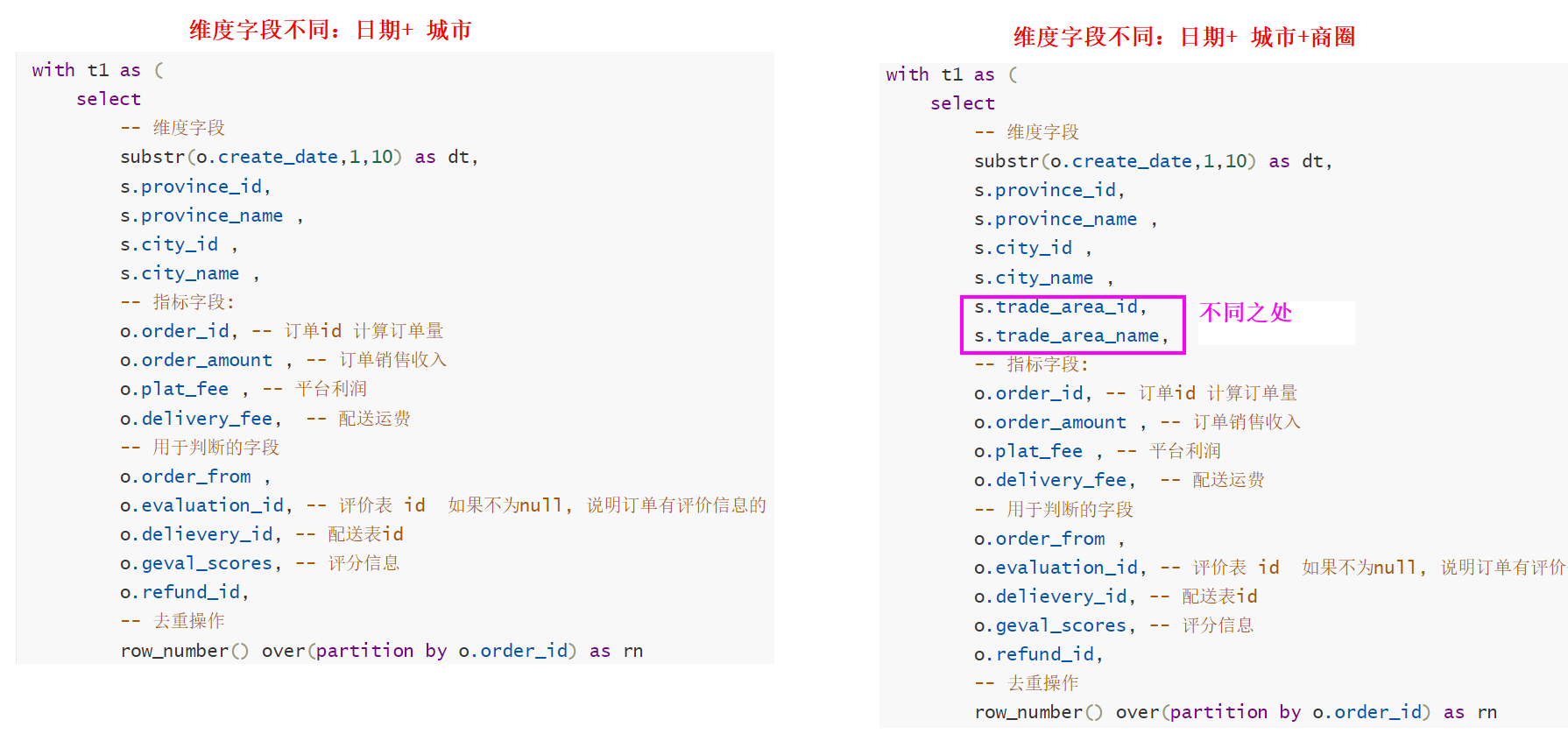
- 插入目标表的字段不同
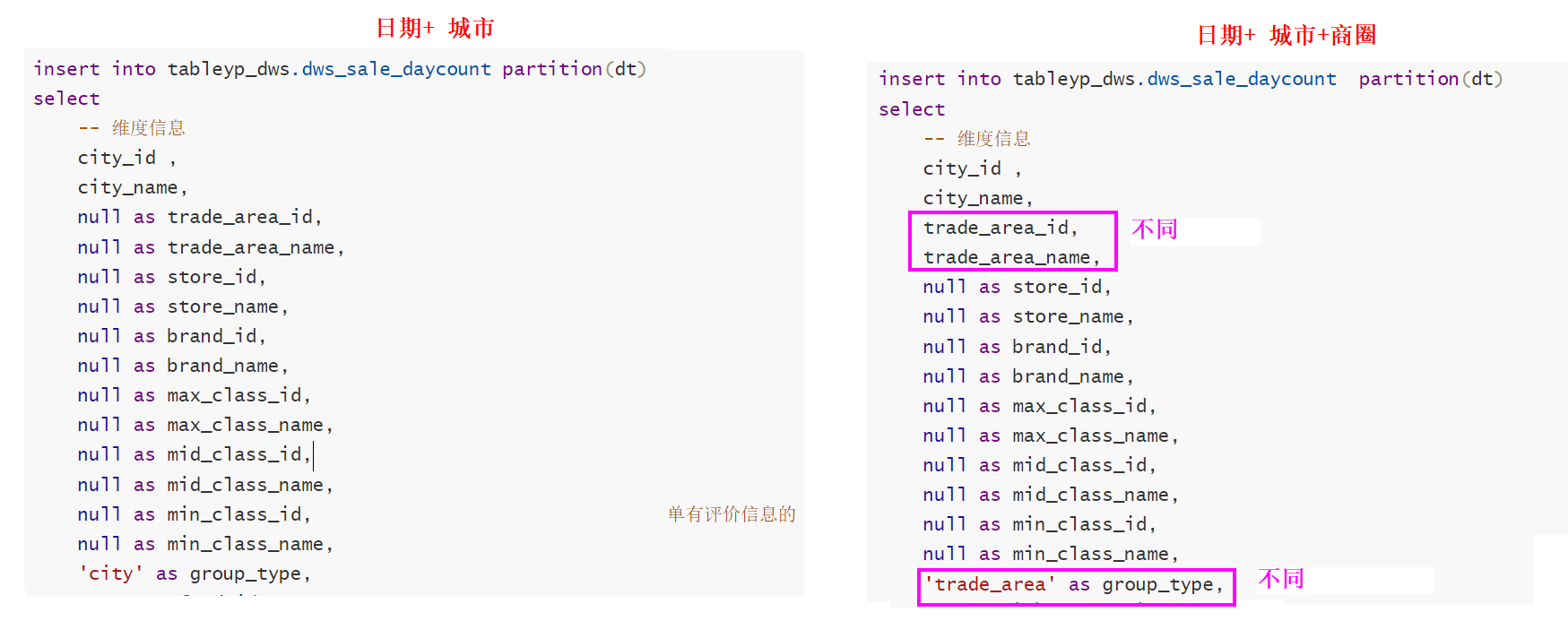
- 分组字段不同
据 日期+品牌统计相关指标
---------------------------------课堂代码-----------------------------------
with t1 as (
select
-- 维度字段
substr(o.create_date,1,10) as dt,
-- s.province_id,
-- s.province_name ,
-- s.city_id ,
-- s.city_name ,
-- s.trade_area_id,
-- s.trade_area_name,
g.brand_id , -- 品牌id
g.brand_name, -- 品牌名字
-- 指标字段:
o.order_id, -- 订单id 计算订单量
o.goods_amount , -- 商品销售收入
o.plat_fee , -- 平台利润
o.delivery_fee, -- 配送运费
-- 用于判断的字段
o.order_from ,
o.evaluation_id, -- 评价表 id 如果不为null, 说明订单有评价信息的
o.delievery_id, -- 配送表id
o.geval_scores, -- 评分信息
o.refund_id
from yp_dwb.dwb_order_detail o
left join yp_dwb.dwb_shop_detail s
on o.store_id = s.id
left join yp_dwb.dwb_goods_detail g
on o.goods_id = g.id
where o.is_pay = 1 and o.order_state not in(1,7)
)
insert into table yp_dws.dws_sale_daycount partition(dt)
select
-- 维度信息
null as city_id ,
null as city_name,
null as trade_area_id,
null as trade_area_name,
null as store_id,
null as store_name,
brand_id,
brand_name,
null as max_class_id,
null as max_class_name,
null as mid_class_id,
null as mid_class_name,
null as min_class_id,
null as min_class_name,
'brand' as group_type,
-- 指标
-- 收入指标
sum(COALESCE(goods_amount,0)) as sale_amt , -- 销售收入
sum(COALESCE(plat_fee,0)) as plat_amt , -- 平台收入
sum(COALESCE(delivery_fee,0)) as deliver_sale_amt, -- 配送成交额
sum( if( order_from = 'miniapp', COALESCE(goods_amount,0) ,0 ) ) as mini_app_sale_amt,
sum( if( order_from = 'android', COALESCE(goods_amount,0) ,0 ) ) as android_sale_amt,
sum( if( order_from = 'ios', COALESCE(goods_amount,0) ,0 ) ) as ios_sale_amt,
sum( if( order_from = 'pcweb', COALESCE(goods_amount,0) ,0 ) ) as pcweb_sale_amt,
-- 订单量
count(distinct order_id) as order_cnt,
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了,需要进行统计
count(distinct if(evaluation_id is not null,order_id, null ) ) as eva_order_cnt, -- 参评单量
-- 差评单量:
count( distinct if(evaluation_id is not null and geval_scores <=6 ,order_id, null ) ) as bad_eva_order_cnt,
-- 配送单量: 订单必须是已经被配送了 如果配送了, 属于配送单
count(distinct if(delievery_id is not null, order_id,null)) as deliver_order_cnt,
-- 退款单量: 如果退款id不为null, 认为此订单进行过退款操作(业务: 不判断是否退款成功)
count(distinct if(refund_id is not null , order_id,null) ) as refund_order_cnt,
count(distinct if(order_from = 'miniapp', order_id,null) ) as miniapp_order_cnt,
count(distinct if(order_from = 'android', order_id,null) ) as android_order_cnt,
count(distinct if(order_from = 'ios', order_id,null) ) as ios_order_cnt,
count(distinct if(order_from = 'pcweb', order_id,null) ) as pcweb_order_cnt,
dt
from t1
group by dt,brand_id,brand_name;
---------------------------------参考代码-----------------------------------
订单和品牌之间关系: 多对多关系
一个子订单里面可能会有多个商品, 每个商品对应一个品牌.可以说一个订单中会有多个品牌
同时一个品牌中可能会有多个商品
-- 设置一些hive运行参数信息
--分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 数据倾斜的解决方案:
-- group by 数据倾斜
set hive.map.aggr=true;
set hive.groupby.skewindata=false;
-- join 数据倾斜
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=100000;
set hive.optimize.skewjoin.compiletime=true;
-- 统计 日期 + 品牌 来统计16个指标
with t1 as (
select
-- 维度字段
substr(o.create_date,1,10) as dt,
s.province_id,
s.province_name ,
s.city_id ,
s.city_name ,
s.trade_area_id,
s.trade_area_name,
g.brand_id ,
g.brand_name ,
-- 指标字段:
o.order_id, -- 订单id 计算订单量
o.total_price, -- 商品总价格
o.order_amount , -- 订单销售收入
o.plat_fee , -- 平台利润
o.delivery_fee, -- 配送运费
-- 用于判断的字段
o.order_from ,
o.evaluation_id, -- 评价表 id 如果不为null, 说明订单有评价信息的
o.delievery_id, -- 配送表id
o.geval_scores, -- 评分信息
o.refund_id,
-- 日期 + 品牌去重
row_number() over(partition by o.order_id,o.goods_id,g.brand_id) as rn1
fromyp_dwb.dwb_order_detail o
left joinyp_dwb.dwb_shop_detail s
on o.store_id = s.id
left joinyp_dwb.dwb_goods_detail g
on o.goods_id = g.id
where o.is_pay = 1 and o.order_state not in(1,7)
)
insert into tableyp_dws.dws_sale_daycount partition(dt)
select
-- 维度信息
null as city_id ,
null as city_name,
null as trade_area_id,
null as trade_area_name,
null as store_id,
null as store_name,
brand_id,
brand_name,
null as max_class_id,
null as max_class_name,
null as mid_class_id,
null as mid_class_name,
null as min_class_id,
null as min_class_name,
'brand' as group_type,
-- 指标
-- 收入指标
sum(COALESCE(total_price,0)) as sale_amt , -- 销售收入
sum(COALESCE(plat_fee,0)) as plat_amt , -- 平台收入
sum(COALESCE(delivery_fee,0)) as deliver_sale_amt, -- 配送成交额
sum( if( order_from = 'miniapp', COALESCE(total_price,0) ,0 ) ) as mini_app_sale_amt,
sum( if( order_from = 'android', COALESCE(total_price,0) ,0 ) ) as android_sale_amt,
sum( if( order_from = 'ios', COALESCE(total_price,0) ,0 ) ) as ios_sale_amt,
sum( if( order_from = 'pcweb', COALESCE(total_price,0) ,0 ) ) as pcweb_sale_amt,
-- 订单量
count(DISTINCT order_id) as order_cnt,
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了,需要进行统计
count(DISTINCT if(evaluation_id is not null,order_id, null ) ) as eva_order_cnt, -- 参评单量
-- 差评单量:
count(DISTINCT if(evaluation_id is not null and geval_scores <=6 ,order_id, null ) ) as bad_eva_order_cnt,
-- 配送单量: 订单必须是已经被配送了 如果配送了, 属于配送单
count(DISTINCT if(delievery_id is not null, order_id,null)) as deliver_order_cnt,
-- 退款单量: 如果退款id不为null, 认为此订单进行过退款操作(业务: 不判断是否退款成功)
count(DISTINCT if(refund_id is not null , order_id,null) ) as refund_order_cnt,
count(DISTINCT if(order_from = 'miniapp', order_id,null) ) as miniapp_order_cnt,
count(DISTINCT if(order_from = 'android', order_id,null) ) as android_order_cnt,
count(DISTINCT if(order_from = 'ios', order_id,null) ) as ios_order_cnt,
count(DISTINCT if(order_from = 'pcweb', order_id,null) ) as pcweb_order_cnt,
dt
from t1 where rn1 = 1
GROUP by dt,brand_id , brand_name ;如何解决数据倾斜问题
何为数据倾斜:
在hive中, 执行一条SQL语句, 最终会翻译为MR, MR中mapTask和reduceTask都可能存在多个, 数据倾斜主要指的是整个MR中reduce阶段有多个reduce , 每个reduce拿到的数据的条数并不均衡, 导致某一个或者某几个拿到了比其他的reduce更多的数据, 导致处理数据压力集中在某几个reduce上, 形成数据倾斜问题在hive中执行什么SQL操作的时候可能会出现数据倾斜
1) 执行多表join的操作
2) 执行group by的操作join数据倾斜的处理

出现倾斜的根本原因:
在reduce中,某一个, 或者某几个的分组k2对应value的数据比较多, 从而引起数据倾斜问题- 解决方案一:
可以通过 map join, bucket map join 以及 SMB Map join 解决
注意:
通过map join来解决数据倾斜, 但是map join使用是存在条件的, 如果无法满足这些条件, 无法使用map join
结论:
使用之前的小表join大表,中表join大表,大表join大表进行优化- 解决方案二:
思路: 将那些产生倾斜的k2和对应value数据, 从当前这个MR移植出去, 单独找一个MR来处理即可, 处理后, 和之前MR的汇总结果即可
关键问题: 如何找出那些存在倾斜的k2数据
---------------------方式1:运行期处理方案----------------------------
思路: 在执行MR的时候, 会动态统计每一个k2的值出现的重复的数量, 当这个重复的数量达到一定阈值后, 认为当前这个k2的数据存在数据倾斜, 自动将其剔除, 交由给一个单独的MR来处理即可, 两个MR处理完成后, 将结果, 基于union all 合并在一起即可
实操 :
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=100000; -- 此参数在实际生产环境中, 需要进行调整在合理的值
适用于: 并不清楚那个key容易产生倾斜, 此时可以交由系统来动态检测
比如说: 共计有1000w数据, join字段为 id id值可能有500个不同值
此时 1000w / 500 = 20w 也就是一个值平均有20w左右
此时在设置的时候, 数量一定要大于20w的 一般来说 1.5倍 到 3倍左右
---------------------方式2:编译期处理方案-----------------------------
思路: 在创建这个表的时候,我们就可以预知到后续插入到这个表中, 那些key的值会产生倾斜, 在建表的时候, 将其提前配置设置好即可, 在后续运行的时候, 程序会自动将设置的k2的值数据单独找一个MR来进行单独的处理操作, 处理后, 再和原有MR进行union all的合并操作
实操:
set hive.optimize.skewjoin.compiletime=true;
建表
CREATE TABLE list_bucket_single (key STRING, value STRING)
-- 倾斜的字段和需要拆分的key值
SKEWED BY (字段名) ON (值, 值2...)
-- 为倾斜值创建子目录单独存放
[STORED AS DIRECTORIES];
-----------------------------------------------------------
create table stux(
id int ,
name string
)skewed by (id) on(1,2);
在实际生产环境中, 应该使用那种方式呢? 两种方式都会使用的
一般来说, 会将两个都开启, 编译期的明确那个key有倾斜在编译期将其设置好, 编译期不清楚, 通过 运行期动态捕获即可- union all优化方案
说明: 不管是运行期, 还是编译期的join倾斜解决, 最终都会运行多个MR , 最终将多个MR的结果, 通过union all进行汇总, union all也是单独需要一个MR来运行的
解决方案:
让每一个MR在运行完成后, 直接将结果输出到目的地即可, 默认是输出到临时文件目录下, 通过union all合并到最终目的地
set hive.optimize.union.remove=true;group by 数据倾斜
- 为什么在执行group by的时候 可能会出现数据倾斜
假设目前有这么一个表:
sid sname cid
s01 张三 c01
s02 李四 c02
s03 王五 c01
s04 赵六 c03
s05 田七 c02
s06 周八 c01
s07 李九 c01
s08 老夯 c03
需求: 请计算每个班级有多少个人
select cid, count(1) from stu group by cid;
翻译后MR是如何处理SQL的呢?
map 阶段:
mapTask 1
k2 v2
c01 {s01 张三 c01}
c02 {s02 李四 c02}
c01 {s03 王五 c01}
c03 {s04 赵六 c03}
mapTask 2
k2 v2
c02 {s05 田七 c02}
c01 {s06 周八 c01}
c01 {s07 李九 c01}
c03 {s08 老夯 c03}
reduce 阶段
reduceTask 1 : 接收 c01 和 c03
接收到的数据:
k2 v2
c01 {s01 张三 c01}
c01 {s03 王五 c01}
c03 {s04 赵六 c03}
c01 {s06 周八 c01}
c01 {s07 李九 c01}
c03 {s08 老夯 c03}
分组后:
c01 [{s01 张三 c01},{s03 王五 c01},{s06 周八 c01},{s07 李九 c01}]
c03 [{s04 赵六 c03},{s08 老夯 c03}]
结果:
c01 4
c03 2
reduceTask 2 : 接收 c02
接收到的数据:
k2 v2
c02 {s02 李四 c02}
c02 {s05 田七 c02}
分组后:
c02 [{s02 李四 c02} , {s05 田七 c02}]
结果:
c02 2
以上整个计算过程中, 发现 其中一个reduce接收到的数据量比另一个reduce接收的数据量要多得多, 认为出现了数据倾斜问题思考: 如何解决group by的数据倾斜呢?
解决方案一: 基于MR的combiner(规约)减轻数据倾斜问题 (小combiner)
假设目前有这么一个表:
sid sname cid
s01 张三 c01
s02 李四 c02
s03 王五 c01
s04 赵六 c03
s05 田七 c02
s06 周八 c01
s07 李九 c01
s08 老夯 c03
需求: 请计算每个班级有多少个人
select cid, count(1) from stu group by cid;
翻译后MR是如何处理SQL的呢?
map 阶段:
mapTask 1
k2 v2
c01 {s01 张三 c01}
c02 {s02 李四 c02}
c01 {s03 王五 c01}
c03 {s04 赵六 c03}
规约操作: 跟reduce的操作是一致的
输出:
k2 v2
c01 2
c02 1
c03 1
mapTask 2
k2 v2
c02 {s05 田七 c02}
c01 {s06 周八 c01}
c01 {s07 李九 c01}
c03 {s08 老夯 c03}
规约操作: 跟reduce的操作是一致的
输出:
k2 v2
c02 1
c01 2
c03 1
reduce 阶段
reduceTask 1 : 接收 c01 和 c03
接收到数据:
k2 v2
c01 2
c03 1
c01 2
c03 1
分组处理:
c01 [2,2]
c03 [1,1]
结果:
c01 4
c03 2
reduceTask 2 : 接收 c02
接收到数据:
k2 v2
c02 1
c02 1
分组后:
c02 [1,1]
结果:
c02 2
通过规约来解决数据倾斜, 发现处理后, 两个reduce中从原来相差3倍, 变更为相差2倍 , 减轻了数据倾斜问题
如何配置呢?
只需要在hive中开启combiner使用配置即可:
set hive.map.aggr=true;解决方案二: 基于负载均衡的方案解决 (大的combiner)
解决方案二: 基于负载均衡的方案解决 (大的combiner)
假设目前有这么一个表:
sid sname cid
s01 张三 c01
s02 李四 c02
s03 王五 c01
s04 赵六 c03
s05 田七 c02
s06 周八 c01
s07 李九 c01
s08 老夯 c03
需求: 请计算每个班级有多少个人
select cid, count(1) from stu group by cid;
翻译后MR是如何处理SQL的呢?
第一个MR的操作: 打散操作
map 阶段:
mapTask 1
k2 v2
c01 {s01 张三 c01}
c02 {s02 李四 c02}
c01 {s03 王五 c01}
c03 {s04 赵六 c03}
mapTask 2
k2 v2
c02 {s05 田七 c02}
c01 {s06 周八 c01}
c01 {s07 李九 c01}
c03 {s08 老夯 c03}
mapTask执行完成后, 在进行分发数据到达reduce, 默认将相同的k2的数据发往同一个reduce, 此时采用方案是随机分发, 保证每一个reduce拿到相等的数据条数即可
reduce阶段:
reduceTask 1:
接收到数据:
k2 v2
c01 {s01 张三 c01}
c02 {s02 李四 c02}
c01 {s03 王五 c01}
c01 {s06 周八 c01}
分组操作:
c01 [{s01 张三 c01},{s03 王五 c01},{s06 周八 c01}]
c02 [{s02 李四 c02}]
结果:
c01 3
c02 1
reduceTask 2:
接收到数据:
k2 v2
c03 {s04 赵六 c03}
c01 {s07 李九 c01}
c02 {s05 田七 c02}
c03 {s08 老夯 c03}
分组操作:
c03 [{s04 赵六 c03},{s08 老夯 c03}]
c01 [{s07 李九 c01}]
c02 [{s05 田七 c02}]
结果:
c03 2
c01 1
c02 1
第二个MR进行处理: 严格按照相同k2发往同一个reduce
map阶段:
mapTask 1:
k2 v2
c01 3
c02 1
c03 2
c01 1
c02 1
reduce阶段:
reduceTask 1: 接收 c01 和 c03
接收到数据:
k2 v2
c01 3
c01 1
c03 2
结果:
c01 4
c03 2
reduceTask 2: 接收 c02
接收到的数据:
k2 v2
c02 1
c02 1
结果:
c02 2
通过负载均衡来解决数据倾斜, 发现处理后, 两个reduce中从原来相差3倍, 变更为相差1.5倍 , 减轻了数据倾斜问题
如何操作:
只需要在hive中开启负载均衡使用配置即可:
set hive.groupby.skewindata=true;
这两种解决方案, 建议生产中使用 第一种, 如果第一种无法解决, 尝试使用第二种解决
注意: 使用第二种负载均衡的解决group by的数据倾斜, 一定要注意, sql语句中不能出现多次 distinct操作, 否则hive直接报错
错误信息:
Error in semantic analysis: DISTINCT on different columns notsupported with skew in data倾斜的优化开启条件, 一定是出现了数据倾斜的问题, 如果没有出现, 不需要开启的
思考: 如何才能知道发生了数据倾斜呢?
倾斜出现后, 出现的问题, 程序迟迟无法结束, 或者说翻译MR中reduceTask有多个, 大部分的reduceTask都执行完成了, 只有其中一个或者某几个没有执行完成, 此时认为发生了数据倾斜- 方式一: 通过 yarn查看(运行过程中)或jobhistory查看(程序结束后)

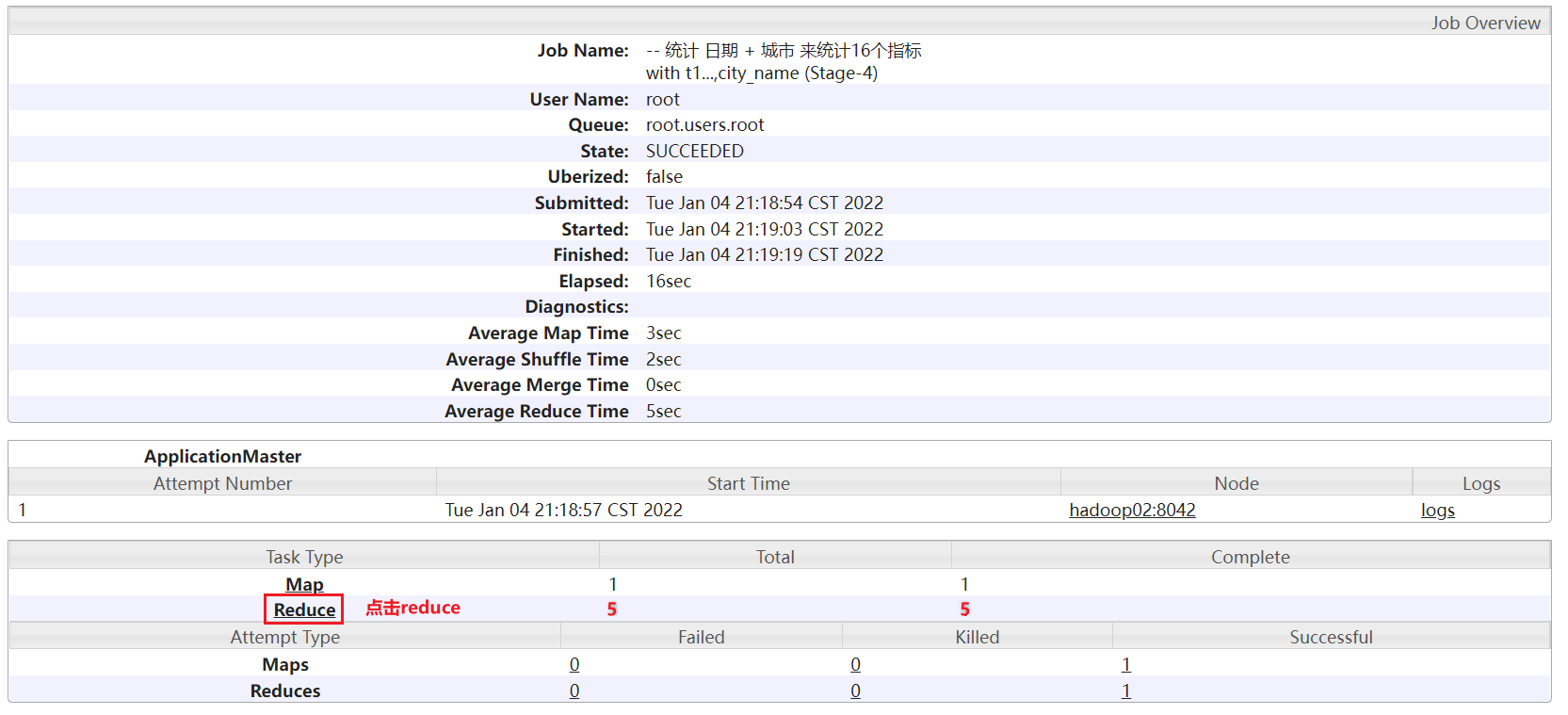

看的就是这个reduce的执行时间, 如果这个时间比其他reduce的时候都大的多, 认为出现了数据倾斜问题- 还可以通过HUE查看
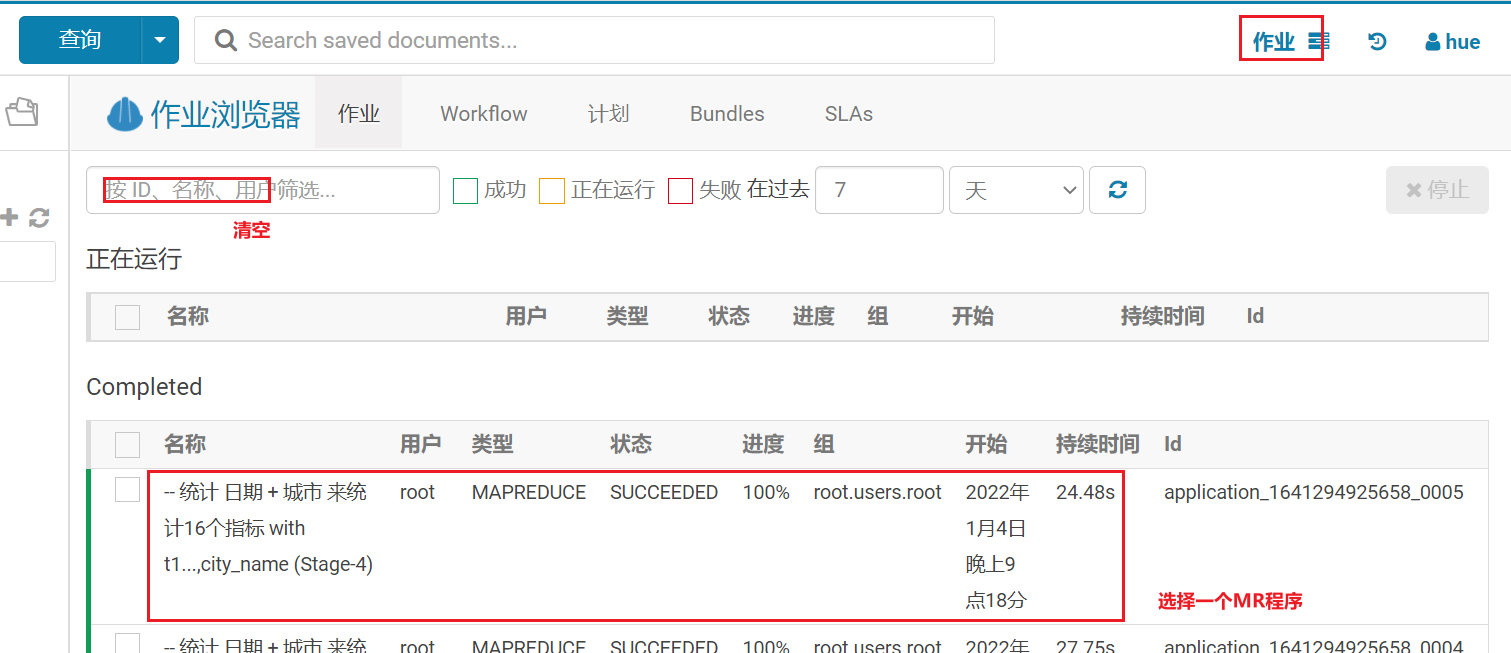
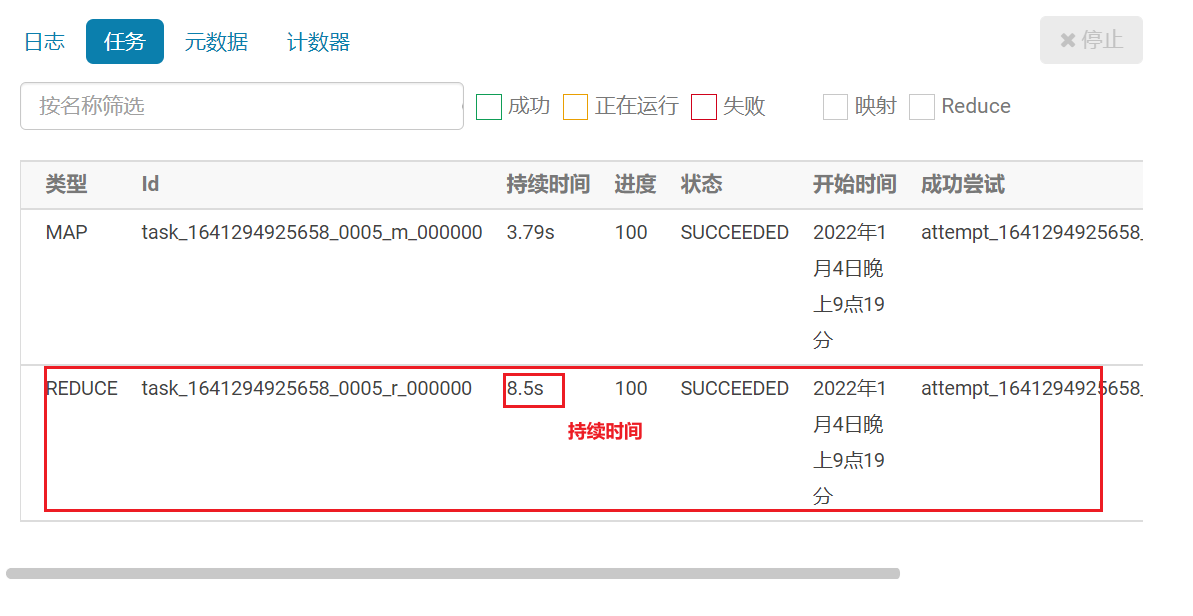
-- 演示数据倾斜
set mapreduce.job.reduces=10;
select city_id,count(*) from yp_dws.dws_sale_daycount group by city_id;hive的索引
- hive的原始索引(废弃)
hive的原始索引可以针对某个列 或者某几个列构建索引信息, 构建后提升指定列的查询效率, 存在弊端: hive原始索引不会自动更新, 每次表中数据发生变化后, 都是需要手动重建索引操作, 比较耗费资源, 整体提升性能效果一般
所有在hive3.x版本已经直接将这种索引废弃掉, 无法使用了, 及时在生产中使用是hive1.x或者hive2.x版本的 不建议优先使用原始索引- hive的row group index (行组索引)
条件:
1) 要求表的存储类型必须为ORC存储格式
2) 在创建表的时候, 必须开启 row group index 索引支持
’orc.create.index’=’true’
3) 在插入数据的时候, 必须保证需要进行索引列, 按序插入操作
思路:
插入数据到ORC表后, 会自动进行划分为多个script片段, 每个片段内部, 会保存着每个字段的最小 最大值, 这样当执行查询 > < = 的条件筛选操作的时候, 根据最大最小值锁定相关script, 从而减少数据扫描量, 提升效率
操作:
CREATE TABLE lxw1234_orc2 (...) stored AS ORC
TBLPROPERTIES
(
'orc.compress'='SNAPPY',
-- 开启行组索引
'orc.create.index'='true'
)
插入数据:
insert into table lxw1234_orc2
SELECT CAST(siteid AS INT) AS id,
pcid
FROM lxw1234_text
-- 插入的数据保持排序
DISTRIBUTE BY id sort BY id;
使用:
select * from lxw1234_orc2 where id >100 ; --自动应用行组索引了
-------示例SQL-----------------------------------
create table if not exists yp_ods.t_district
(
`id` string comment '主键ID',
`code` string comment '区域编码',
`name` string comment '区域名称',
`pid` string comment '父级ID',
`alias` string comment '别名'
) comment '区域字典表'
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress' = 'ZLIB','orc.create.index'='true');
-- 插入数据
insert into table yp_ods.t_district
SELECT
*
FROM A表
-- 插入的数据保持排序
DISTRIBUTE BY id sort BY id;- bloom filter index (布隆过滤索引, 开发过滤索引)
思路:
在开启布隆过滤索引后, 可以针对某个列,或者某几个列来建立索引, 构建索引后, 会在将这一列的数据的值存储在对应script片段的索引信息中, 这样当进行=值查询数据的时候, 首先会到每一个script片段判断是否有这个值, 如果没有, 直接跳过这个script, 从而减少数据扫描量, 提升效率
条件:
1) 要求表的存储类型必须为ORC存储格式
2) 在建表的时候, 必须设置为那些列构建布隆索引
3) 仅能适用于 等值过滤查询操作
操作:
CREATE TABLE lxw1234_orc2 stored AS ORC
TBLPROPERTIES
(
'orc.compress'='SNAPPY',
'orc.create.index'='true', --行组索引
-- pcid字段开启BloomFilter索引
"orc.bloom.filter.columns"="pcid,name"
)
使用:
select * from 表 where name = '张三' and age >10 就会使用布隆索引+ 行组索引HIVE其他优化
- hive的并行优化的内容
1) 并行编译:
hive.driver.parallel.compilation : 是否开启并行编译的操作
hive.driver.parallel.compilation.global.limit: 设置最大同时编译几个会话的SQL
如果设置为 0 或者 负值 , 此时无限制
设置方式1:
set hive.driver.parallel.compilation = true
set hive.driver.parallel.compilation.global.limit=15
设置方式2: 建议在CM上设置
hive.driver.parallel.compilation true
hive.driver.parallel.compilation.global.limit 15
说明:
默认情况下, 如果hive有多个会话窗口, 而且多个窗口都在提交SQL, 此时hive默认只能对一个会话的SQL进行编译, 其他会话的SQL需要等待, 这样效率相对比较低
2) 并行执行:
一个SQL语句在提交给hive之后, SQL有可能会被翻译为多个阶段, 在这个过程中, 有可能出现多个阶段互不干扰的情况,这个时候, 可以安排多个阶段并行执行的操作, 以此来提升效率
如何设置呢? 推荐在 会话中设置
set hive.exec.parallel=true; 是否开启并行执行
set hive.exec.parallel.thread.number=16; 最大运行并行多少个阶段
注意:
开启了此配置, 并不代表着所有SQL一定会并行的执行, 因为是否并行执行还取决于SQL中多个阶段之间是否有依赖, 只有在没有依赖的时候, 才可能并行执行
例子: union all
select * from A group by id
union all
select * from B group by id;
select * from (select * from B group by id) group by id;
hive常规的做法:
先执行第一个阶段 : select * from A order by c 得出临时结果
接着执行第二个阶段: select * from B where xxx; 得出临时结果
最后, 将两个语句的结果 合并在一起- 小文件合并的操作:
当HDFS中小文件过多后, 会导致整个HDFS的存储容量的下降, 因为每一个小文件都会有一个元数据, 而元数据是存储在namenode的内存中, 当内存一旦满了, 即使datanode上还有空间, 那么也是无法存储了
MR角度: 当小文件过多后, 就会导致读取数据时候, 产生大量文件的切片, 从而导致有多个mapTask的执行, 而每个mapTask处理数据量比较的少, 导致资源的浪费, 导致执行时间较长, 因为一旦没有资源, 所有map只能串行化执行
hive的解决方案: 在执行完成后, 输出的结果的文件尽量的少一些, 避免出现小文件过多问题, 可以通过设置让执行的SQL输出的文件竟可能少一些
hive.merge.mapfiles: 是否开启map端的小文件合并操作, 指的 MR只有map没有reduce的操作时候
hive.merge.mapredfiles: 是否开启reduce端的小文件合并操作, 指的普通MR
hive.merge.size.per.task: 设置文件的大小 合并后的文件最大值 比如 128M
hive.merge.smallfiles.avgsize: 当输出文件的平均大小小于此设置值时,启动一个独立的map-reduce任务进行文件merge,默认值为16M。
说明: 以上配置均可直接在CM上进行配置即可
思考点: 在执行SQL的时候, 什么样SQL 可能会出现多个reduce情况? group by join
例如:
比如一个MR输出 10个文件
1M 10M 50M 2M 3M 30M 10M 5M 6M 20M = 136M / 10 = 13.6M
此时请问, 是否会进行文件合并工作呢? 发现得出平均值是小于16M 的 所以会执行小文件合并操作
思考: 是将所有的文件合并为一个文件, 还是怎么做呢?
128M 8M- 矢量化查询(批量化):
配置:
set hive.vectorized.execution.enabled=true; 默认值为true
说明:
一旦开启了矢量化查询的工作,hive执行引擎在读取数据时候, 就会采用批量化读取工作, 一次性读取1024条数据进行统一的处理工作, 从而减少读取的次数(减少磁盘IO次数), 从而提升效率
注意:
要求表的存储格式必须为 ORC
结论:默认情况下,Hive读取数据是一行行读取,如果使用了ORC格式,而且开启了矢量化查询,一次性读取1024条数据进行统一的处理工作- 读取零拷贝:
一句话: 在读取数据的时候, 能少读一点 尽量 少读一些(没用的数据尽量不读)
配置:
set hive.exec.orc.zerocopy=true; 默认中为false
例子:
看如下这个SQL: 假设A表中 a b c三个字段
select a,b from A where a =xxx;
注意: 存储格式为ORC- 关联优化器: 如果多个MR之间的操作的数据都是一样的, 同样shuffle操作也是一样的, 此时可以共享shuffle
一个SQL最终翻译成MR , 请问 有没有可能翻译为多个MR的情况呢? 非常有可能
每一个MR的中间有可能都会执行shuffle的操作, 而shuffle其实比较消耗资源操作(内部存在多次 io操作)
配置项: set hive.optimize.correlation=true;总结优化点:
建议常开
set hive.vectorized.execution.enabled=true; -- 矢量化查询
set hive.exec.orc.zerocopy=true; -- 读取零拷贝
set hive.optimize.correlation=true; --开启关联优化器
set hive.merge.mapfiles = true; -- 小文件合并 map输出合并
set hive.merge.mapredfiles = true: -- 小文件合并 reduce输出合并
set hive.merge.size.per.task=128M: 设置文件的大小 合并后的文件最大值 比如 128M
set hive.merge.smallfiles.avgsize=16M: 当输出文件的平均大小小于此设置值时,启动一个独立的map-reduce任务进行文件merge,默认值为16M。
-- 如果资源不足, 及时可以并行, 也没有用
set hive.exec.parallel=true; --是否开启并行执行
set hive.exec.parallel.thread.number=16; --最大运行并行多少个阶段
数据倾斜的优化: 判定是否有倾斜 进行开启 如果没有倾斜 此操作会导致执行效率更差
set hive.optimize.skewjoin.compiletime=true; -- 开启编译期优化
set hive.optimize.skewjoin=true; -- 开启运行期数据倾斜的处理 默认值为false
set hive.skewjoin.key=100000;
set hive.optimize.union.remove=true; -- union优化
set hive.groupby.skewindata=true; -- 开启负载均衡优化
一般在CM环境搭建的时候, 就直接配置好:
并行编译: 建议在CM中开启, 生产中建议配置的, 因为生产中 不至于只有你自己在用presto基本介绍
知识点12:Presto--分布式SQL查询引擎介绍
- 背景
大数据分析类软件发展历程。
- Apache Hadoop MapReduce
- 优点:统一、通用、简单的编程模型,分而治之思想处理海量数据。
- 缺点:java学习成本、MR执行慢、内部过程繁琐
- Apache Hive
- 优点:SQL on Hadoop。sql语言上手方便。学习成本低。
- 缺点:底层默认还是MapReduce引擎、慢、延迟高
- 各种SQL类计算引擎开始出现,主要追求的就是一个问题:怎么能计算的更快,延迟低。
- Spark On Hive、Spark SQL
- Impala
- Presto
- ClickHouse
- ........
- 介绍
Presto是一个开源的分布式SQL查询引擎,适用于交互式查询,数据量支持GB到PB字节。 Presto的设计和编写完全是为了解决Facebook这样规模的商业数据仓库交互式分析和处理速度的问题。
Presto支持在线数据查询,包括Hive、kafka、Cassandra、关系数据库以及专门数据存储;
一条Presto查询可以将多个数据源进行合并,可以跨越整个组织进行分析;
Presto以分析师的需求作为目标,他们期望相应速度小于1秒到几分钟;
Presto终结了数据分析的两难选择,要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。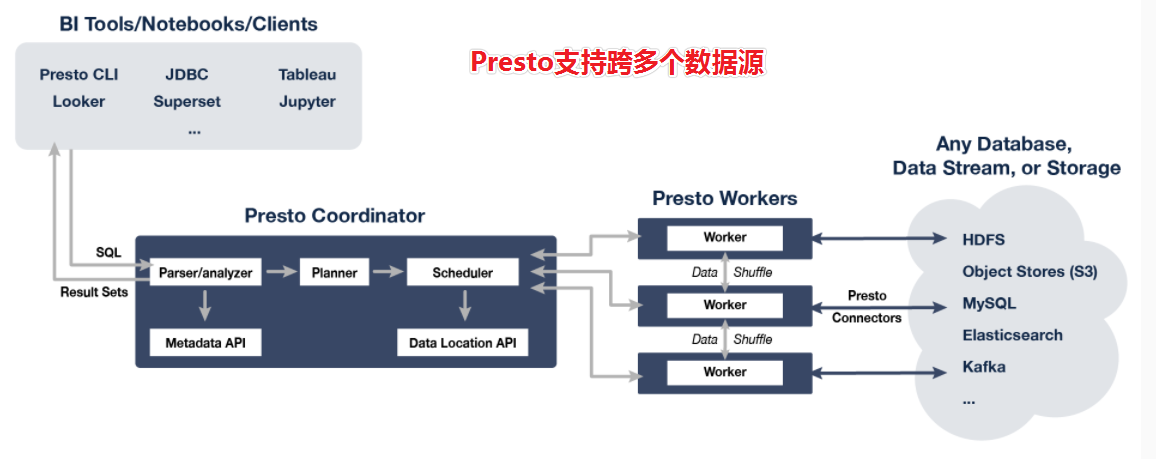
- 优缺点
#优点
1)Presto与Hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
2)能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
3)部署也比Hive简单,因为Hive是基于HDFS的,需要先部署HDFS。
#缺点
1)虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
2)为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。跨数据源查询
select * from A表(Hive) left join B表(MySQL) left join C表(HBase);知识点12:Presto--架构、相关术语
- 架构图
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator; coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
- Connector 连接器
1、Presto通过Connector连接器来连接访问不同数据源,例如Hive或mysql。连接器功能类似于数据库的驱动程序。允许Presto使用标准API与资源进行交互。
2、Presto包含几个内置连接器:JMX连接器,可访问内置系统表的System连接器,Hive连接器和旨在提供TPC-H基准数据的TPCH连接器。许多第三方开发人员都贡献了连接器,因此Presto可以访问各种数据源中的数据,比如:ES、Kafka、MongoDB、Redis、Postgre、Druid、Cassandra等。- Catalog 连接目录
1、Presto Catalog是数据源schema的上一级,并通过连接器访问数据源。
2、例如,可以配置Hive Catalog以通过Hive Connector连接器提供对Hive信息的访问。
3、在Presto中使用表时,标准表名始终是被支持的。
例如,hive.test_data.test的标准表名将引用hive catalog中test_data schema中的test table。
Catalog需要在Presto的配置文件中进行配置。- schema
Schema是组织表的一种方式。Catalog和Schema共同定义了一组可以查询的表。
当使用Presto访问Hive或关系数据库(例如MySQL)时,Schema会转换为目标数据库中的对应Schema。
=schema通俗理解就是我们所讲的database.
=想一下在hive中,下面这两个sql是否相等。
show databases;
shwo schemas;
结论:
Presto : Schema
Hive/MySQL: Database- table
知识点13:Presto--集群模式安装
- step1:集群规划
- step2:项目集群环境安装JDK
#可以手动安装oracle JDK
#也可以使用yum在线安装 openjDK
yum install java-1.8.0-openjdk* -y
#安装完成后,查看jdk版本:
java -version- step3:上传Presto安装包(hadoop01)
#创建安装目录
mkdir -p /export/server
#yum安装上传文件插件lrzsz
yum install -y lrzsz
#上传安装包到hadoop01的/export/server目录
presto-server-0.245.1.tar.gz
#解压、重命名
tar -xzvf presto-server-0.245.1.tar.gz
mv presto-server-0.245.1 presto
#创建配置文件存储目录
mkdir -p /export/server/presto/etc- step4:添加配置文件(hadoop01)
- etc/config.properties
cd /export/server/presto
vim etc/config.properties
#---------添加如下内容---------------
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8090
query.max-memory=6GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://192.168.88.80:8090
#---------end-------------------
#参数说明
coordinator:是否为coordinator节点,注意worker节点需要写false
node-scheduler.include-coordinator:coordinator在调度时是否也作为worker
discovery-server.enabled:Discovery服务开启功能。presto通过该服务来找到集群中所有的节点。每一个Presto实例都会在启动的时候将自己注册到discovery服务; 注意:worker节点不需要配
discovery.uri:Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery服务,因此这个uri就是Presto coordinator的uri。- etc/jvm.config
vim etc/jvm.config
-server
-Xmx3G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError- etc/node.properties
mkdir -p /export/data/presto
vim etc/node.properties
node.environment=cdhpresto
node.id=presto-cdh01
node.data-dir=/export/data/presto- etc/catalog/hive.properties
mkdir -p etc/catalog
vim etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.88.80:9083
hive.max-partitions-per-writers=300- step4:scp安装包到其他机器
#在hadoop02创建文件夹
mkdir -p /export/server
#在hadoop01远程cp安装包
cd /export/server
scp -r presto hadoop02:$PWD
#ssh的时候如果没有配置免密登录 需要输入密码scp 密码:123456- step5:hadoop02配置修改
- etc/config.properties
cd /export/server/presto
vim etc/config.properties
#----删除之前文件中的全部内容 替换为以下的内容 vim编辑器删除命令 8dd
coordinator=false
http-server.http.port=8090
query.max-memory=6GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=2GB
discovery.uri=http://192.168.88.80:8090- etc/jvm.config
和hadoop01一样,不变,唯一注意的就是如果机器内存小,需要调整-Xmx参数
- etc/node.properties
修改编号node.id
- etc/catalog/hive.properties
保持不变
知识点14:Presto--集群启停
注意,每台机器都需要启动
- 前台启动
[root@hadoop01 ~]# cd ~
[root@hadoop01 ~]# /export/server/presto/bin/launcher run
[root@hadoop02 ~]# cd ~
[root@hadoop02 ~]# /export/server/presto/bin/launcher run
#如果出现下面的提示 表示启动成功
2021-09-15T18:24:21.780+0800 INFO main com.facebook.presto.server.PrestoServer ======== SERVER STARTED ========
#前台启动使用ctrl+c进行服务关闭- 后台启动
[root@hadoop01 ~]# cd ~
[root@hadoop01 ~]# /export/server/presto/bin/launcher start
Started as 89560
[root@hadoop02 ~]# cd ~
[root@hadoop02 ~]# /export/server/presto/bin/launcher start
Started as 92288
#查看进程是否启动成功
PrestoServer
#后台启动使用jps 配合kill -9命令 关闭进程- web UI页面 http://192.168.88.80:8090/ui/
- 启动日志
#日志路径:/export/data/presto/var/log/
http-request.log
launcher.log
server.log知识点15:Presto--命令行客户端
- 下载CLI客户端
presto-cli-0.241-executable.jar- 上传客户端到Presto安装包
#上传presto-cli-0.245.1-executable.jar到/export/server/presto/bin
mv presto-cli-0.245.1-executable.jar presto
chmod +x presto- CLI客户端启动
/export/server/presto/bin/presto --server localhost:8090 --catalog hive --schema default
查看数据库:
show schemas;知识点16:Presto--Datagrip连接使用
- JDBC 驱动:presto-jdbc-0.245.1.jar
- JDBC 地址:jdbc:presto://192.168.88.80:8090/hive
Hive和Presto运行效率PK
#Hive中执行:
select city_id,count(*) from yp_dws.dws_sale_daycount group by city_id; -- 39s
#presto中执行:
select city_id,count(*) from hive.yp_dws.dws_sale_daycount group by city_id; -- 4s
-- 通过观察发现,presto的查询速度可以10倍于hive执行速度知识点17:Presto--时间日期类型注意事项
- date_format(timestamp, format) ==> varchar
- 作用: 将指定的日期对象转换为字符串操作
- date_parse(string, format) → timestamp
- 作用: 用于将字符串的日期数据转换为日期对象
-- hive处理方式:2020/10/10 12:50:50
select from_unixtime(unix_timestamp('2020-10-10 12:50:50') ,'yyyy/MM/dd HH:mm:ss');
-- presto处理方式:2020/10/10 12:50:50
select date_format( timestamp '2020-10-10 12:50:50' , '%Y/%m/%d %H:%i:%s');
-- presto处理的日期必须是标准日期格式:年-月-日 时:分:秒
-- 如果不是标准的日期,则需要使用date_parse先转为标准日期,在进行格式转换
select date_format( date_parse('2020:10:10 12-50-50','%Y:%m:%d %H-%i-%s') ,'%Y/%m/%d %H:%i:%s');
----
注意: 参数一必须是日期对象
所以如果传递的是字符串, 必须将先转换为日期对象:
方式一: 标识为日期对象, 但是格式必须为标准日期格式
timestamp '2020-10-10 12:50:50'
date '2020-10-10'
方式二: 如果不标准,先用date_parse解析成为标准
date_parse('2020-10-10 12:50:50','%Y-%m-%d %H:%i:%s')
扩展说明: 日期format格式说明
年:%Y
月:%m
日:%d
时:%H
分:%i
秒:%s
周几:%w(0..6)- date_add(unit, value, timestamp) → [same as input]
- 作用: 用于对日期数据进行 加 减 操作
- date_diff(unit, timestamp1, timestamp2) → bigint
- 作用: 用于比对两个日期之间差值
select date_add('hour',3,timestamp '2021-09-02 15:59:50');
select date_add('day',-1,timestamp '2021-09-02 15:59:50');
select date_add('month',-1,timestamp '2021-09-02 15:59:50');
select date_diff('year',timestamp '2020-09-02 06:30:30',timestamp '2021-09-02 15:59:50')
select date_diff('month',timestamp '2021-06-02 06:30:30',timestamp '2021-09-02 15:59:50')
select date_diff('day',timestamp '2021-08-02 06:30:30',timestamp '2021-09-02 15:59:50')知识点18:Presto--常规优化
- 数据存储优化
--1)合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
--2)使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
Parquet和ORC一样都支持列式存储,但是Presto对ORC支持更好,而Impala对Parquet支持更好。在数仓设计时,要根据后续可能的查询引擎合理设置数据存储格式。
--3)使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
--4)预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
INSERT INTO table nation_orc partition(p) SELECT * FROM nation SORT BY n_name;
如果需要过滤n_name字段,则性能将提升。
SELECT count(*) FROM nation_orc WHERE n_name=’AUSTRALIA’;- SQL优化
- 列裁剪
- 分区裁剪
- group by优化
- 按照数据量大小降序排列
- order by使用limit
- 用regexp_like代替多个like语句
- join时候大表放置在左边
- 替换非ORC格式的Hive表
知识点19:Presto--内存调优
- 内存管理机制--内存分类
Presto管理的内存分为两大类:user memory和system memory
- user memory用户内存
跟用户数据相关的,比如读取用户输入数据会占据相应的内存,这种内存的占用量跟用户底层数据量大小是强相关的- system memory系统内存
执行过程中衍生出的副产品,比如tablescan表扫描,write buffers写入缓冲区,跟查询输入的数据本身不强相关的内存。- 内存管理机制--内存池
内存池中来实现分配user memory和system memory。
内存池为常规内存池GENERAL_POOL、预留内存池RESERVED_POOL。

1、GENERAL_POOL:在一般情况下,一个查询执行所需要的user/system内存都是从general pool中分配的,reserved pool在一般情况下是空闲不用的。
2、RESERVED_POOL:大部分时间里是不参与计算的,但是当集群中某个Worker节点的general pool消耗殆尽之后,coordinator会选择集群中内存占用最多的查询,把这个查询分配到reserved pool,这样这个大查询自己可以继续执行,而腾出来的内存也使得其它的查询可以继续执行,从而避免整个系统阻塞。
注意:
reserved pool到底多大呢?这个是没有直接的配置可以设置的,他的大小上限就是集群允许的最大的查询的大小(query.total-max-memory-per-node)。
reserved pool也有缺点,一个是在普通模式下这块内存会被浪费掉了,二是大查询可以用Hive来替代。因此也可以禁用掉reserved pool(experimental.reserved-pool-enabled设置为false),那系统内存耗尽的时候没有reserved pool怎么办呢?它有一个OOM Killer的机制,对于超出内存限制的大查询SQL将会被系统Kill掉,从而避免影响整个presto。- 内存相关参数
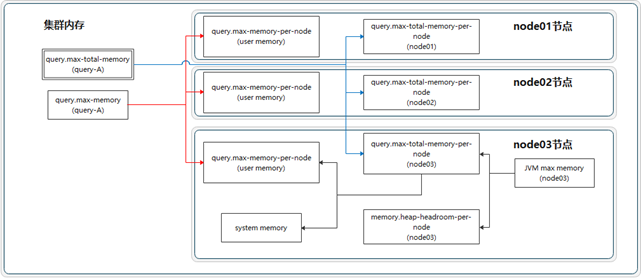
1、user memory用户内存参数
query.max-memory-per-node:单个query操作在单个worker上user memory能用的最大值
query.max-memory:单个query在整个集群中允许占用的最大user memory
2、user+system总内存参数
query.max-total-memory-per-node:单个query操作可在单个worker上使用的最大(user + system)内存
query.max-total-memory:单个query在整个集群中允许占用的最大(user + system) memory
当这些阈值被突破的时候,query会以insufficient memory(内存不足)的错误被终结。
3、协助阻止机制
在高内存压力下保持系统稳定。当general pool常规内存池已满时,操作会被置为blocked阻塞状态,直到通用池中的内存可用为止。此机制可防止激进的查询填满JVM堆并引起可靠性问题。
4、其他参数
memory.heap-headroom-per-node:这个内存是JVM堆中预留给第三方库的内存分配,presto无法跟踪统计,默认值是-Xmx * 0.3
5、结论
GeneralPool = 服务器总内存 - ReservedPool - memory.heap-headroom-per-node - Linux系统内存
常规内存池内存大小=服务器物理总内存-服务器linux操作系统内存-预留内存池大小-预留给第三方库内存- 内存优化建议
- 常见的报错解决
1、Query exceeded per-node total memory limit of xx
适当增加query.max-total-memory-per-node。
2、Query exceeded distributed user memory limit of xx
适当增加query.max-memory。
3、Could not communicate with the remote task. The node may have crashed or be under too much load
内存不够,导致节点crash,可以查看/var/log/message。- 建议参数设置
1、query.max-memory-per-node和query.max-total-memory-per-node是query操作使用的主要内存配置,因此这两个配置可以适当加大。
memory.heap-headroom-per-node是三方库的内存,默认值是JVM-Xmx * 0.3,可以手动改小一些。
1) 各节点JVM内存推荐大小: 当前节点剩余内存*80%
2) 对于heap-headroom-pre-node第三方库的内存配置: 建议jvm内存的%15左右
3) 在配置的时候, 不要正正好好, 建议预留一点点, 以免出现问题
数据量在35TB , presto节点数量大约在30台左右 (128GB内存 + 8核CPU)
注意:
1、query.max-memory-per-node小于query.max-total-memory-per-node。
2、query.max-memory小于query.max-total-memory。
3、query.max-total-memory-per-node 与memory.heap-headroom-per-node 之和必须小于 jvm max memory,也就是jvm.config 中配置的-Xmx。