
分布式面向列的NoSQL数据库Hbase(四)
2022/7/21
分布式面向列的NoSQL数据库Hbase(四)
01:课程回顾
- Hbase Java API
- 掌握基本流程:先构建Connection[ZK]、DDL【HbaseAdmin】、DML【Table】
- 掌握核心类:Put、Get、Delete、Scan、ResultScanner、Result、Cell
- Hbase 存储结构
- 概念
- Table:逻辑上操作对象,Table是分布式的概念,用于客户端读写数据对象
- Region:物理上存储数据对象,Region代表每个分区,默认每张表只有1个Region,每个Region存储在不RS
- RegionServer:Hbase从节点进程,负责管理表的Region,接受所有Region的读写请求
- Hbase分布式的划分规则
- 基本原则:表的每一个分区都有一个范围,所有分区的范围合并在一起一定是-oo ~ +oo
- 分区规则:按照Rowkey属于哪个Region的范围,就读写哪个Region
- 设计目的:构建表中数据的全局有序,加快读取的性能
- Hbase基于HDFS查询性能慢的问题,怎么解决?
- Rowkey:作为索引、Rowkey有序
- 列族的设计
- 积极使用内存:优先读Memstore、允许构建读缓存BlockCache
- 写入HDFS的文件是二进制的HFILE文件
- 读写流程
- 写:先追加写WAL【Hlog】、写入内存【只做新增,逻辑上更新和删除】
- Flush:将内存中的数据写入HDFS
- Compaction:将多个文件合并为整体有序大文件,清理无用数据
- Split:一个分区的数据过多,读写性能降低,通过Split提高并行度
- 读:先读Memstore【写缓存】,再读BlockCache【读缓存】,最后读StoreFile
- 元数据检索流程:管理元数据【Zookeeper】、表的元数据【hbase:meta】
- 写:先追加写WAL【Hlog】、写入内存【只做新增,逻辑上更新和删除】
- 存储结构
- Table | RegionServer
- |
- Region:表的分区
- |
- Store:按照列族划分
- |
- Memstore:内存区域
- StoreFile:逻辑上属于Store,物理上存储在HDFS中的HFILE文件
- Table | RegionServer
- 热点问题
- 现象:存储不均衡,导致了读写都集中在某个Region上,其他Region相对来说比较空闲
- 原因:1-没有预分区,2-分区范围没有按照Rowkey设计 , 3-rowkey是连续的
- 解决:1-建表的时候按照rowkey构建预分区,2-设计不连续的rowkey
- Hbase表的设计
- rowkey:业务原则、唯一原则、组合原则、散列原则【加盐】、长度原则
- columnfamily:个数原则【按照列的个数来设计】、长度原则
- 概念
02:课程目标
- BulkLoad和基础优化
- 目标:掌握Bulkload功能和应用场景
- SQL on Hbase
- 目标:掌握Hbase使用过程中的问题以及解决方案
【模块二:Hive on Hbase】
08:【了解】Hive on Hbase 介绍
- 目标:了解Hive on Hbase的实现原理
- 实施
- 问题:hbase使用层面的问题
- 1-Hbase不支持SQL,使用成本较高,Hbase使用受到了限制
- 解决问题:SQL on Hbase
- 2-Hbase为了解决性能问题,基于Rowkey做了核心设计,Rowkey作为唯一索引,如果不知道Rowkey前缀,只能全表扫描
- 解决问题:二级索引
- 功能:实现Hive与Hbase集成,使用Hive SQL对Hbase的数据进行处理
- Hbase:itcast:t1:原始数据表 |
- Hive:itcast.t1:Hbase的关联表 |
- 用户可以通过SQL操作Hive中表,底层是MR操作对应的Hbase表
- SQL读写Hive中的表,而Hive表指向了Hbase的表
- Hive会调用Hbase读写的类来对Hbase的数据进行读写
- 原理:在Hive中对Hbase关联的Hive表执行SQL语句,底层通过Hadoop中的Input和Output对Hbase表进行处理
- Hadoop中InputFormat和OutputFormat
- 读写文件:TextInputFormat、TextOutputFormat
- 读写数据库:DBInputFormat、DBOutputFormat
- 读写Hbase:TableInputFormat、TableOutputFormat
- 特点
- 优点:支持完善的SQL语句,可以实现各种复杂SQL的数据处理及计算,通过分布式计算程序实现,对大数据量的数据处理比较友好
- 缺点:不支持二级索引,单纯读写的性能不高,不适合做即席查询
- 应用
- 基于大数据高性能的离线读写,并且使用SQL来开发
- 离线场景下,为了提高离线的存储性能
- 问题:hbase使用层面的问题
- 小结:了解Hive on Hbase的实现原理
09:【实现】Hive on Hbase 配置
- 目标:实现Hive on Hbase配置
- 实施
- 修改hive-site.xml:Hive通过SQL访问Hbase,就是Hbase的客户端,就要连接zookeeper
cd /export/server/hive
vim conf/hive-site.xml- 修改hive-env.sh:便于Hive加载Hbase的库包
vim conf/hive-env.sh- 启动HDFS、ZK、Hbase:第一台机器
start-dfs.sh
start-zk-all.sh
start-hbase.sh- 启动Hive和YARN==【没有对应脚本,按照自己启动的方式去启动Hive】==
#启动YARN
start-yarn.sh
#先启动metastore服务
hive-daemon.sh metastore
#然后启动hiveserver
hive-daemon.sh hiveserver2
#然后启动beeline
start-beeline.sh
- 小结:实现Hive on Hbase配置
10:【实现】Hive on Hbase 测试
- 目标:实现Hive on Hbase的测试
- 实施
- 如果Hbase中表已存在,只能创建外部表
--创建测试数据库
create database course;
use course;
--创建测试表
create external table course.t1(
key string,
name string,
age string,
addr string,
phone string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = ":key,basic:name,basic:age,other:addr,other:phone")
tblproperties("hbase.table.name" = "itcast:t1");- 查询
select * from t1;
select age,count(*) as cnt from t1 group by age order by cnt desc;- 注意
- Hive中的只是关联表,并没有数据,数据存储在Hbase表中
- 在Hive中创建Hbase的关联表,关联成功后,使用SQL通过MapReduce处理关联表
- 如果Hbase中表已存在,只能建外部表,使用:key来表示rowkey
- Hive中与Hbase关联的表,不能使用load写入数据,只能使用insert,通过MR读写数据
- 小结:实现Hive on Hbase的测试
【模块三:Phoenix的介绍及部署】
11:【了解】Phoenix的介绍
- 目标:了解Phoenix的功能及应用场景
- 实施
- http://phoenix.apache.org/
- 功能
- 专门基于Hbase所设计的SQL on Hbase 工具
- 使用Phoenix实现基于SQL操作Hbase:解决了问题1
- 使用Phoenix构建二级索引并自动维护二级索引:解决问题2
- 原理
- 上层提供了SQL接口:底层全部通过Hbase Java API来实现,通过构建一系列的Scan和Put来实现数据的读写
- 功能非常丰富:底层封装了大量的内置的协处理器,可以实现各种复杂的处理需求,例如二级索引等
- 特点
- 优点
- 支持SQL接口
- 功能强大:支持自动维护二级索引、创建函数
- 缺点
- SQL支持的语法不友好,不是通用性SQL
- Bug比较多:对Hbase版本集成要求比较高
- Hive on Hbase对比
- Hive:SQL更加全面【底层MR】,但是不支持二级索引,底层通过分布式计算工具来实现
- Phoenix:SQL相对支持不全面【没有计算引擎】,但是性能比较好,直接使用HbaseAPI,支持索引实现
- 优点
- 应用:对Hbase的即席查询和索引管理
- Phoenix适用于任何需要使用SQL或者JDBC来快速的读写Hbase的场景
- 或者需要构建及维护二级索引场景
- 小结:了解Phoenix的功能及应用场景
12:【实现】Phoenix的安装配置
- 目标:安装部署配置Phoenix,集成Hbase
- 实施
- 下载:http://phoenix.apache.org/download.html
- 第一台机器上传
cd /export/software/
rz- 第一台机器解压
tar -zxf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /export/server/
cd /export/server/
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix-5.0.0-HBase-2.0-bin- 修改三台Linux文件句柄数
vim /etc/security/limits.conf
#在文件的末尾添加以下内容,*号不能去掉
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096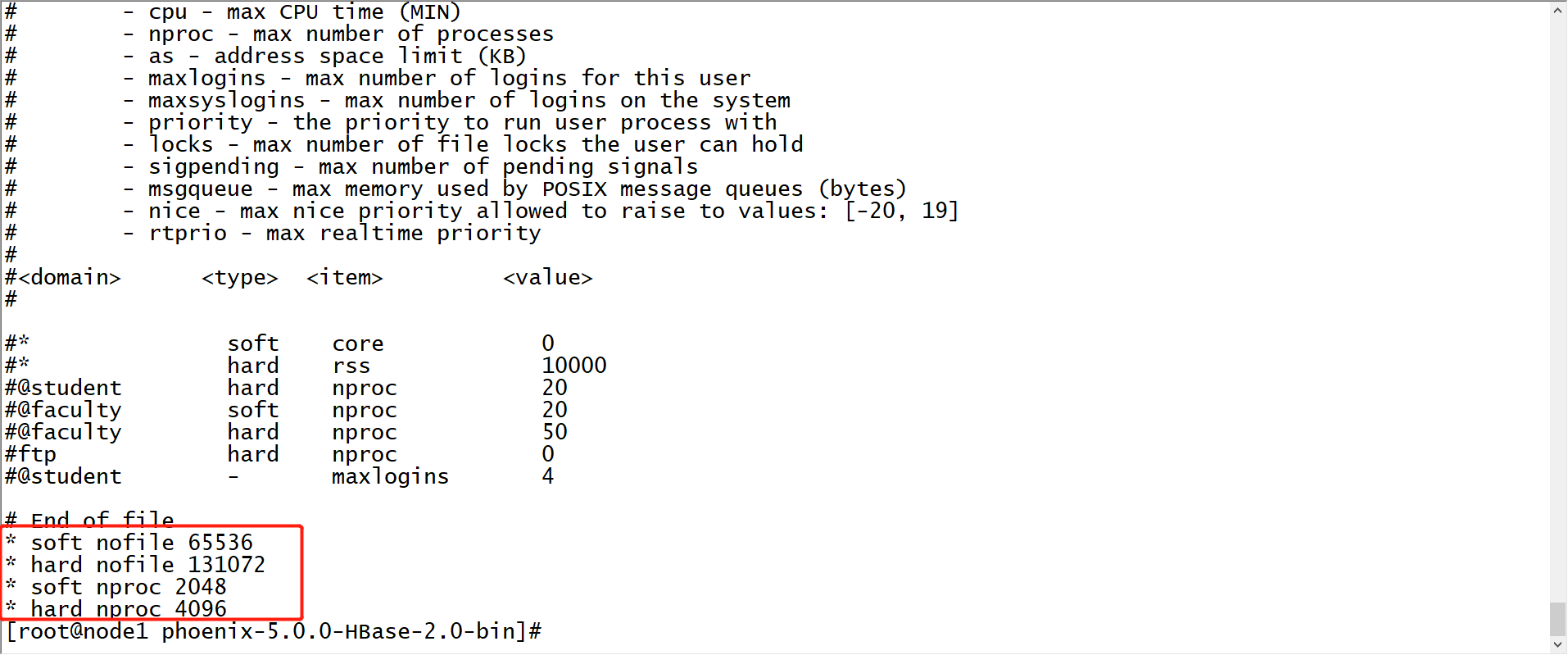
- 将Phoenix所有jar包分发到Hbase的lib目录下
#拷贝到第一台机器
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
cp phoenix-* /export/server/hbase-2.1.0/lib/
#分发给第二台和第三台
cd /export/server/hbase-2.1.0/lib/
scp phoenix-* node2:$PWD
scp phoenix-* node3:$PWD- 修改hbase-site.xml,添加一下属性
cd /export/server/hbase-2.1.0/conf/
vim hbase-site.xml- 同步给其他两台机器
scp hbase-site.xml node2:$PWD
scp hbase-site.xml node3:$PWD- 同步给Phoenix
rm -rf /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/hbase-site.xml
cp hbase-site.xml /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/- 重启Hbase
stop-hbase.sh
start-hbase.sh- 安装依赖
yum -y install python-argparse- 注意:如果默认的是Python3,启动会报错,将这个文件中的python进行修改
vim /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/sqlline.py
- 启动Phoenix
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
bin/sqlline.py node1:2181- 测试
!tables- 退出
!quit
- 小结:实现Phoenix的安装配置
附录一:Maven依赖
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<!-- JUnit 4 依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!-- phoenix core -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<!-- phoenix 客户端 -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
</dependencies>