
实时存储综合案例(二)
2022/7/24
实时存储综合案例(二)
知识点01:课程回顾
- Flume功能和应用场景
- 功能:实现实时数据流的采集
- 场景:实时采集文件或者监听网络端口
- Flume的开发规则和常用组件
- 规则:开发一个配置文件:Agent、Source、Channel、Sink,运行配置文件:flume-ng agent -c、-f、-n
- 常用:三大基本组件
- Source:采集数据:Taildir
- Channel:缓存数据:File、Mem
- Sink:发送数据:HDFS、Kafka
- 流程:先分析选择哪种组件,开发配置文件【官网】、运行【后台】
nohup 命令 >> /flume/logs/程序名字.log &- 额外:工作中如果使用到了Flume:架构、高级组件【Sink Groups、Interceptors】
知识点02:课程目标
- 实现整个聊天数据分析的案例
- 目标:通过案例学习掌握每个工具在工作中具体的使用场景
【模块一:案例架构及数据采集实现】
知识点03:案例需求及数据来源
- 目标:了解案例的背景及需求
- 实施
- 案例背景
社交软件每天都有数千万的用户进行聊天, 陌陌、微信、脸书等公司想要对这些用户的聊天记录进行存储,满足用户的所有查询浏览以及后台需要对每天的消息量进行实时统计分析, 请设计如何实现数据的存储以及实时的数据统计分析工作。- 整体目标
- 选择合理的存储容器进行数据存储, 并让其支持即席查询与分析工作
- 具体需求
- 数据存储:持久化存储
- 离线分析:满足离线统计分析与即时查询
- 离线分析:对数据进行统计分组聚合
- 即席查询:只做基本读取,要求高性能
- 实时分析:满足实时分析,最终构建实时报表
- 实时统计消息总量
- 实时统计各个地区发送消息的总量
- 实时统计各个地区接收消息的总量
- 实时统计每个用户发送消息的总量
- 实时统计每个用户接收消息的总量
- 效果:实现实时可视化报表

- 数据源
- 数据格式
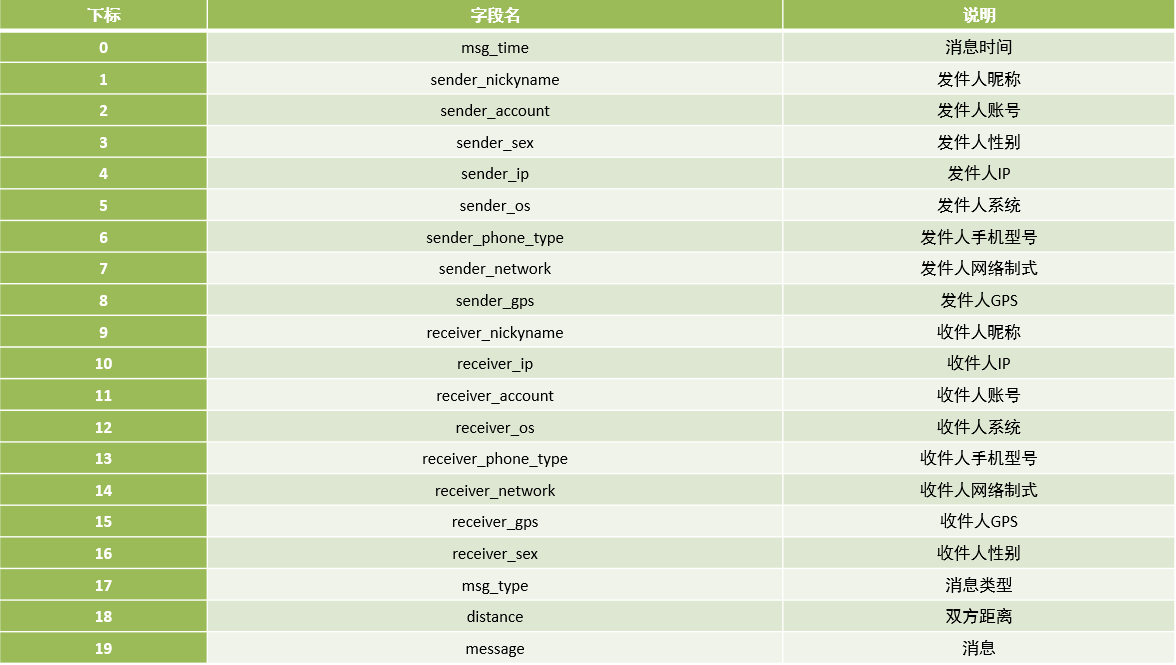
- 数据源
- 业务数据:公司所有业务相关数据:订单、用户、商品等
- 日志数据:用户行为、机器和服务日志、爬虫数据、第三方数据
- 数据生成
- 创建原始文件目录
- 数据格式
mkdir /export/data/momo_init - 上传模拟数据程序
cd /export/data/momo_init
rz
- 创建模拟数据目录
mkdir /export/data/momo_data - 语法
java -jar /export/data/momo_init/MoMo_DataGen.jar 原始数据路径 模拟数据路径 随机产生数据间隔ms时间 - 测试:每500ms生成一条数据
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
500 - 结果:生成模拟数据文件MOMO_DATA.dat,并且每条数据中字段分隔符为\001
- 小结:了解案例的需求及数据来源
知识点04:技术架构及技术选型
- 目标:掌握实时案例的技术架构及技术选型
- 实施
- 需求分析
- 离线
- 离线存储:大数据量的持久性将聊天记录进行存储**【Hbase】**
- 离线计算
- 提供离线T + 1的统计分析:分布式计算程序做分布式计算处理
- Hive on Hbase
- 提供离线数据的即时查询:提供高性能的查询
- Phoenix on Hbase
- 提供离线T + 1的统计分析:分布式计算程序做分布式计算处理
- 实时
- 提供实时统计分析,并构建实时报表
- 实时采集:Flume
- 实时存储:Kafka
- 实时计算:Flink
- 实时结果:MySQL / Redis
- 实时报表:FineBI / 自己开发报表系统
- 离线
- 技术选型
- 采集:Flume
- MQ:Kafka
- 离线存储:Hbase
- 离线计算:Hive和Phoenix
- 实时计算:Flink
- 实时应用:MySQL + FineBI / Redis + 自定义可视化平台【Echarts、HighCharts】
- 技术架构
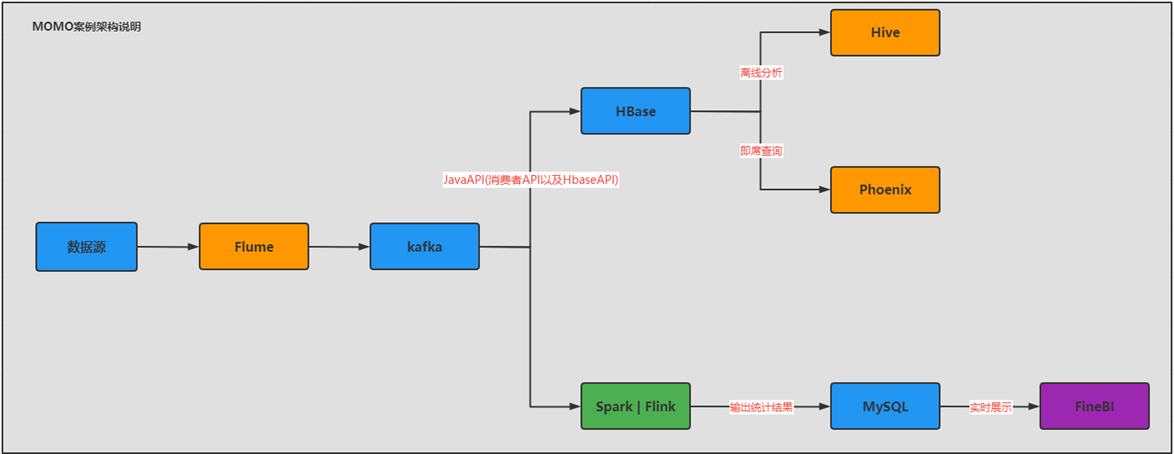
- 为什么不直接将Flume的数据给Hbase,而统一的给了Kafka,再由Kafka到Hbase?
- 基于生产和消费之间,引入Kafka,做了解耦
- 异步提高了性能,避免故障性问题
- 为什么不直接将Flume的数据给Hbase,而统一的给了Kafka,再由Kafka到Hbase?
- 需求分析
- 小结:掌握实时案例的技术架构及技术选型
知识点05:Flume案例采集程序开发
- 目标:实现案例Flume采集程序的开发
- 实施
- 需求分析
- 需求:采集聊天数据文件,实时写入Kafka
- 数据源:/export/data/momo_data/ MOMO_DATA.dat
- 目标地:Kafka
- Source:Taildir Source
- Channel:mem
- Sink:Kafka sink【生产者】
- 需求:采集聊天数据文件,实时写入Kafka
- 需求分析
type = org.apache.flume.sink.kafka.KafkaSink
kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
kafka.topic = 写入哪个Topic
kafka.producer.acks = 1 、 0、-1- 程序开发
vim /export/server/flume-1.9.0-bin/usercase/momo_mem_kafka.properties# define a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define s1
a1.sources.s1.type = TAILDIR
#指定一个元数据记录文件
a1.sources.s1.positionFile = /export/server/flume-1.9.0-bin/position/taildir_momo_kafka.json
#将所有需要监控的数据源变成一个组
a1.sources.s1.filegroups = f1
#指定了f1是谁:监控目录下所有文件
a1.sources.s1.filegroups.f1 = /export/data/momo_data/.*
#指定f1采集到的数据的header中包含一个KV对
a1.sources.s1.headers.f1.type = momo
a1.sources.s1.fileHeader = true
#define c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#define k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = MOMO_MSG
a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 100
#bound
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1- 测试实现
- 启动Kafka
start-zk-all.sh
start-kafka.sh - 创建Topic
kafka-topics.sh --create --topic MOMO_MSG --partitions 3 --replication-factor 2 --bootstrap-server node1:9092,node2:9092,node3:9092 - 列举
kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092 - 启动消费者
kafka-console-consumer.sh --topic MOMO_MSG --bootstrap-server node1:9092,node2:9092,node3:9092 - 启动Flume程序
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_kafka.properties -Dflume.root.logger=INFO,console - 启动模拟数据
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
100 - 观察结果
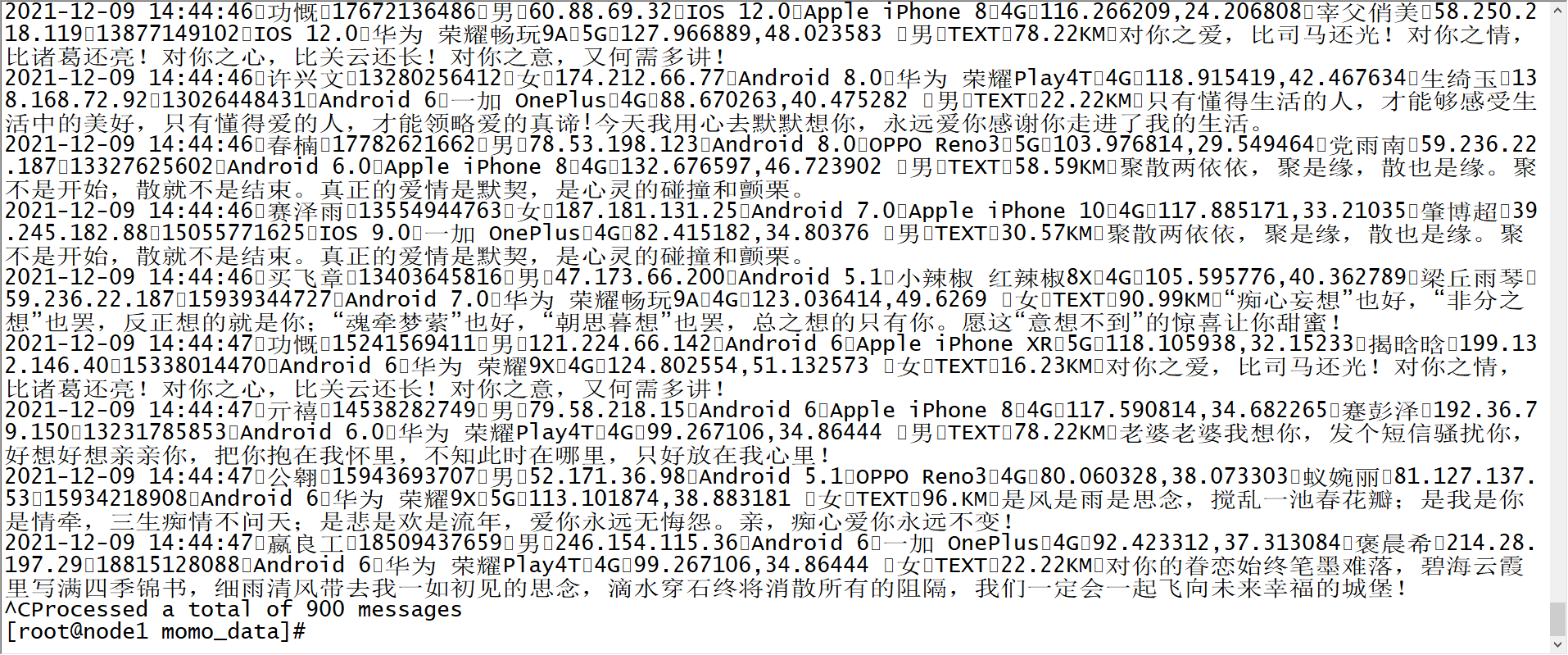
- 小结:实现案例Flume采集程序的开发
【模块二:离线批处理层设计实现】
知识点06:离线分析:Hbase表设计及构建
- 目标:掌握Hbase表的设计及创建表的实现
- 实施
- 基础设计
- Namespace:MOMO_CHAT
- Table:MOMO_MSG
- Family:C1
- Qualifier:与数据中字段名保持一致
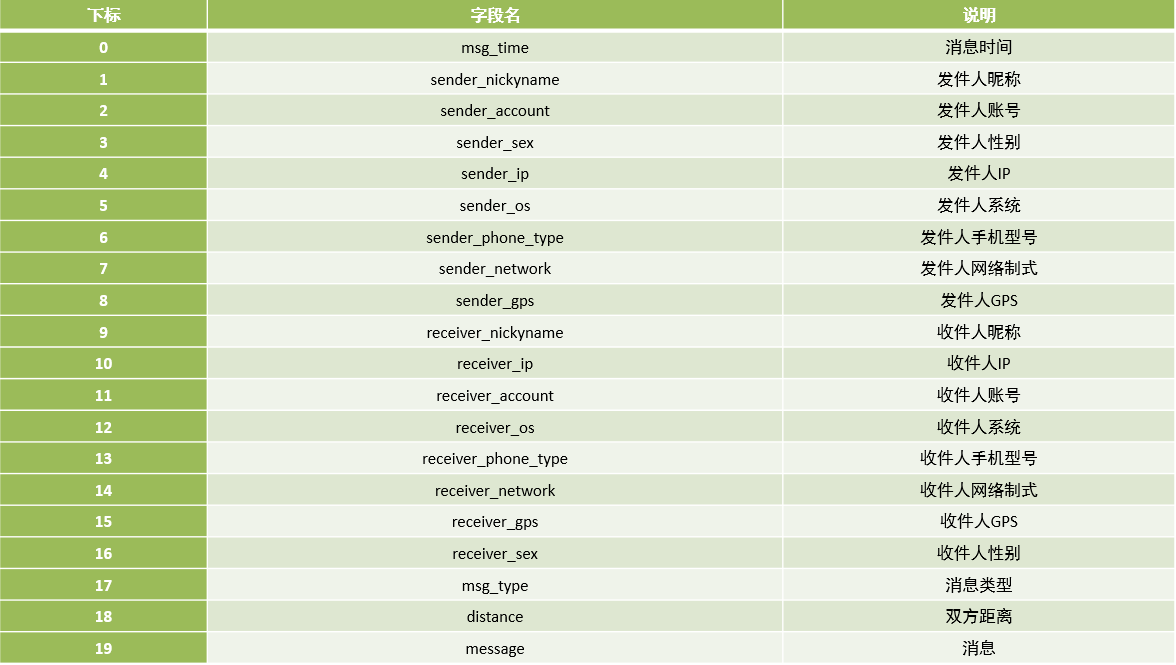
- Rowkey设计
- 设计规则:业务、唯一、长度、散列、组合
- 查询需求:根据发件人id + 收件人id + 消息日期 查询聊天记录
- 发件人账号
- 收件人账号
- 消息时间
- 设计实现
- 加盐方案:CRC、Hash、MD5、MUR
- => 8位、16位、32位
- 基础设计
MD5Hash【发件人账号_收件人账号_消息时间 =》 8位】_发件人账号_收件人账号_消息时间- 分区设计
- Rowkey前缀:MD5编码,由字母和数字构成
- 数据并发量:高
- 分区设计:使用HexSplit16进制划分多个分区
- 建表
- 启动Hbase:start-hbase.sh
- 进入客户端:hbase shell
#创建NS
create_namespace 'MOMO_CHAT'
#建表
create 'MOMO_CHAT:MOMO_MSG', {NAME => "C1", COMPRESSION => "GZ"}, { NUMREGIONS => 6, SPLITALGO => 'HexStringSplit'}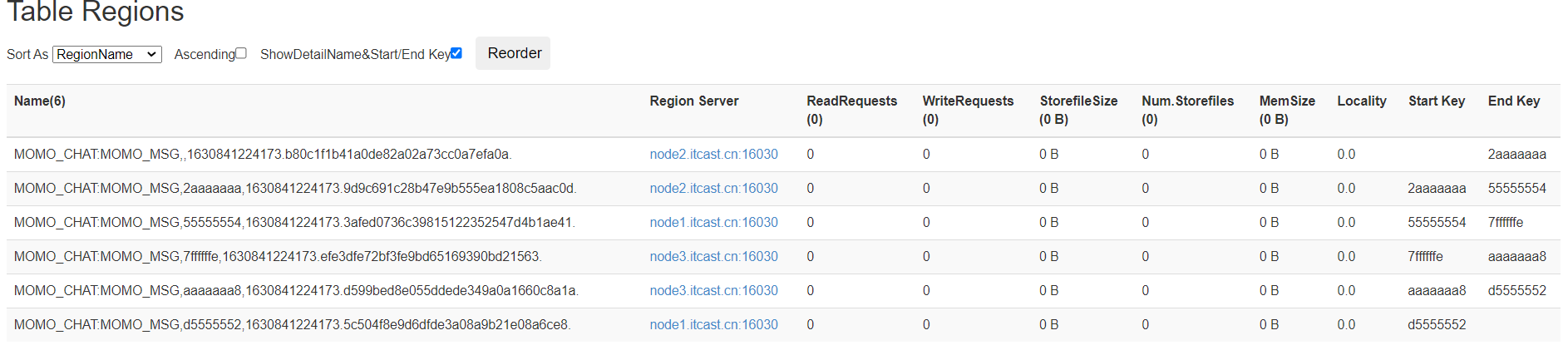
- 小结:掌握Hbase表的设计及创建表的实现
知识点07:离线分析:Kafka消费者构建
- 目标:实现离线消费者的开发
- 实施
- 整体流程
- step1:消费Kafka中的数据
- step2:将每条数据构建Put对象,写入Hbase
- 消费者构建
- 整体流程
/**
* 用于消费Kafka的数据,将合法数据写入Hbase
*/
private static void consumerKafkaToHbase() throws Exception {
//构建配置对象
Properties props = new Properties();
//指定服务端地址
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
//指定消费者组的id
props.setProperty("group.id", "momo");
//关闭自动提交
props.setProperty("enable.auto.commit", "false");
//指定K和V反序列化的类型
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//构建消费者的连接
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//指定订阅哪些Topic
consumer.subscribe(Arrays.asList("MOMO_MSG"));
//持续拉取数据
while (true) {
//向Kafka请求拉取数据,等待Kafka响应,在100ms以内如果响应,就拉取数据,如果100ms内没有响应,就提交下一次请求: 100ms为等待Kafka响应时间
//拉取到的所有数据:多条KV数据都在ConsumerRecords对象,类似于一个集合
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
//todo:3-处理拉取到的数据:打印
//取出每个分区的数据进行处理
Set<TopicPartition> partitions = records.partitions();//获取本次数据中所有分区
//对每个分区的数据做处理
for (TopicPartition partition : partitions) {
List<ConsumerRecord<String, String>> partRecords = records.records(partition);//取出这个分区的所有数据
//处理这个分区的数据
long offset = 0;
for (ConsumerRecord<String, String> record : partRecords) {
//获取Topic
String topic = record.topic();
//获取分区
int part = record.partition();
//获取offset
offset = record.offset();
//获取Key
String key = record.key();
//获取Value
String value = record.value();
System.out.println(topic + "\t" + part + "\t" + offset + "\t" + key + "\t" + value);
//将Value数据写入Hbase
if(value != null && !"".equals(value) && value.split("\001").length == 20 ){
writeToHbase(value);
}
}
//手动提交分区的commit offset
Map<TopicPartition, OffsetAndMetadata> offsets = Collections.singletonMap(partition,new OffsetAndMetadata(offset+1));
consumer.commitSync(offsets);
}
}
}- 构建Hbase连接
private static SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private static Connection conn;
private static Table table;
private static TableName tableName = TableName.valueOf("MOMO_CHAT:MOMO_MSG");//表名
private static byte[] family = Bytes.toBytes("C1");//列族
// 静态代码块: 随着类的加载而加载,一般只会加载一次,避免构建多个连接影响性能
static{
try {
//构建配置对象
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","node1:2181,node2:2181,node3:2181");
//构建连接
conn = ConnectionFactory.createConnection(conf);
//获取表对象
table = conn.getTable(tableName);
} catch (IOException e) {
e.printStackTrace();
}
}- Rowkey的构建
private static String getMomoRowkey(String stime, String sender_accounter, String receiver_accounter) throws Exception {
//转换时间戳
long time = format.parse(stime).getTime();
String suffix = sender_accounter+"_"+receiver_accounter+"_"+time;
//构建MD5
String prefix = MD5Hash.getMD5AsHex(Bytes.toBytes(suffix)).substring(0,8);
//合并返回
return prefix+"_"+suffix;
}- Put数据列构建
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("msg_time"),Bytes.toBytes(items[0]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_nickyname"),Bytes.toBytes(items[1]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_account"),Bytes.toBytes(items[2]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_sex"),Bytes.toBytes(items[3]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_ip"),Bytes.toBytes(items[4]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_os"),Bytes.toBytes(items[5]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_phone_type"),Bytes.toBytes(items[6]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_network"),Bytes.toBytes(items[7]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_gps"),Bytes.toBytes(items[8]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_nickyname"),Bytes.toBytes(items[9]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_ip"),Bytes.toBytes(items[10]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_account"),Bytes.toBytes(items[11]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_os"),Bytes.toBytes(items[12]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_phone_type"),Bytes.toBytes(items[13]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_network"),Bytes.toBytes(items[14]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_gps"),Bytes.toBytes(items[15]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_sex"),Bytes.toBytes(items[16]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("msg_type"),Bytes.toBytes(items[17]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("distance"),Bytes.toBytes(items[18]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("message"),Bytes.toBytes(items[19]));- 存储测试
- 启动消费者程序
- 启动Flume程序
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_kafka.properties -Dflume.root.logger=INFO,console - 启动模拟数据
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
100 - 观察Hbase结果
scan 'MOMO_CHAT:MOMO_MSG',{LIMIT => 1,FORMATTER => 'toString'}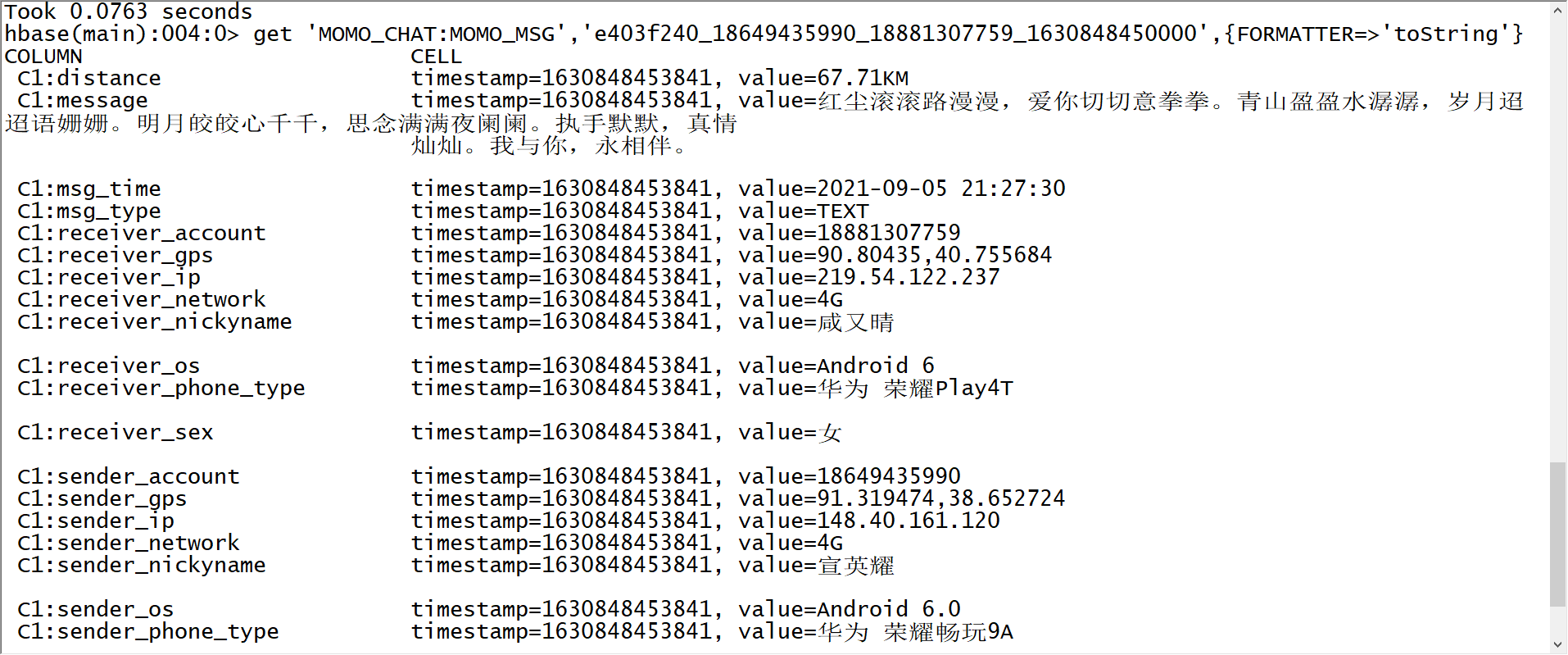
- 小结:实现离线消费者的开发
知识点08:离线分析:Hive及Phoenix关联测试
- 目标:使用Hive关联Hbase实现离线分析
- 实施
- Hive测试
- 启动Hive和yarn
- Hive测试
start-yarn.sh
hive-daemon.sh metastore
hive-daemon.sh hiveserver2
start-beeline.sh - **关联**
create database MOMO_CHAT;
use MOMO_CHAT;
create external table if not exists MOMO_CHAT.MOMO_MSG (
id string,
msg_time string ,
sender_nickyname string ,
sender_account string ,
sender_sex string ,
sender_ip string ,
sender_os string ,
sender_phone_type string ,
sender_network string ,
sender_gps string ,
receiver_nickyname string ,
receiver_ip string ,
receiver_account string ,
receiver_os string ,
receiver_phone_type string ,
receiver_network string ,
receiver_gps string ,
receiver_sex string ,
msg_type string ,
distance string ,
message string
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties('hbase.columns.mapping'=':key,C1:msg_time,C1:sender_nickyname,
C1:sender_account,C1:sender_sex,C1:sender_ip,C1:sender_os,C1:sender_phone_type,
C1:sender_network,C1:sender_gps,C1:receiver_nickyname,C1:receiver_ip,C1:receiver_account,
C1:receiver_os,C1:receiver_phone_type,C1:receiver_network,C1:receiver_gps,C1:receiver_sex,
C1:msg_type,C1:distance,C1:message ') tblproperties('hbase.table.name'='MOMO_CHAT:MOMO_MSG'); - **分析查询**
--基础查询
select
msg_time,sender_nickyname,receiver_nickyname,distance
from momo_msg limit 10;
--查询聊天记录:发送人id + 接收人id + 日期:e72efcdc_15612388730_18743137694_1660481010000
select
*
from momo_msg
where sender_account='15612388730'
and receiver_account='18743137694'
and substr(msg_time,0,10) = '2022-08-14';
--统计每天每个小时的消息数
select
substr(msg_time,0,13) as hour,
count(*) as cnt
from momo_msg
group by substr(msg_time,0,13);- Phoenix测试
- 启动
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
bin/sqlline.py node1:2181 - **关联**
create view if not exists MOMO_CHAT.MOMO_MSG (
"id" varchar primary key,
C1."msg_time" varchar ,
C1."sender_nickyname" varchar ,
C1."sender_account" varchar ,
C1."sender_sex" varchar ,
C1."sender_ip" varchar ,
C1."sender_os" varchar ,
C1."sender_phone_type" varchar ,
C1."sender_network" varchar ,
C1."sender_gps" varchar ,
C1."receiver_nickyname" varchar ,
C1."receiver_ip" varchar ,
C1."receiver_account" varchar ,
C1."receiver_os" varchar ,
C1."receiver_phone_type" varchar ,
C1."receiver_network" varchar ,
C1."receiver_gps" varchar ,
C1."receiver_sex" varchar ,
C1."msg_type" varchar ,
C1."distance" varchar ,
C1."message" varchar
); - **即时查询**
--基础查询
select
"id",c1."sender_account",c1."receiver_account"
from momo_chat.momo_msg
limit 10;
--查询每个发送人发送的消息数
select
c1."sender_account" ,
count(*) as cnt
from momo_chat.momo_msg
group by c1."sender_account";
--查询每个发送人聊天的人数
select
c1."sender_account" ,
count(distinct c1."receiver_account") as cnt
from momo_chat.momo_msg
group by c1."sender_account"
order by cnt desc;- 小结:使用Hive和Phoenix关联Hbase实现离线分析
【模块三:实时处理及实时报表应用】
知识点09:实时架构及Flink的基本介绍
- 目标:了解Flink的功能、特点及应用场景
- 实施
- 实时计算需求
- 实时统计消息总量:总消息的行数
- 实时计算需求
select count(*) from tbname; - 实时统计各个地区发送消息的总量:各个省份发送消息量
select sender_area,count(*) from tbname group by sender_area; - 实时统计各个地区接收消息的总量:各个省份接受消息量
select receiver_area,count(*) from tbname group by receiver_area; - 实时统计每个用户发送消息的总量:各个用户发送消息条数
select sender_account,count(*) from tbname group by sender_account; - 实时统计每个用户接收消息的总量:各个用户接受消息的条数
select receiver_account,count(*) from tbname group by receiver_account; - |
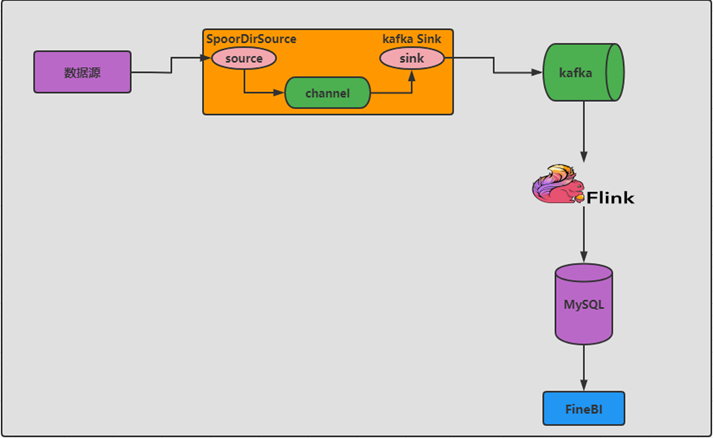
- 构建实时统计报表
- 技术方案
- 实时采集:Flume
- 实时存储:Kafka
- 实时计算:Flink
- 实时结果:MySQL / Redis
- 实时报表:FineBI / JavaWeb可视化
- Flink的介绍
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.- 功能:可以基于任何普通的集群平台,对有界的数据流或者无界的数据流实现高性能的有状态的分布式实时计算
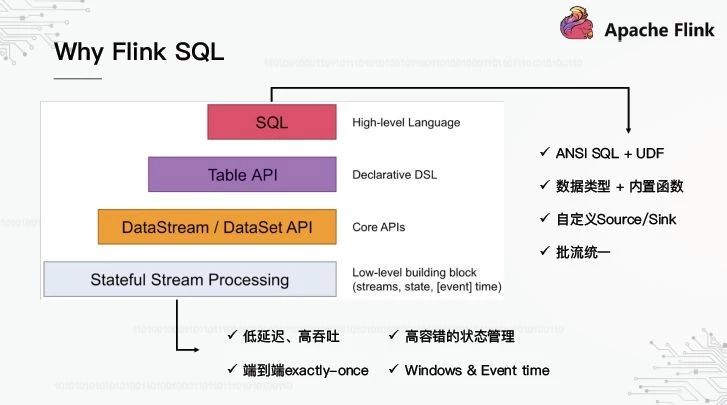
- 特点
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
- 应用:所有实时及离线数据计算场景
- 数据分析应用:实时数据仓库
- Batch analytics(批处理分析)
- Streaming analytics(流处理分析)
- 事件驱动类应用
- 欺诈检测(Fraud detection)
- 异常检测(Anomaly detection)
- 基于规则的告警(Rule-based alerting)
- 业务流程监控(Business process monitoring)
- Web应用程序(社交网络)
- 数据管道ETL
- Periodic ETL和Data Pipeline
- 公司
- 数据分析应用:实时数据仓库
- 小结:了解Flink的功能、特点及应用场景
知识点10:代码模块构建及省份解析测试
- 目标:实现开发环境的代码模块构建
- 实施
- 导入包中代码到IDEA中

- flink包:应用类包,用于存放实际的应用类
- MoMoFlinkCount:用于实现对每个需求的统计计算
- MySQLSink:用于将计算的结果写入MySQL
- pojo包:实体类包,用于存放所有实体类
- MoMoCountBean:用于封装统计分析的结果
- 导入包中代码到IDEA中
private Integer id ; //结果id
private Long moMoTotalCount ; //总消息数
private String moMoProvince ; //省份
private String moMoUsername ; //用户
private Long moMo_MsgCount ; //消息数
//结果类型:1-总消息数 2-各省份发送消息数 3-各省份接受消息数 4-每个用户发送消息数 5-每个用户接受消息数
private String groupType ;- utils包:工具类包,用于存放所有工具类
- HttpClientUtils:用于实现将经纬度地址解析为省份的工具类
public static String findByLatAndLng(String lat , String lng) - 参数:经度,维度
- 返回值:省份
- 基本设计
- 业务场景:根据IP或者经纬度解析得到用户的国家、省份、城市信息
- 方案一:离线解析库【本地解析,快,不精准】
- 方案二:在线解析库【远程解析,并发限制,精准】
- 注册百度开发者
https://api.map.baidu.com/reverse_geocoding/v3/?ak=您的ak&output=json&coordtype=wgs84ll&location=31.225696563611,121.49884033194 //GET请求 - 注册开放平台,获取AK码:参考《附录三》
- 测试省份解析
- 注意:将代码中的AK码更改为自己的
package bigdata.itcast.cn.momo.online.utils;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import javax.swing.text.html.parser.Entity;
import java.io.IOException;
import java.util.Map;
public class HttpClientUtils {
//传入经纬度, 返回查询的地区
public static String findByLatAndLng(String lat , String lng){
try {
CloseableHttpClient httpClient = HttpClients.createDefault();
String url = "http://api.map.baidu.com/reverse_geocoding/v3/?ak=l8hKKRCuX2zrRa93jneDrPmc2UspGatO&output=json&coordtype=wgs84ll&location="+lat+","+lng;
System.out.println(url);
//请求解析
HttpGet httpGet = new HttpGet(url);
//得到结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取数据
HttpEntity httpEntity = response.getEntity();
//转换成JSON
String json = EntityUtils.toString(httpEntity);
//从JSON中返回省份
Map<String,Object> result = JSONObject.parseObject(json, Map.class);
if(result.get("status").equals(0)){
Map<String,Object> resultMap = (Map<String,Object>)result.get("result");
resultMap = (Map<String, Object>) resultMap.get("addressComponent");
String province = (String) resultMap.get("province");
return province;
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
//测试
String sf = findByLatAndLng("43.921297","124.655376");
System.out.println(sf);
}
}
- 小结:实现开发环境的代码模块构建
知识点11:Flink实时计算测试
- 目标:实现Flink实时分析测试
- 实施
- MySQL准备
- 找到SQL文件

- 运行SQL文件创建结果数据库、表
- 找到SQL文件
- MySQL准备
# 上传
cd /export/data
rz
# 进入
mysql -uroot -p
# 导入
source /export/data/momo.sql;
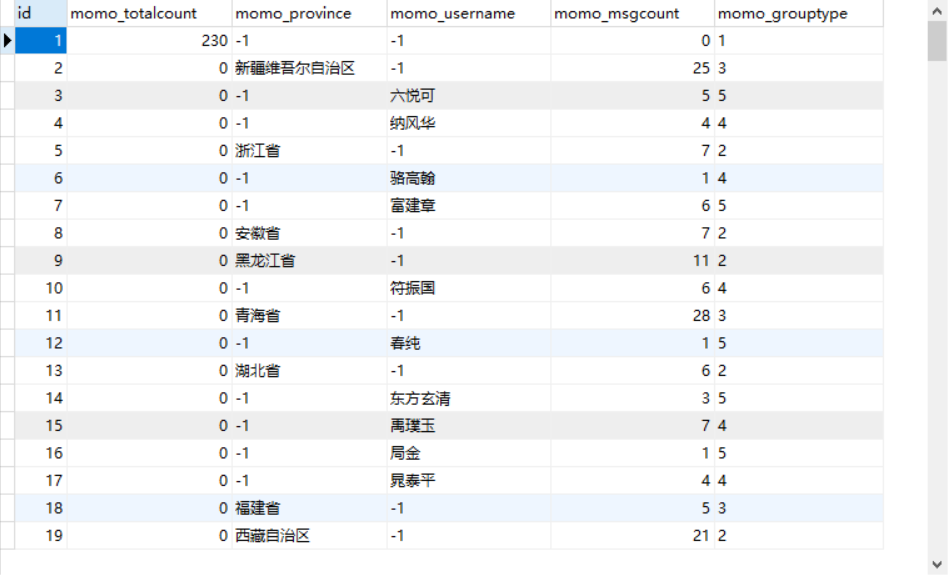
- 运行测试
- 启动Flink程序:运行MoMoFlinkCount
- 启动Flume程序
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_kafka.properties -Dflume.root.logger=INFO,console - 启动模拟数据
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
100 - 观察MySQL结果
- 小结:实现Flink实时分析测试
知识点12:FineBI配置数据集
- 目标:实现FineBI访问MySQL结果数据集的配置
- 实施
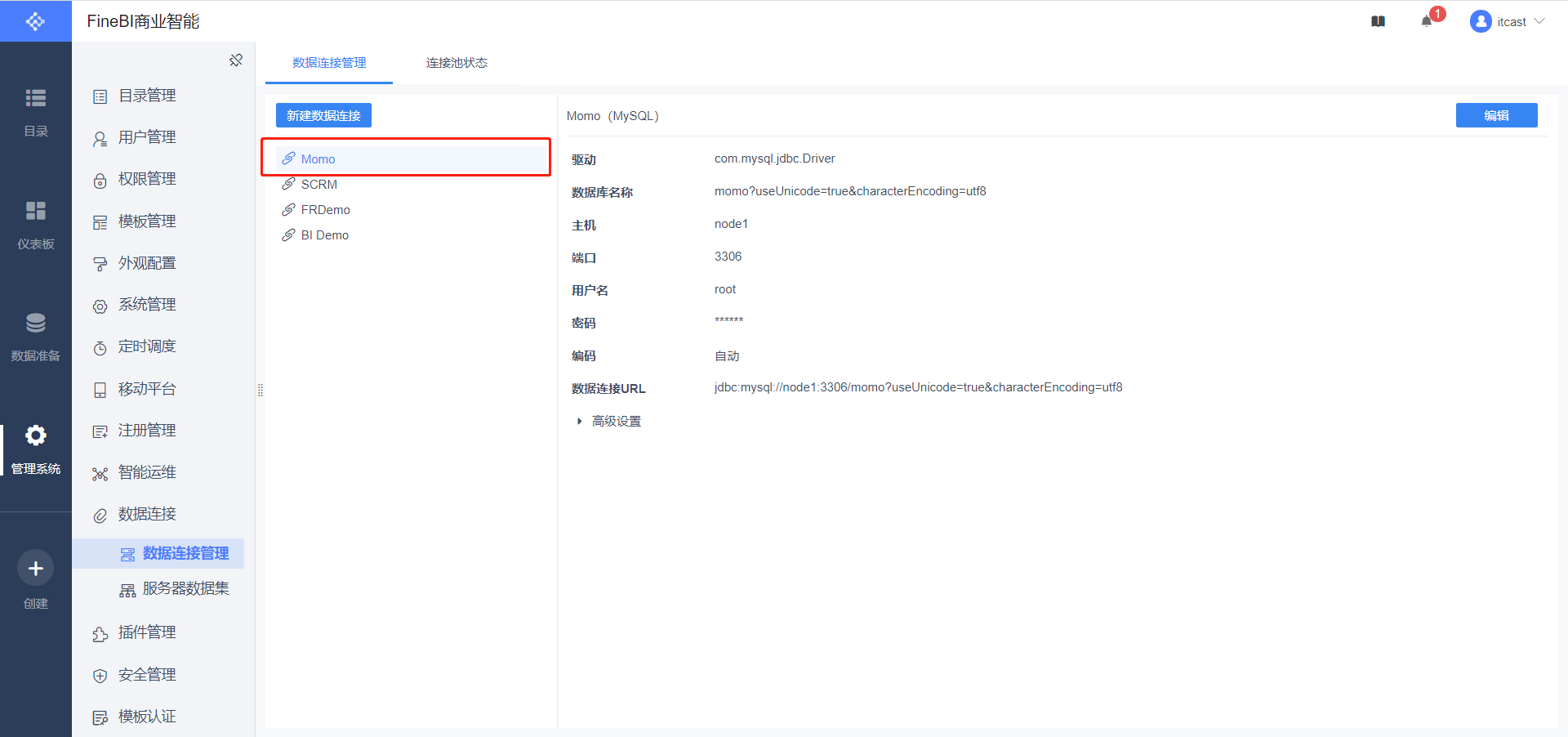
- 配置连接
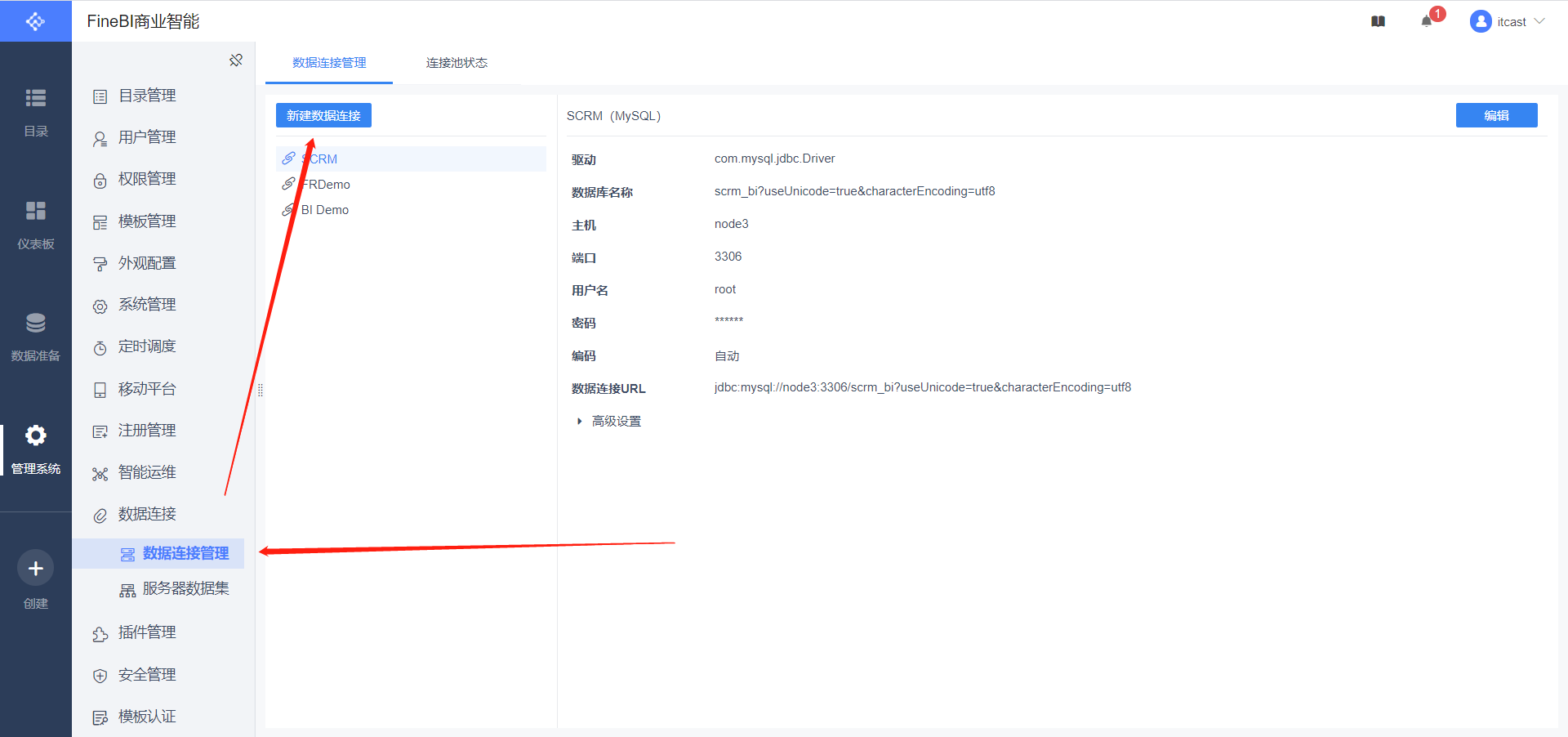
- 配置连接
数据连接名称:Momo
用户名:root
密码:自己MySQL的密码
数据连接URL:jdbc:mysql://node1:3306/momo?useUnicode=true&characterEncoding=utf8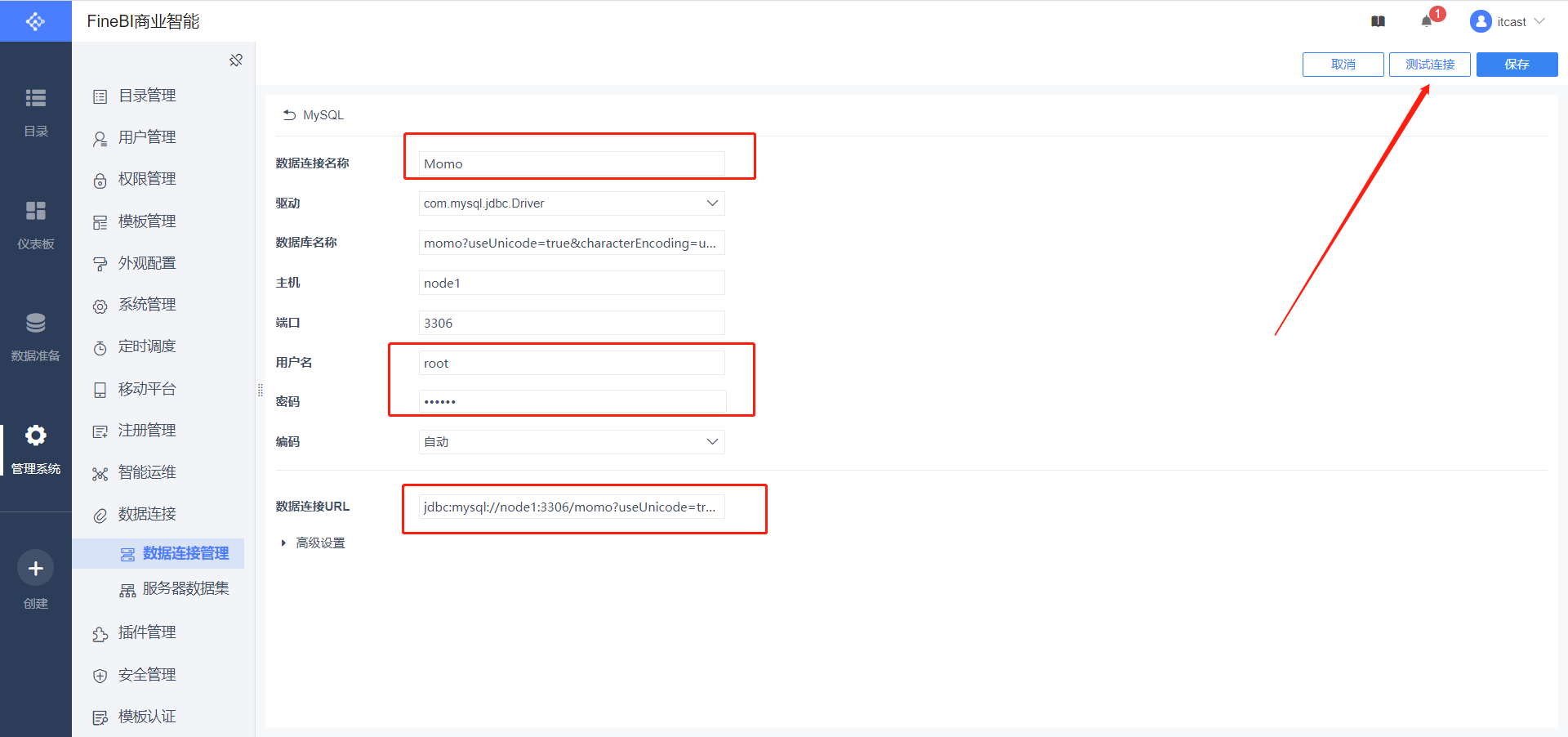
- 数据准备
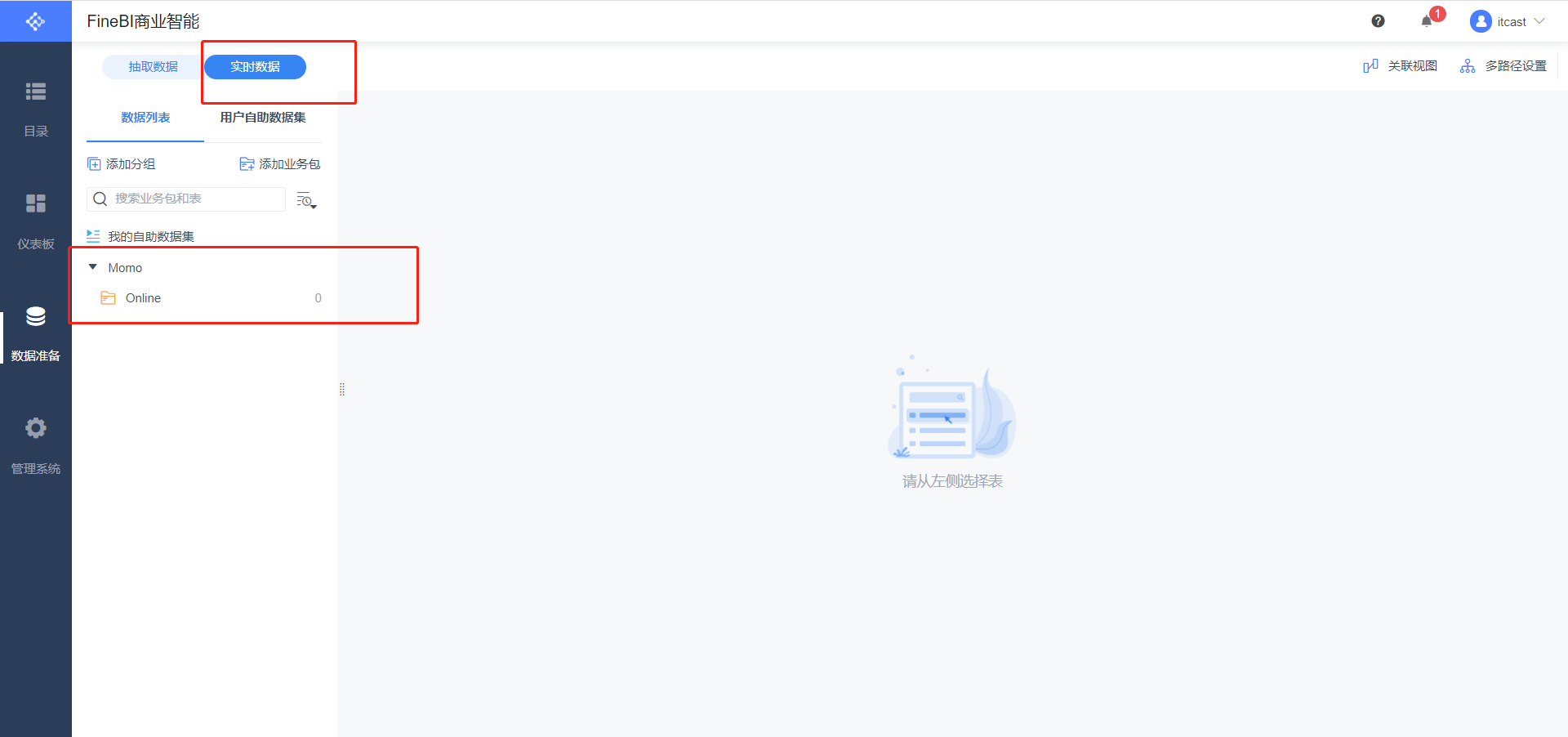
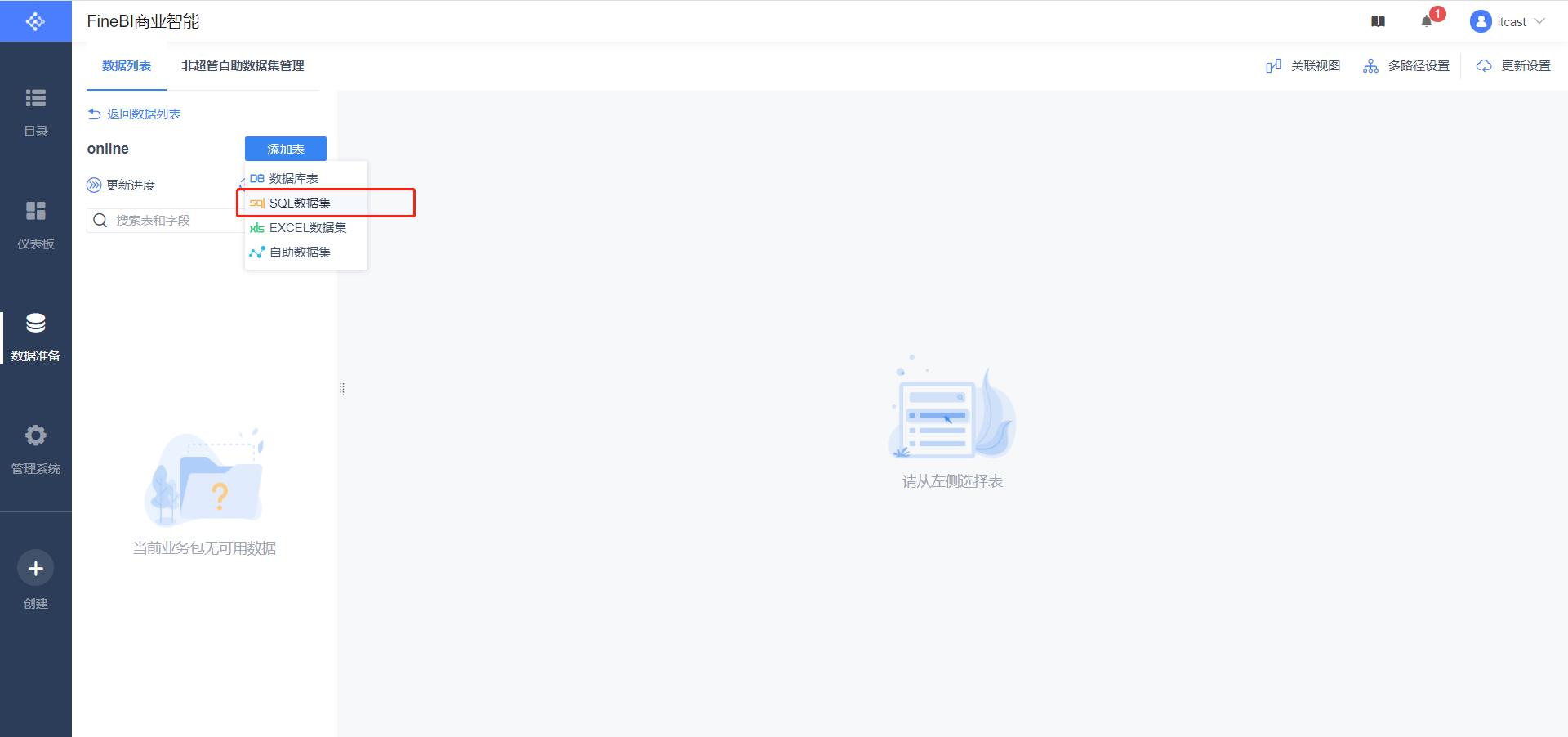
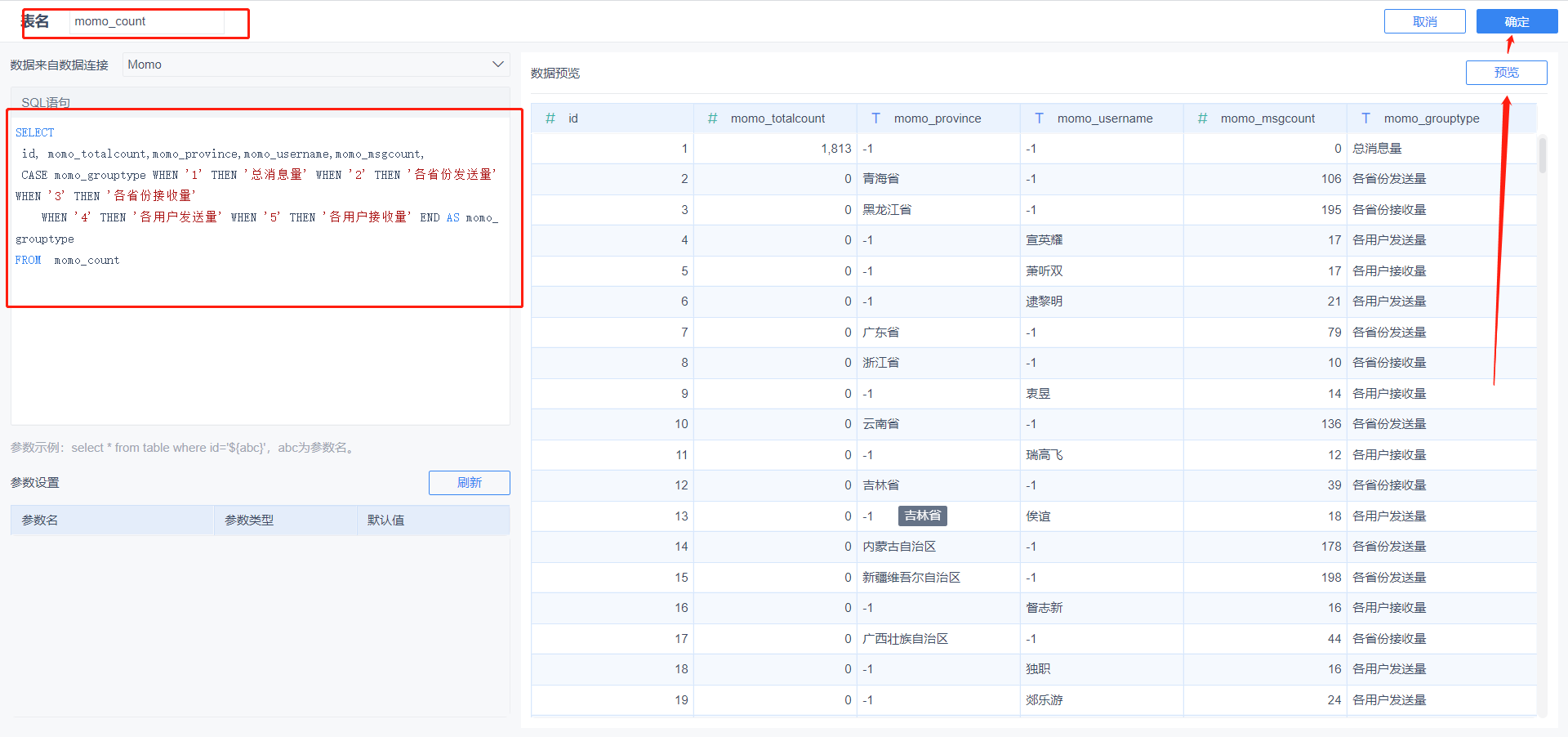
SELECT
id, momo_totalcount,momo_province,momo_username,momo_msgcount,
CASE momo_grouptype WHEN '1' THEN '总消息量' WHEN '2' THEN '各省份发送量' WHEN '3' THEN '各省份接收量'
WHEN '4' THEN '各用户发送量' WHEN '5' THEN '各用户接收量' END AS momo_grouptype
FROM momo_count- 小结:实现FineBI访问MySQL结果数据集的配置
知识点13:FineBI构建报表
- 目标:实现FineBI实时报表构建
- 实施
- 实时报表构建
- 新建仪表盘
- 新建仪表盘
- 实时报表构建
- 添加标题
- 实时总消息数
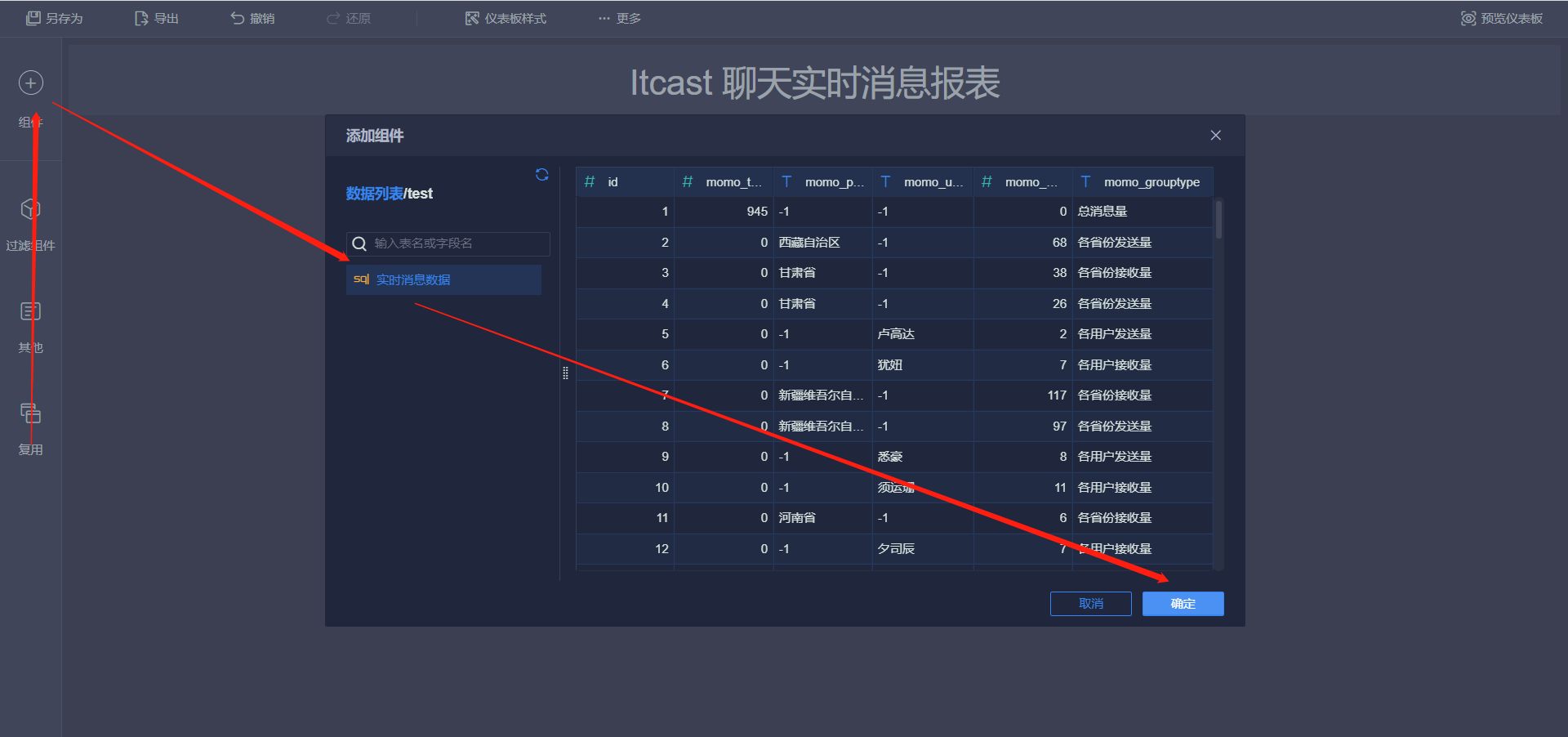
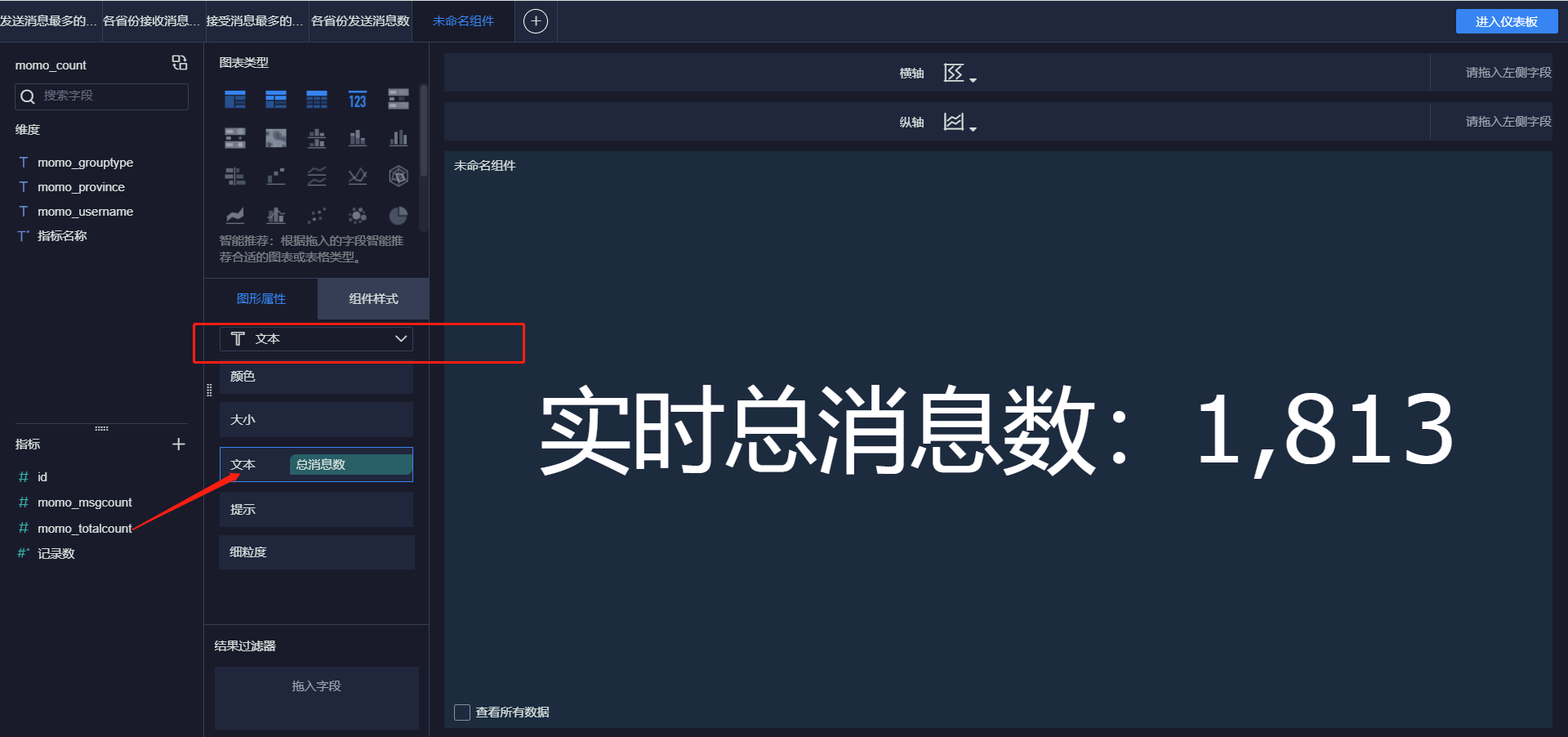
- 发送消息最多的Top10用户
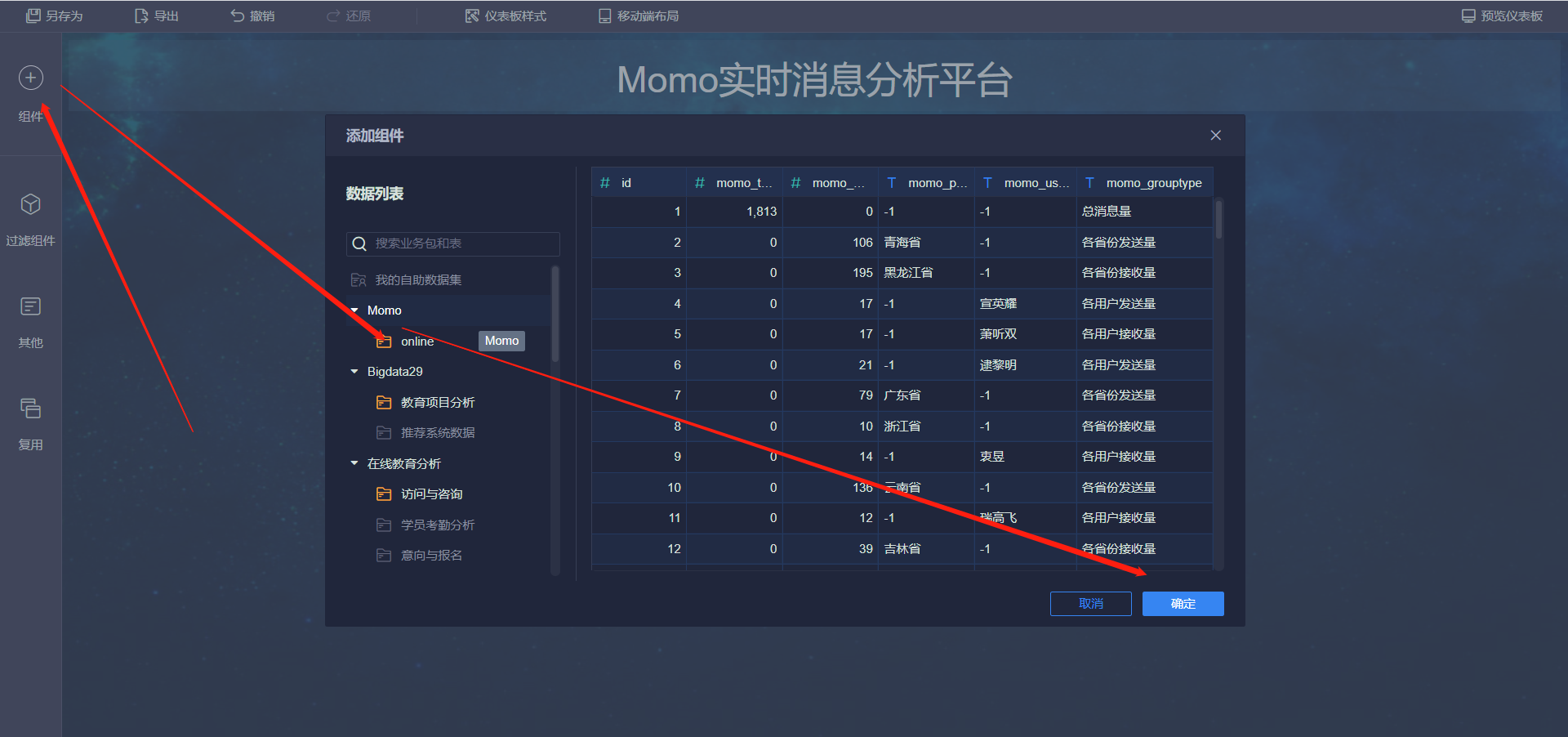
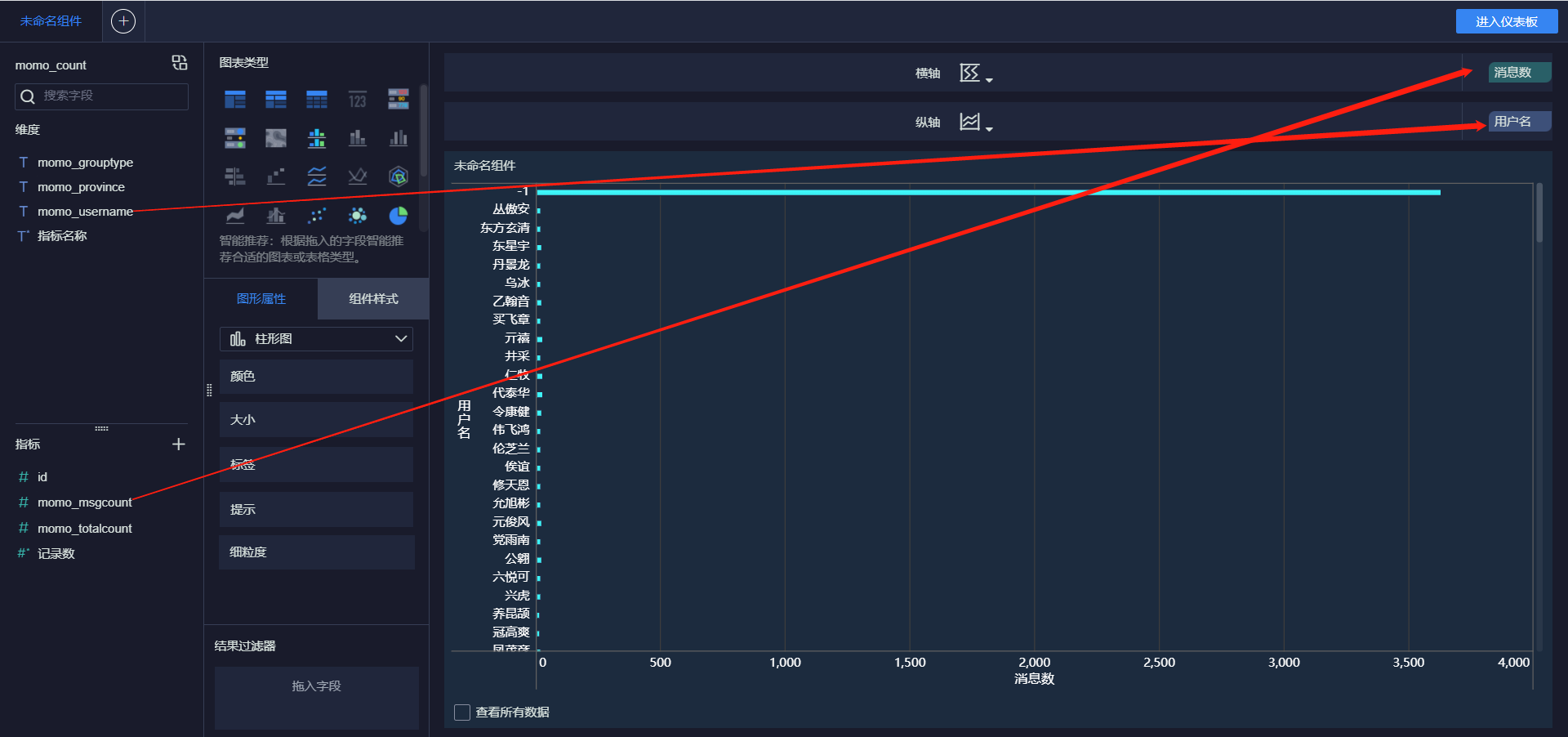
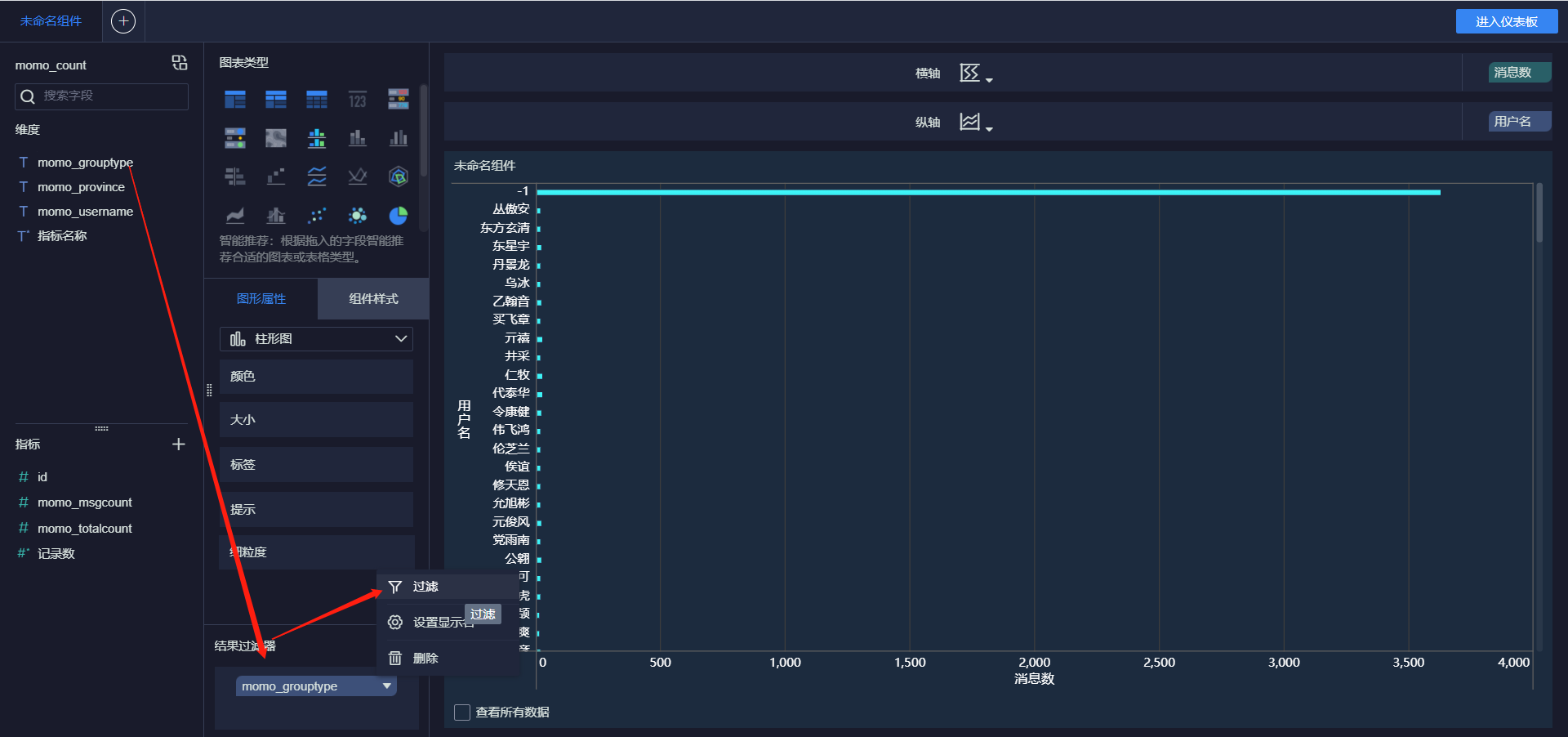
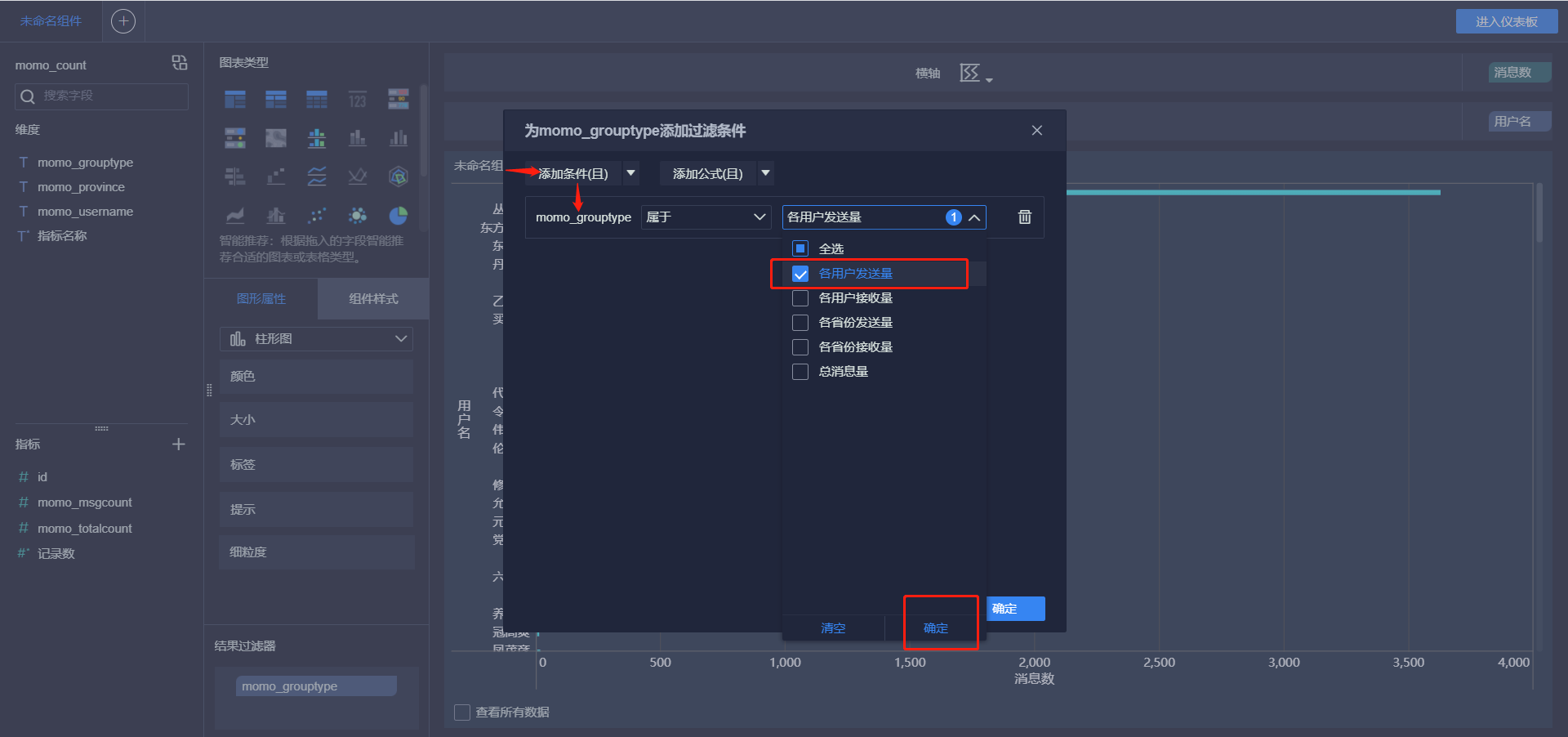
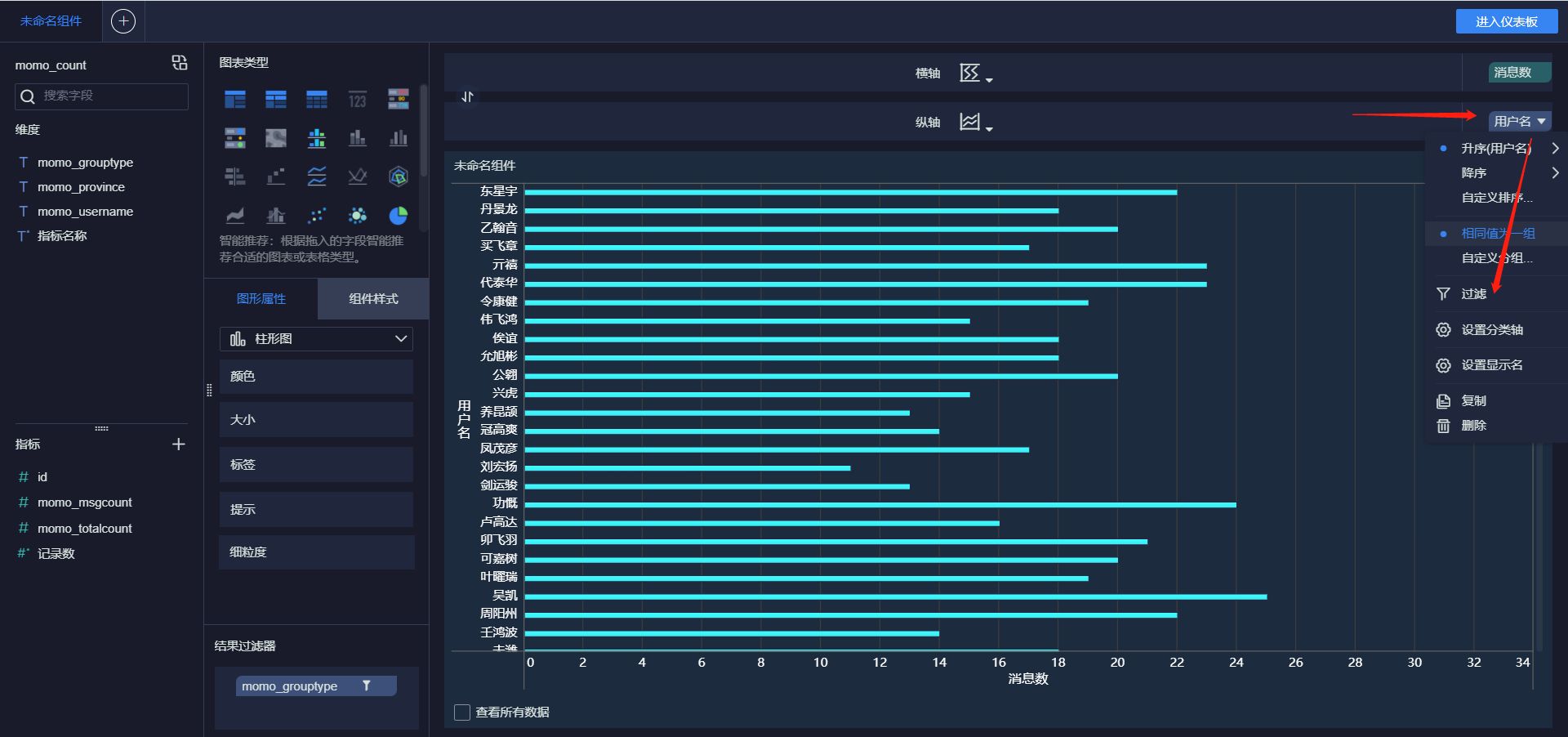
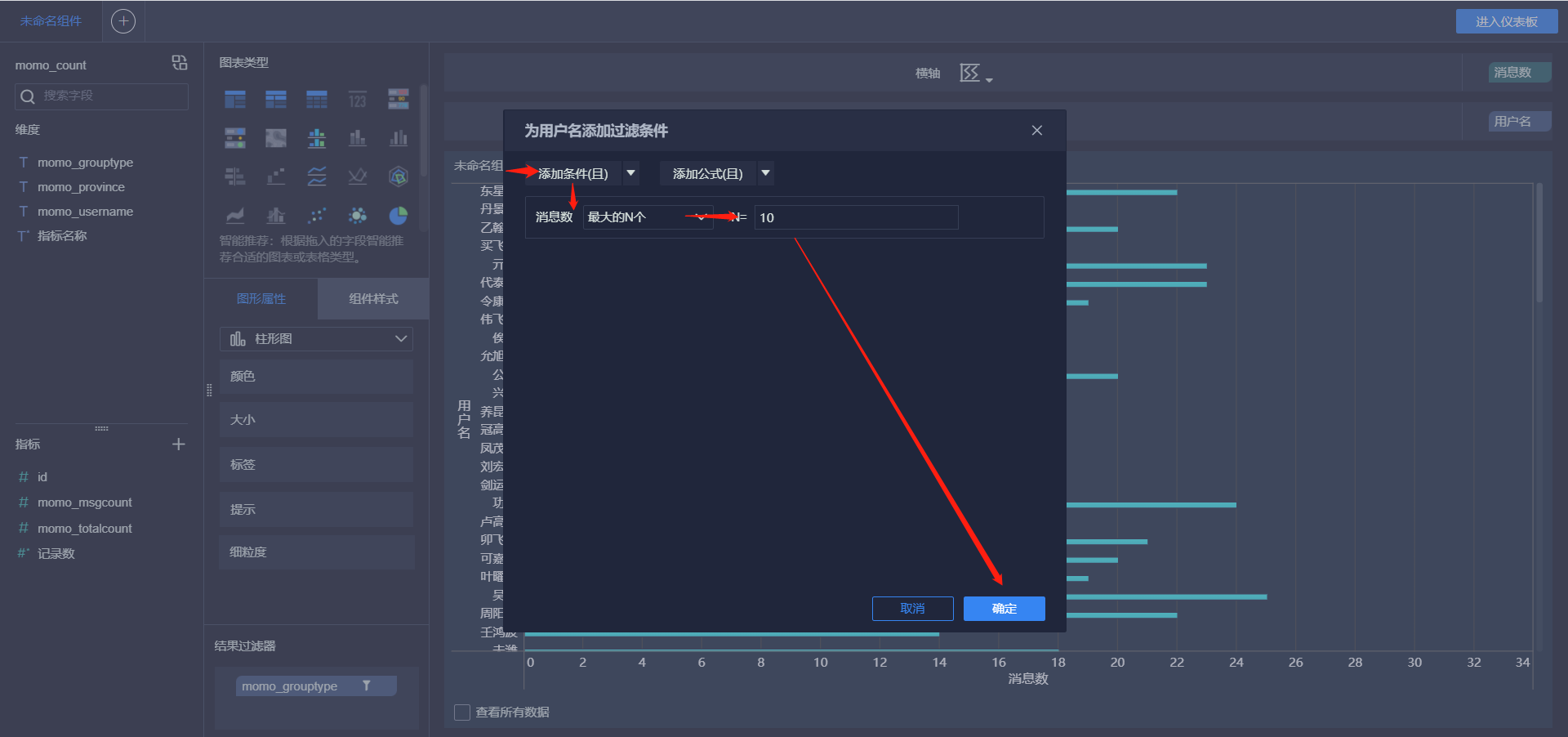
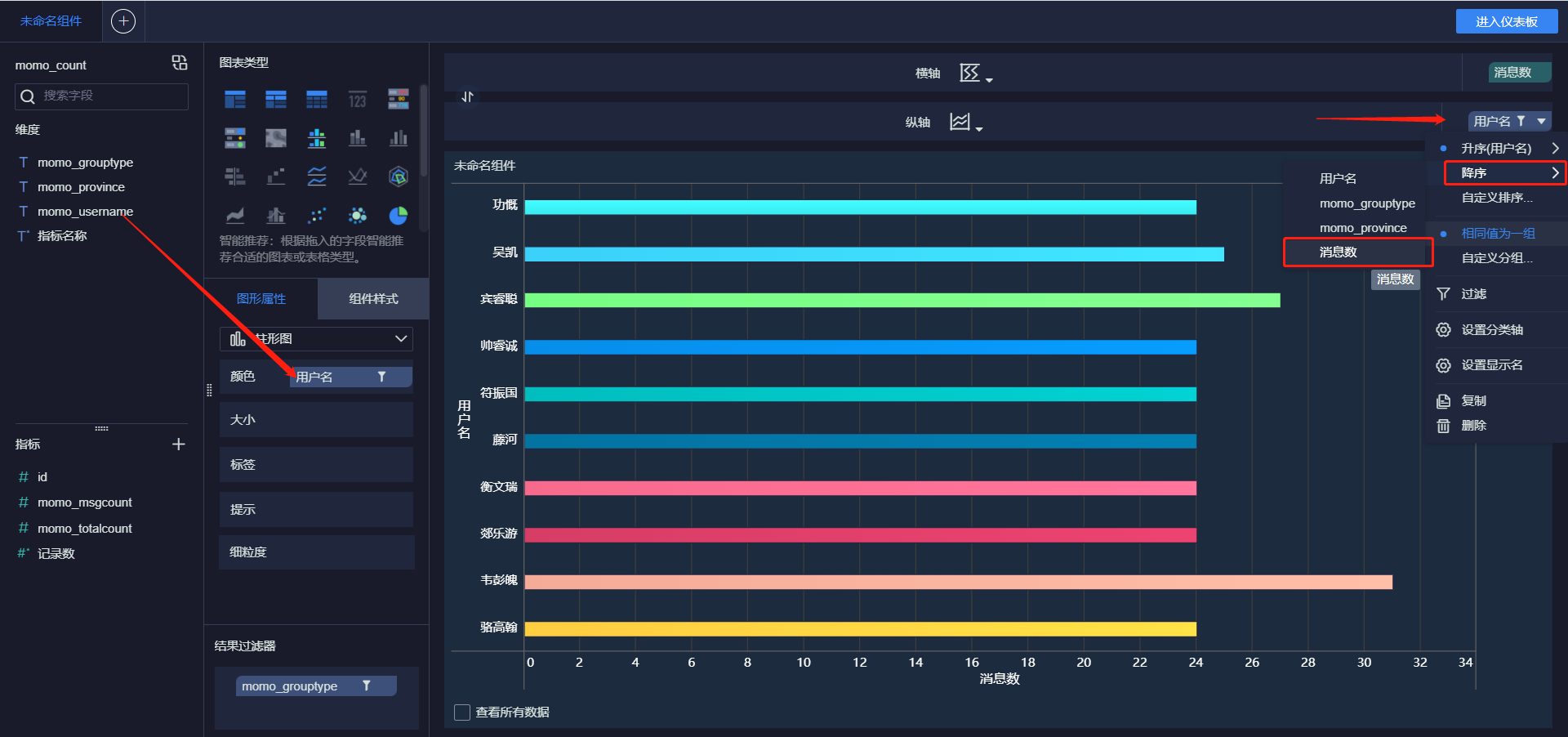
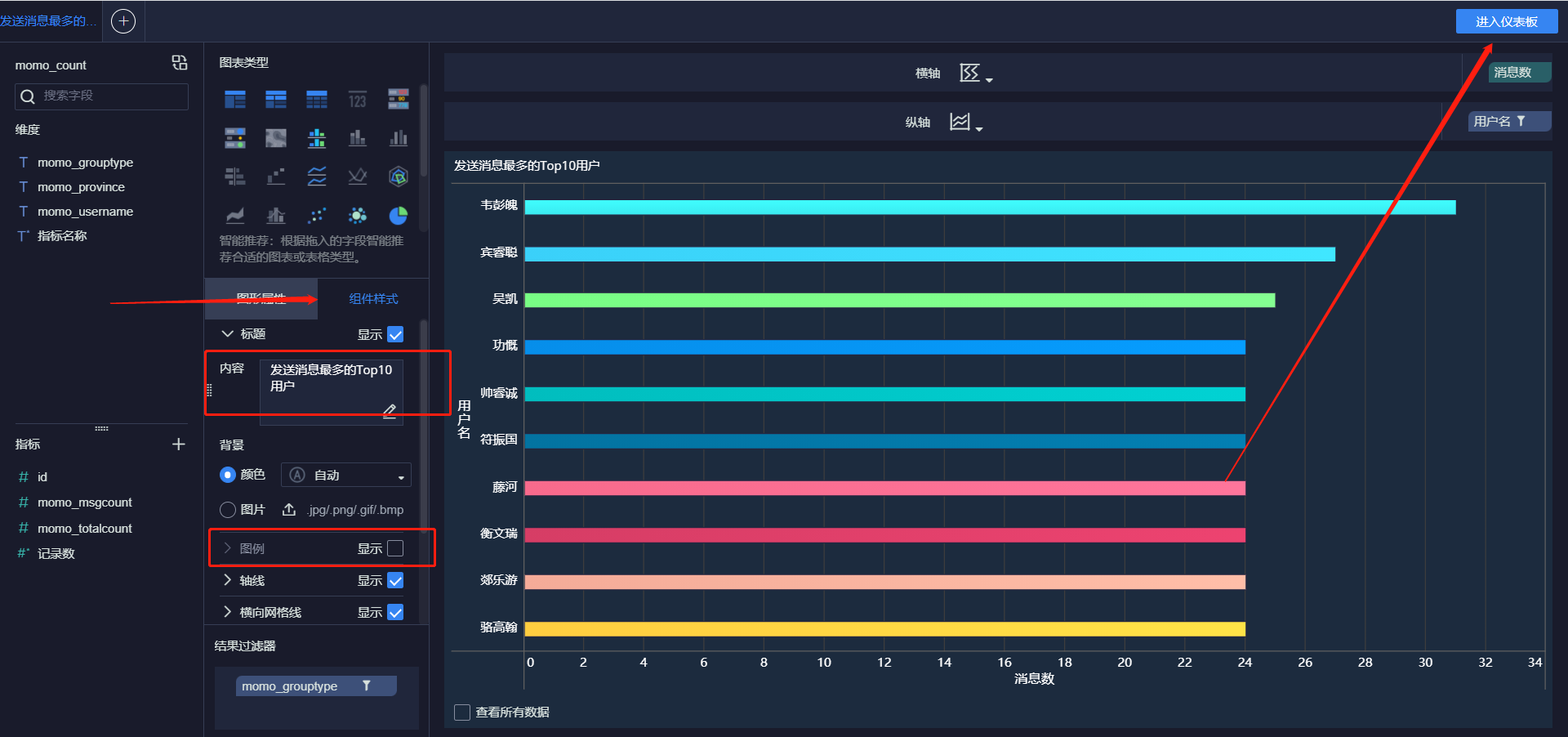
- 接受消息最多的Top10用户
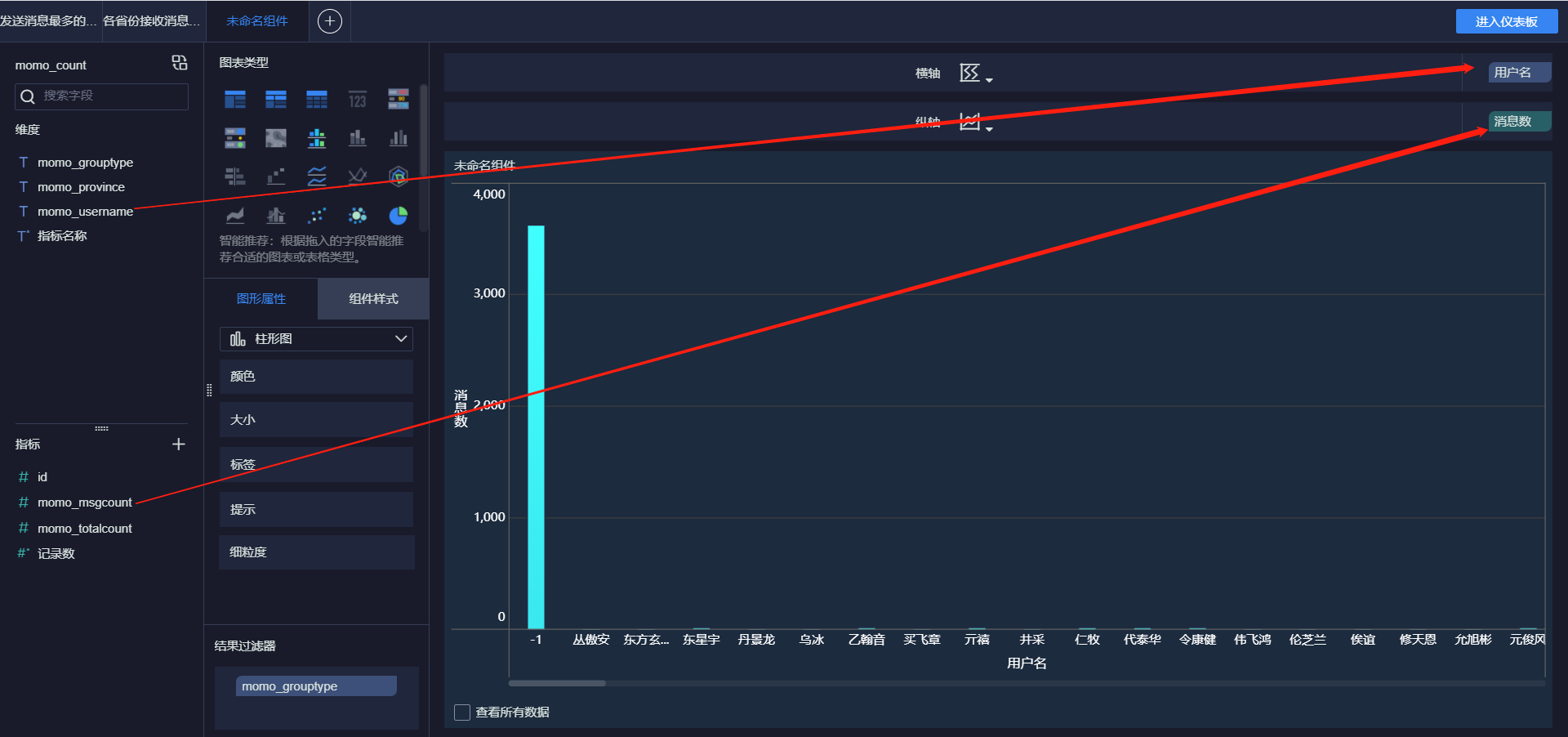
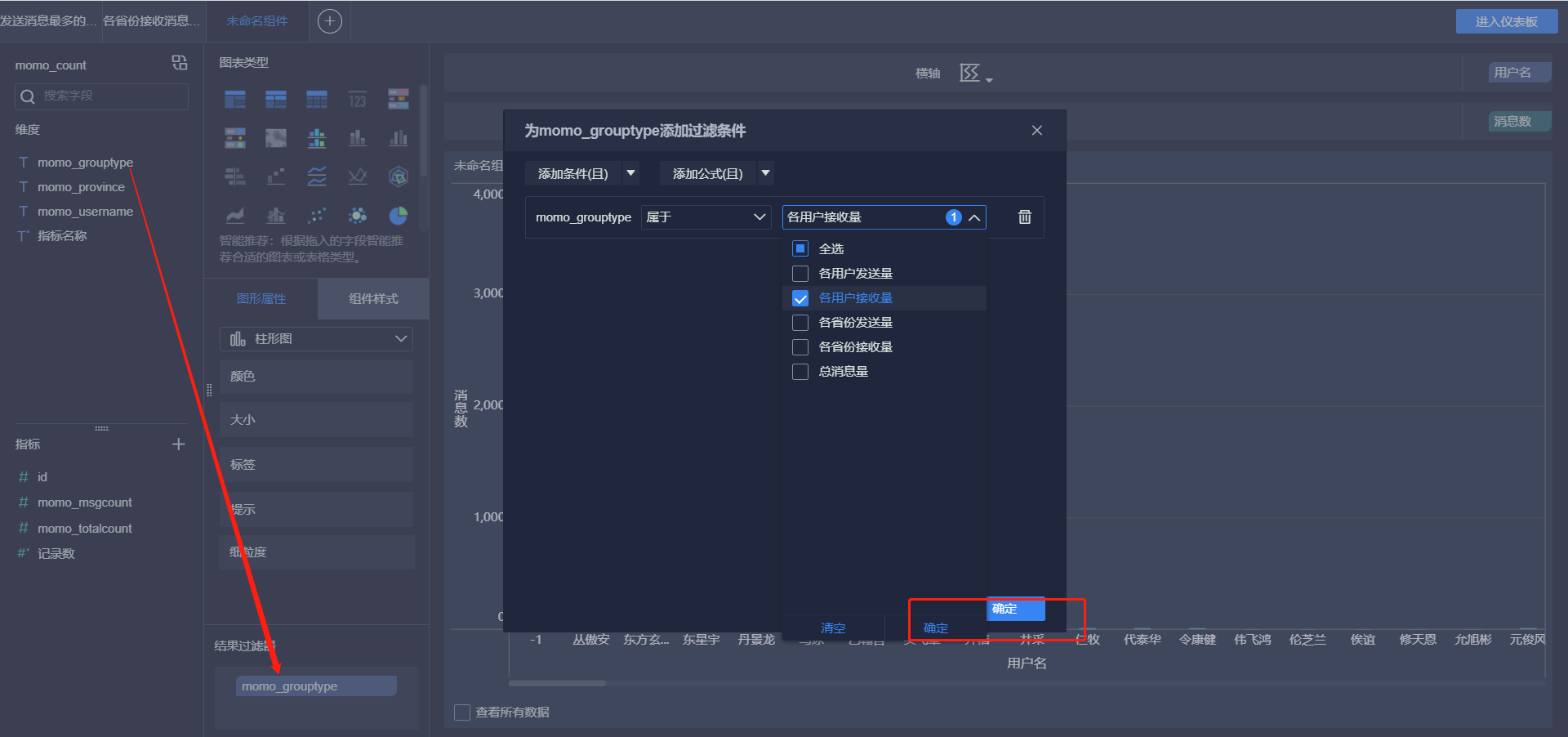
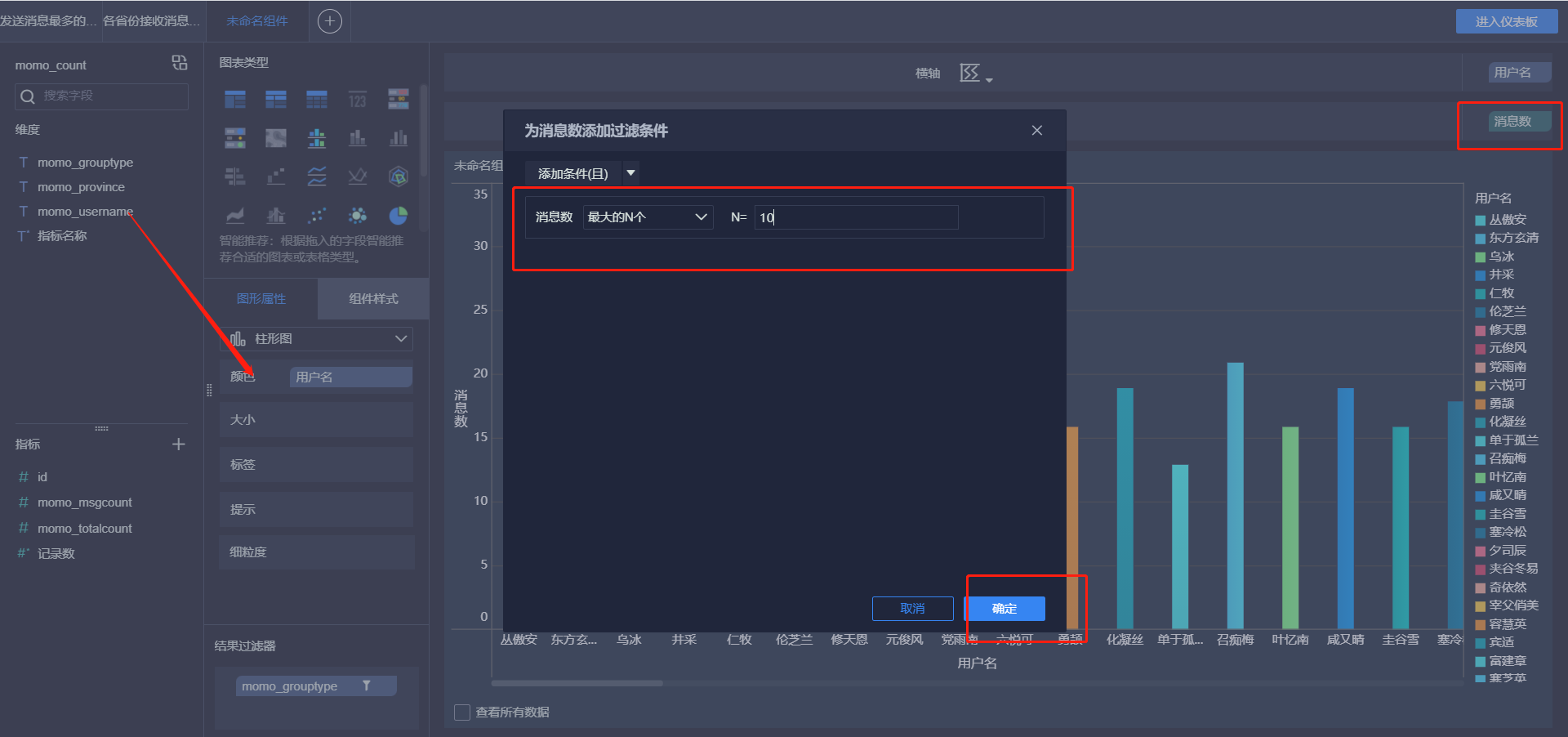
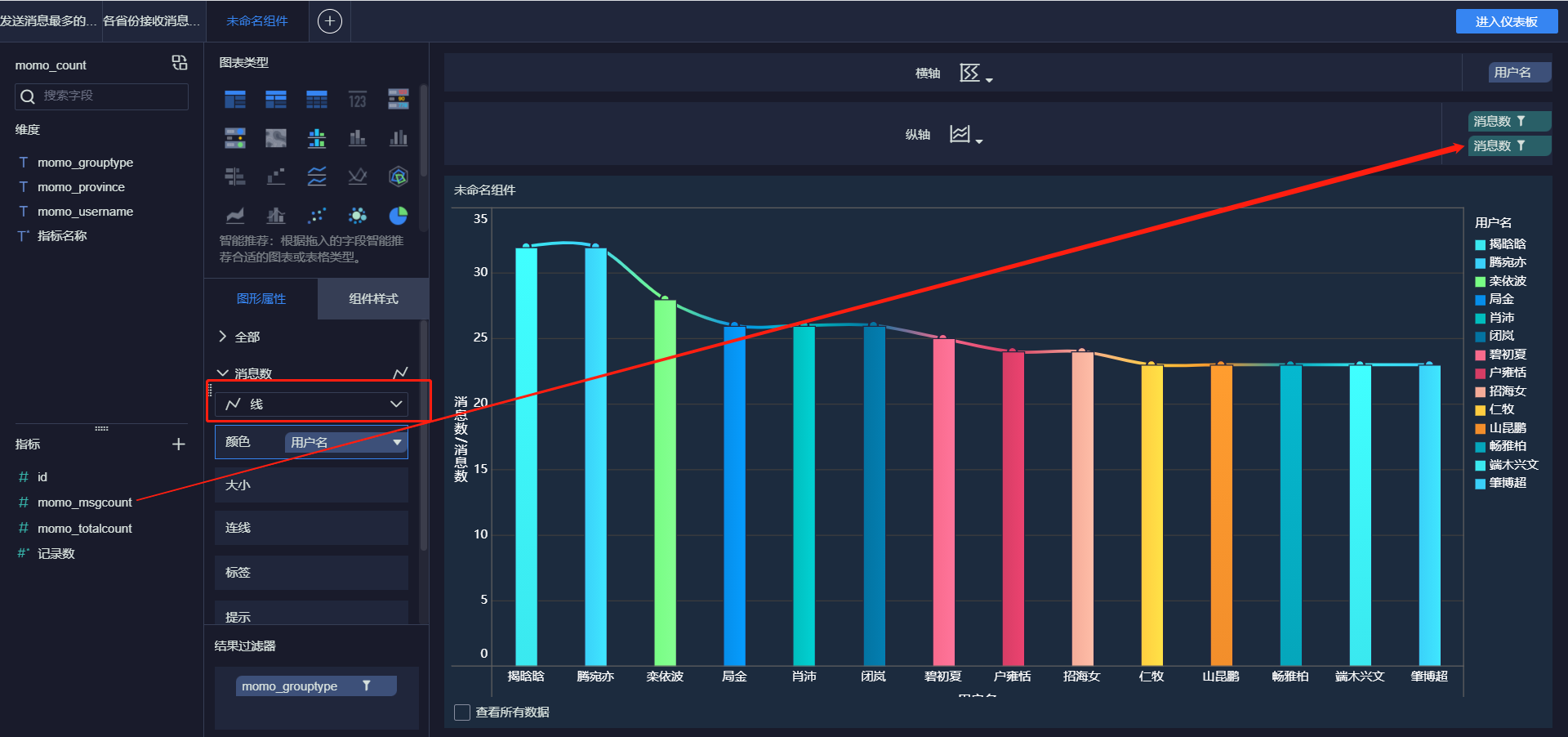
- 各省份发送消息Top10
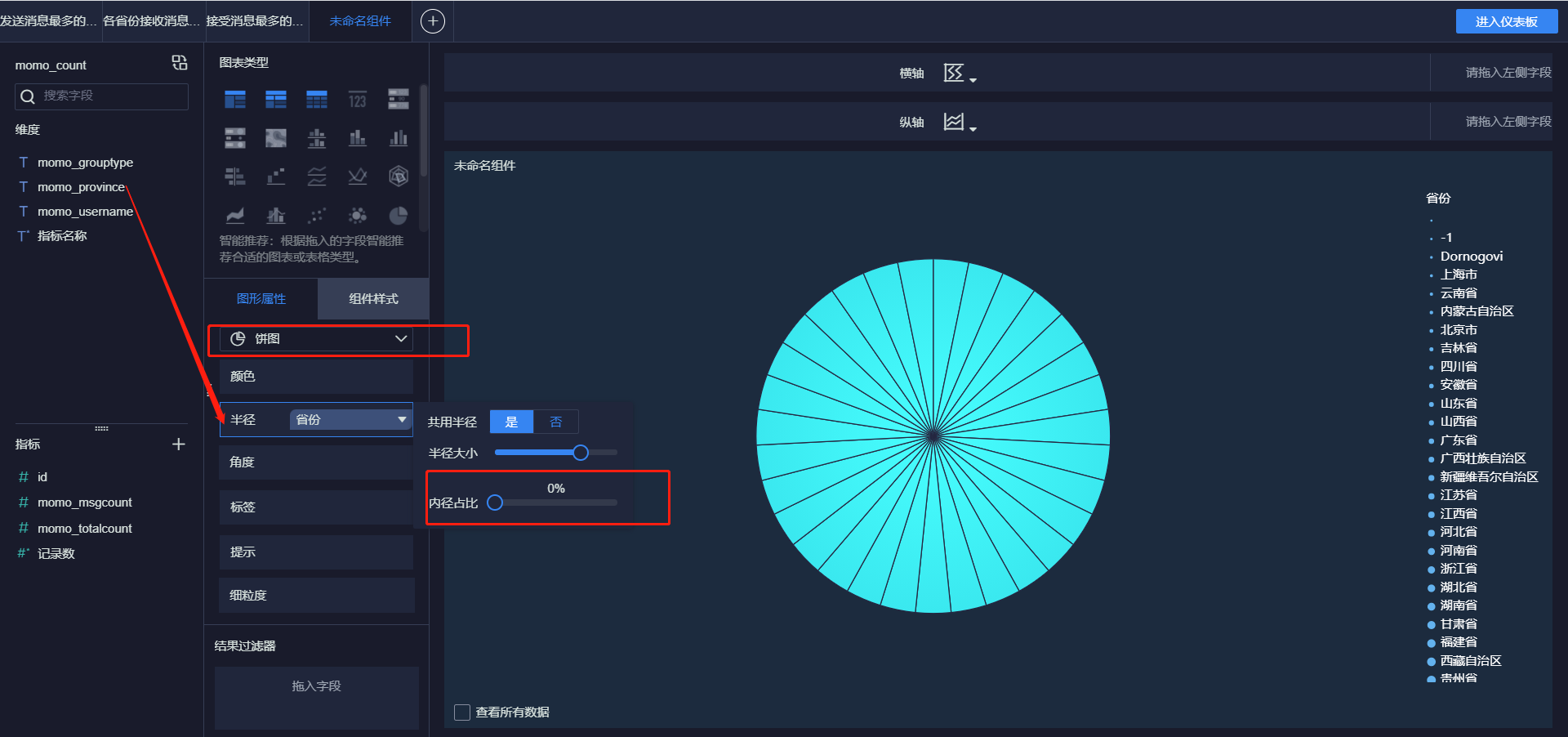
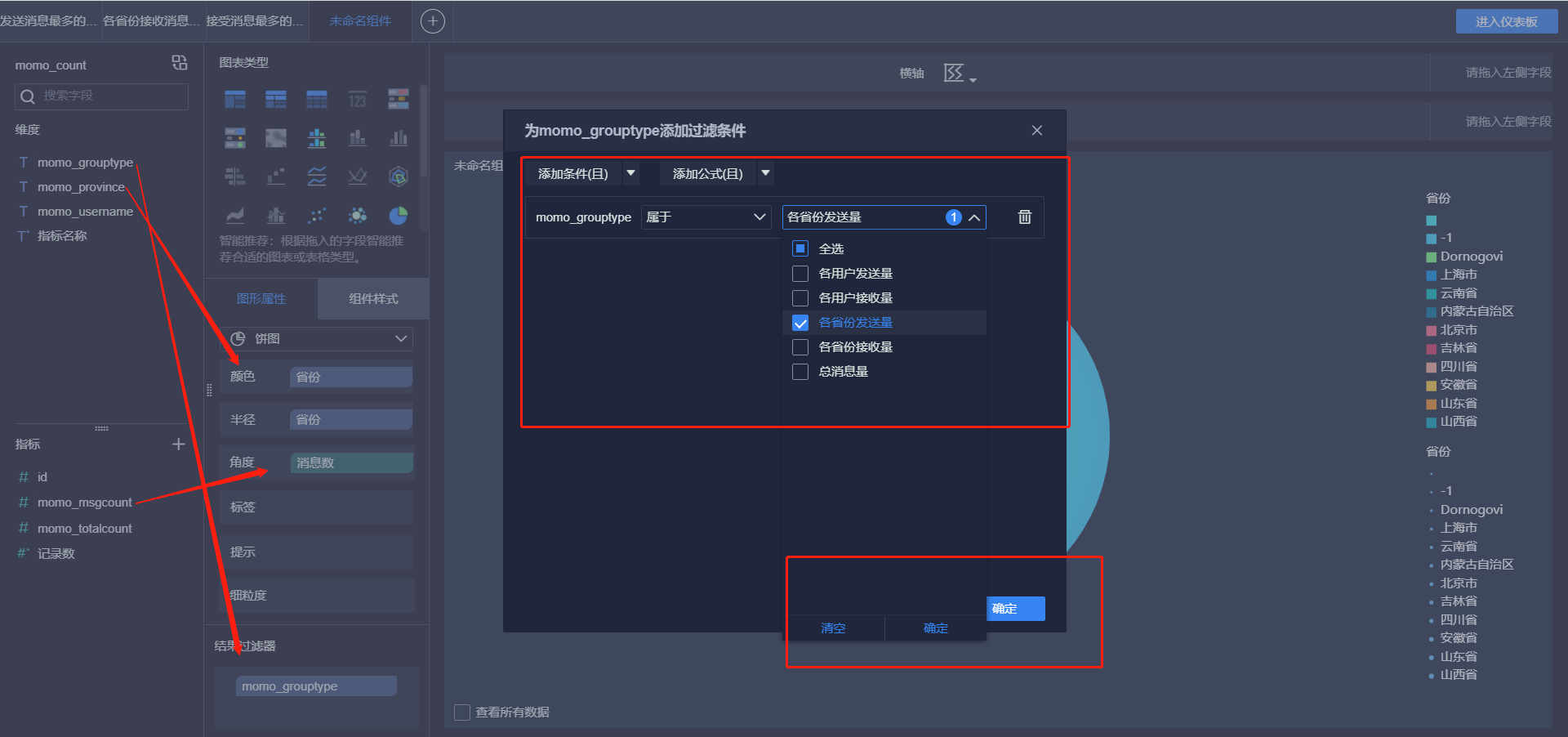
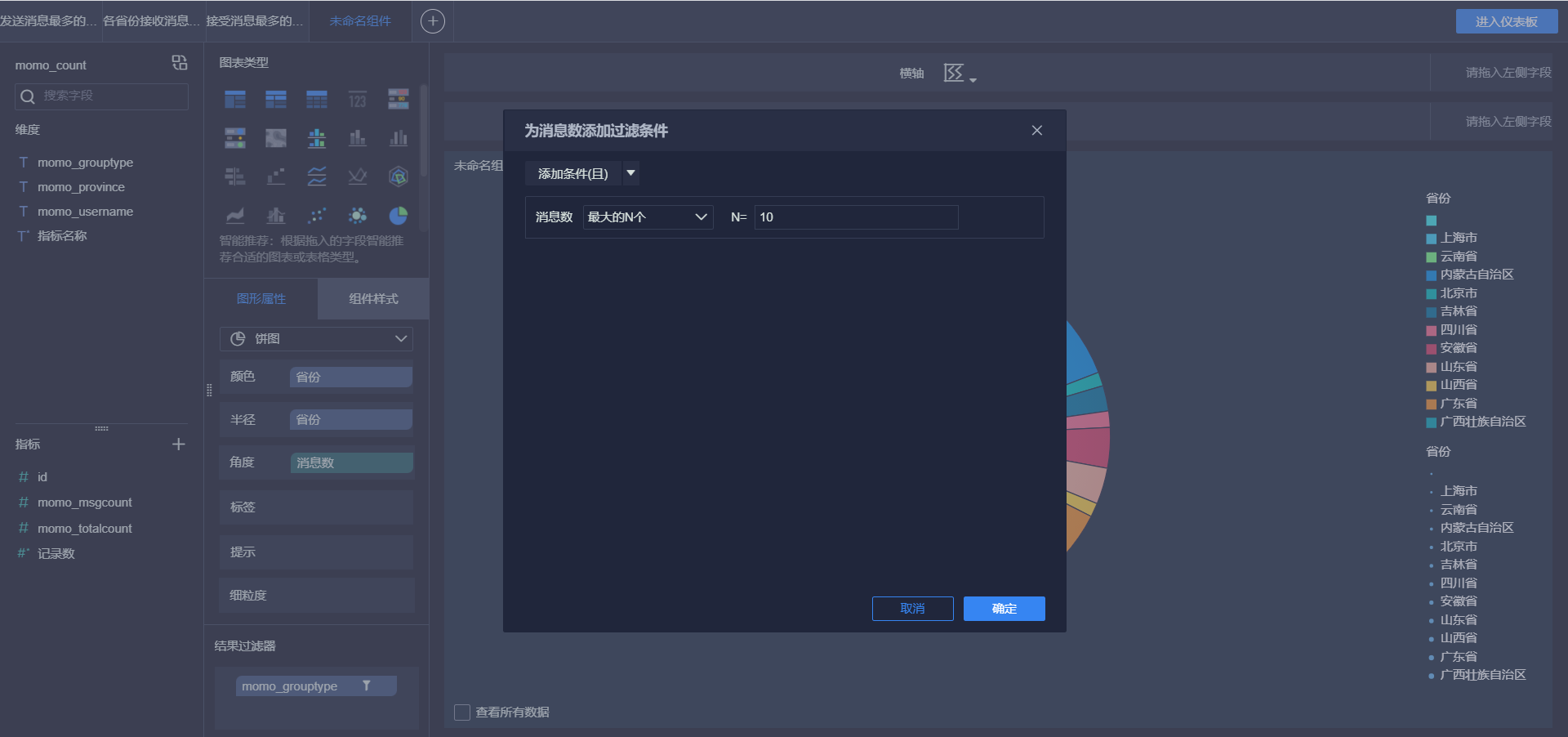
- 各省份接收消息Top10
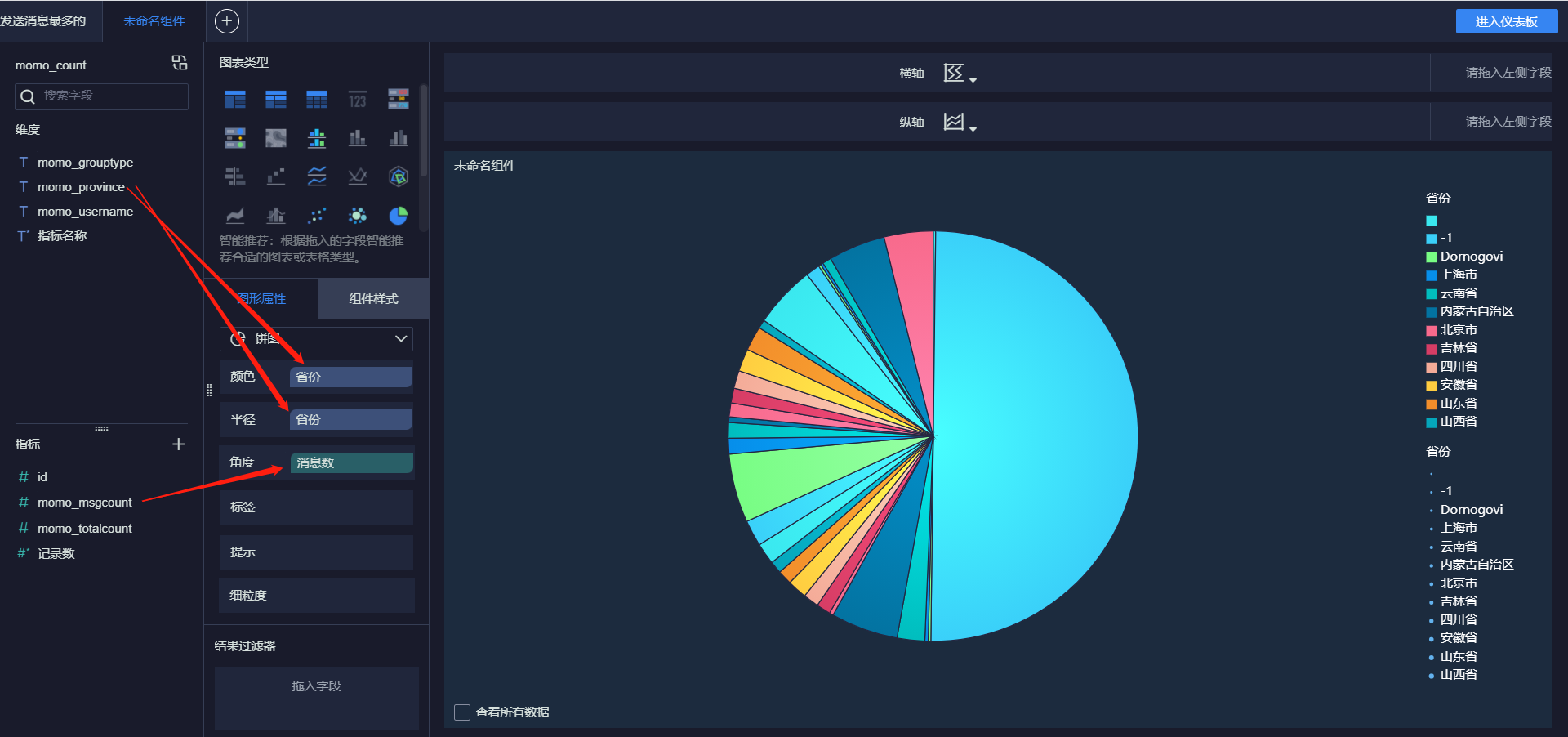
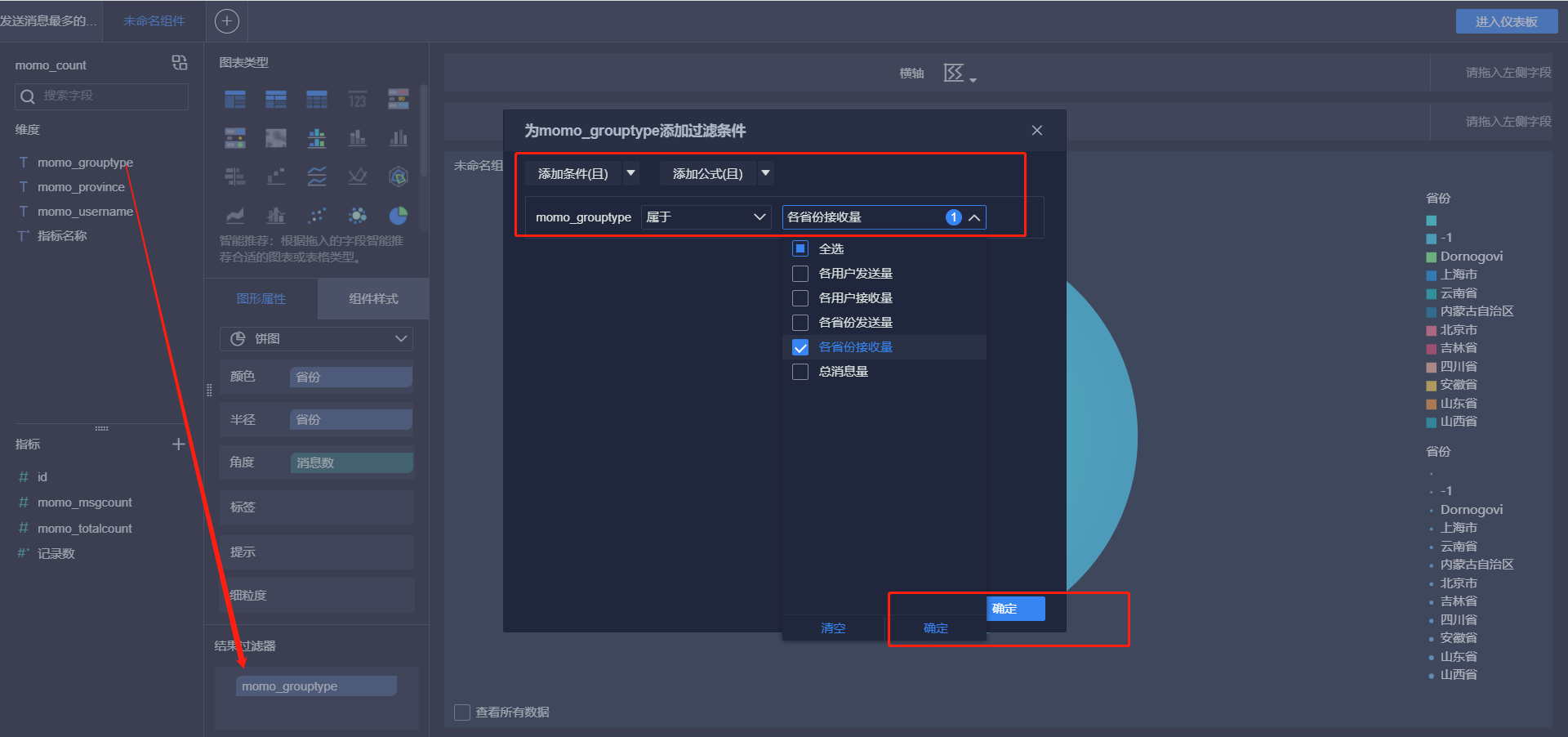
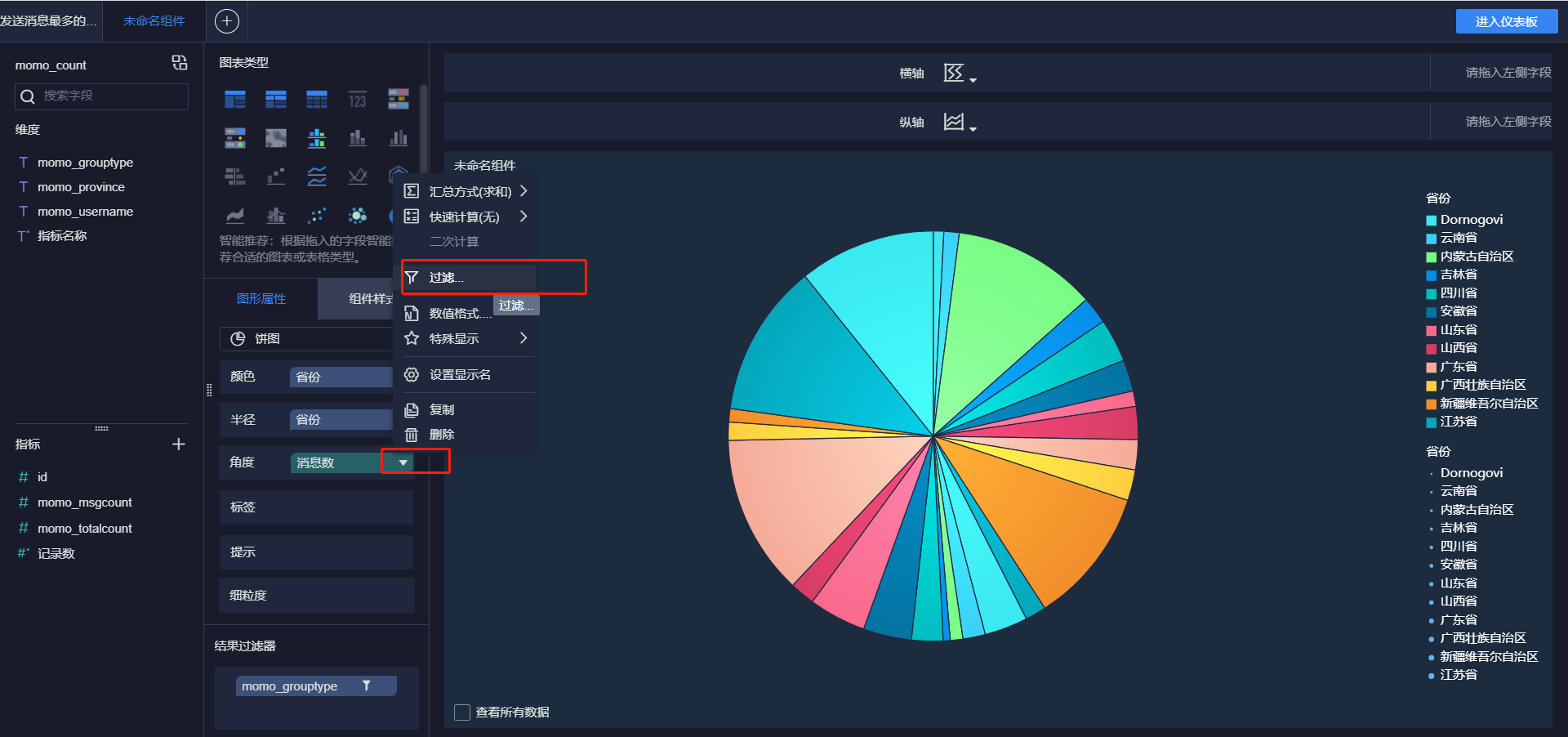
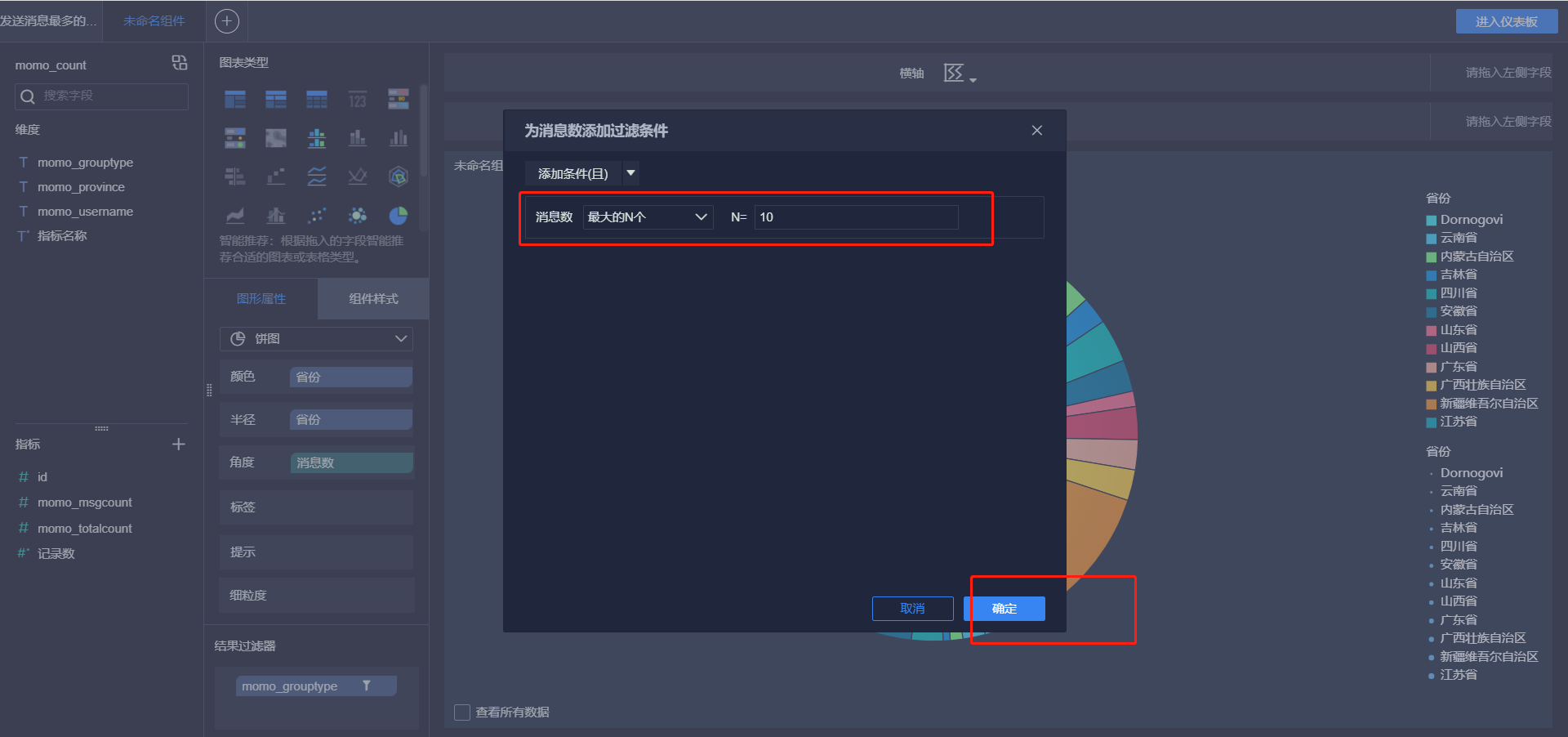
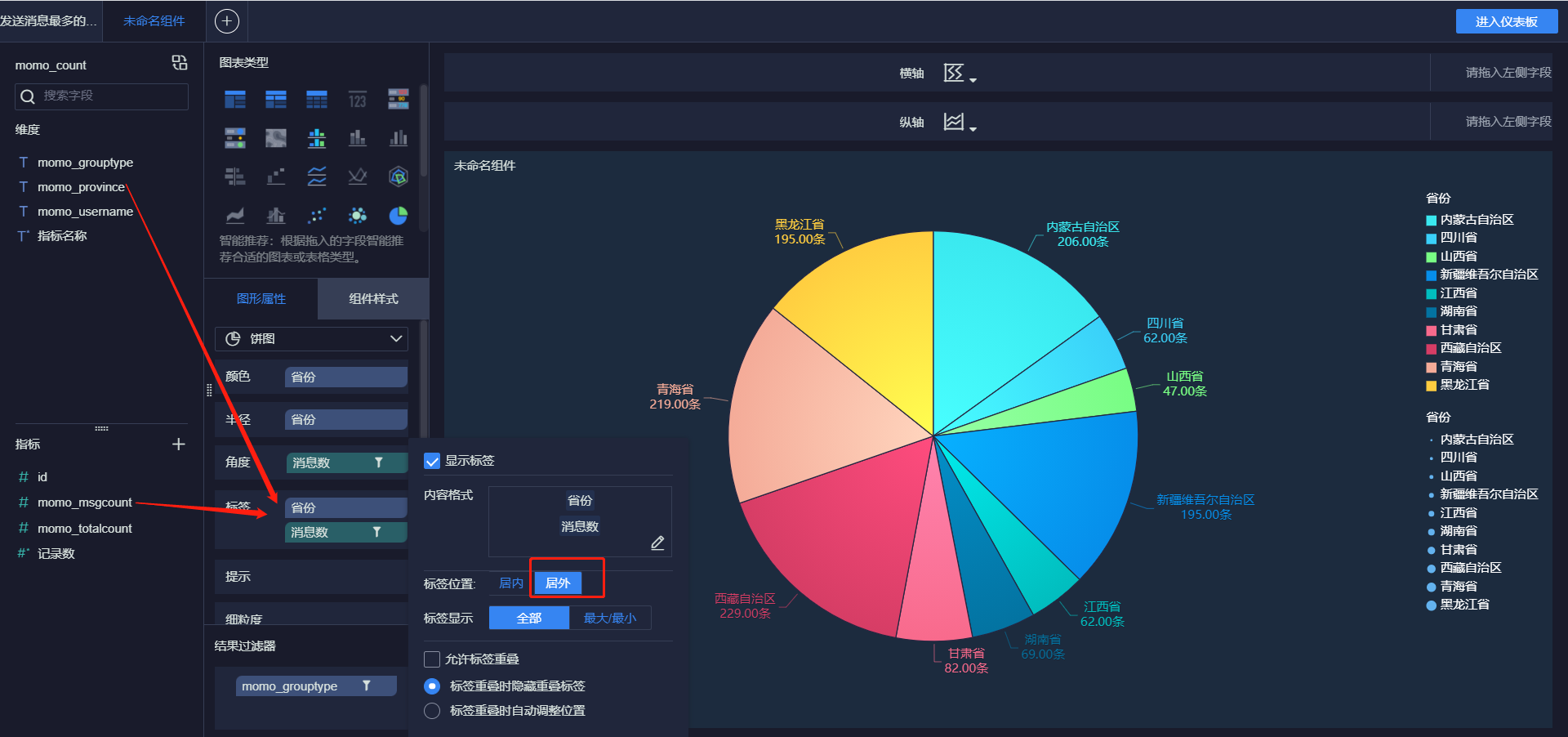
- 各省份总消息量
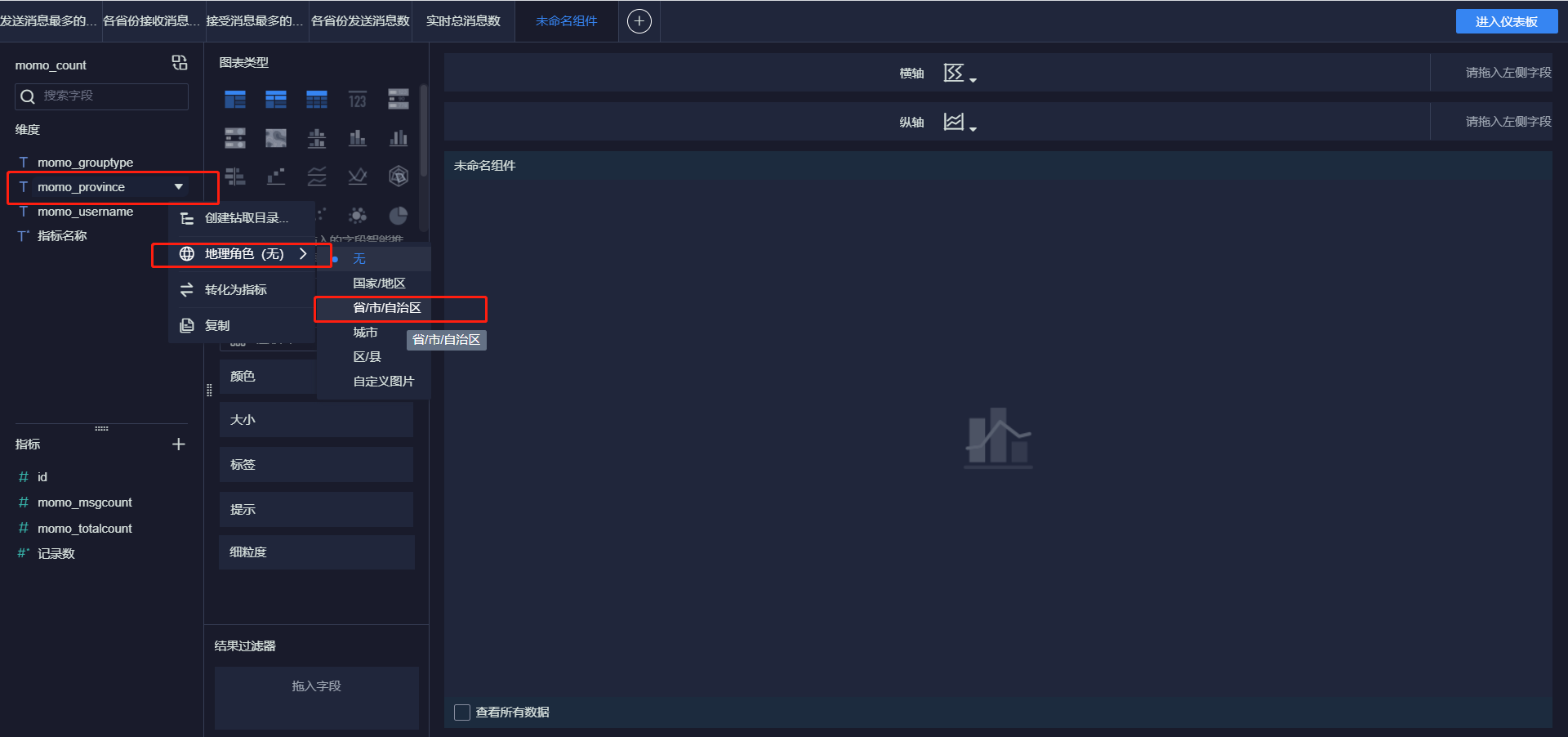
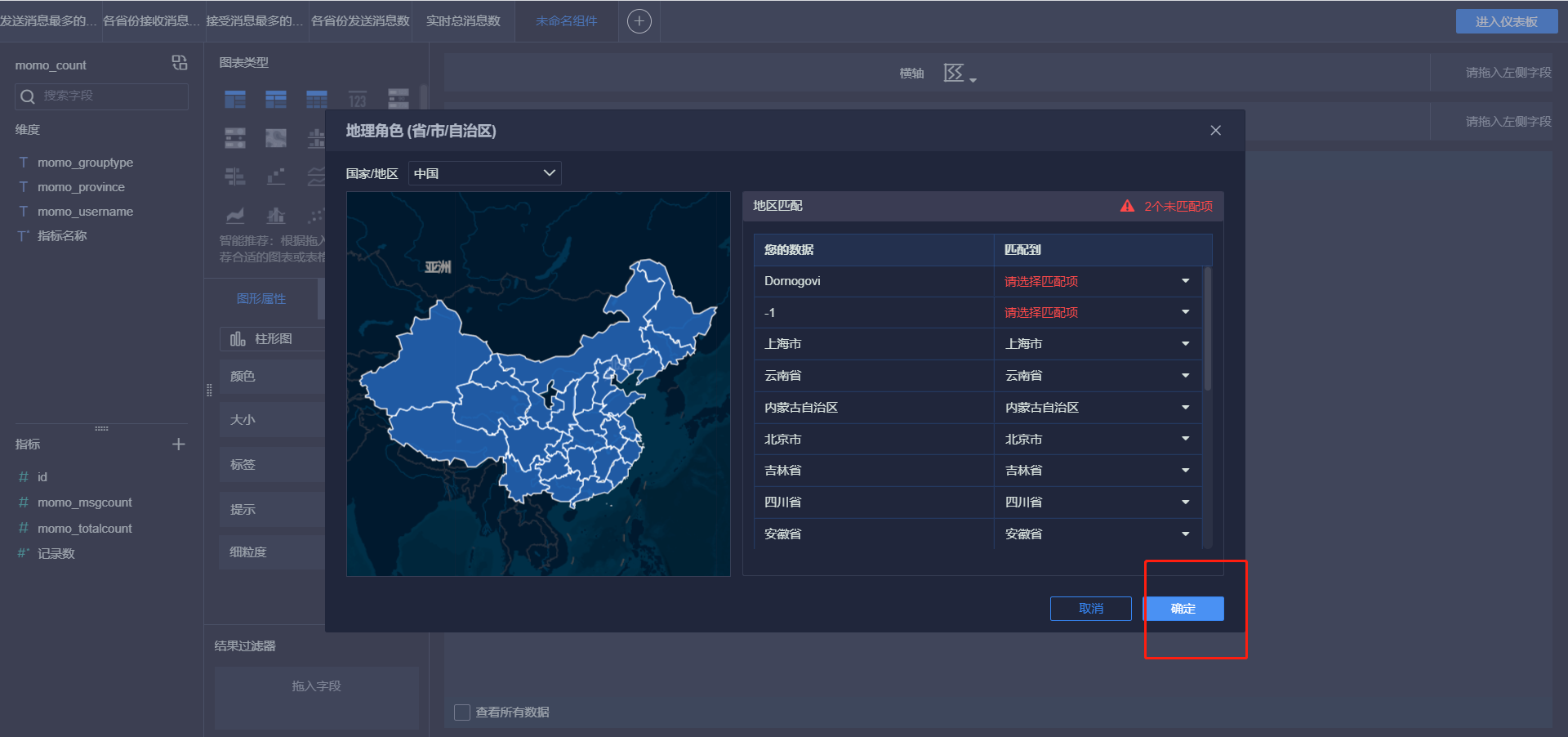
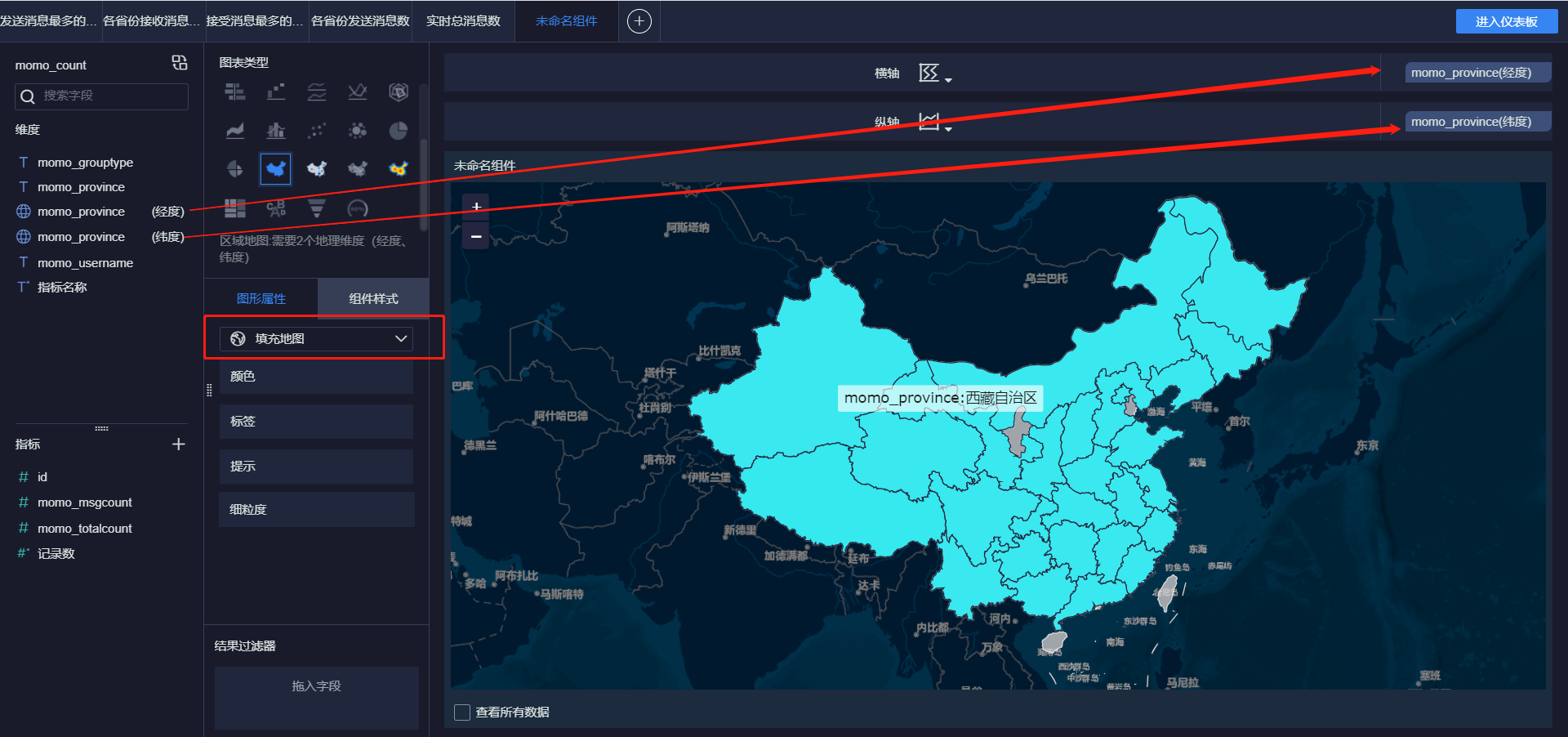

- 小结:实现FineBI实时报表构建
知识点14:FineBI实时配置测试
- 目标:实现实时报表测试
- 实施
- 实时报表配置
- 官方文档:https://help.fanruan.com/finebi/doc-view-363.html
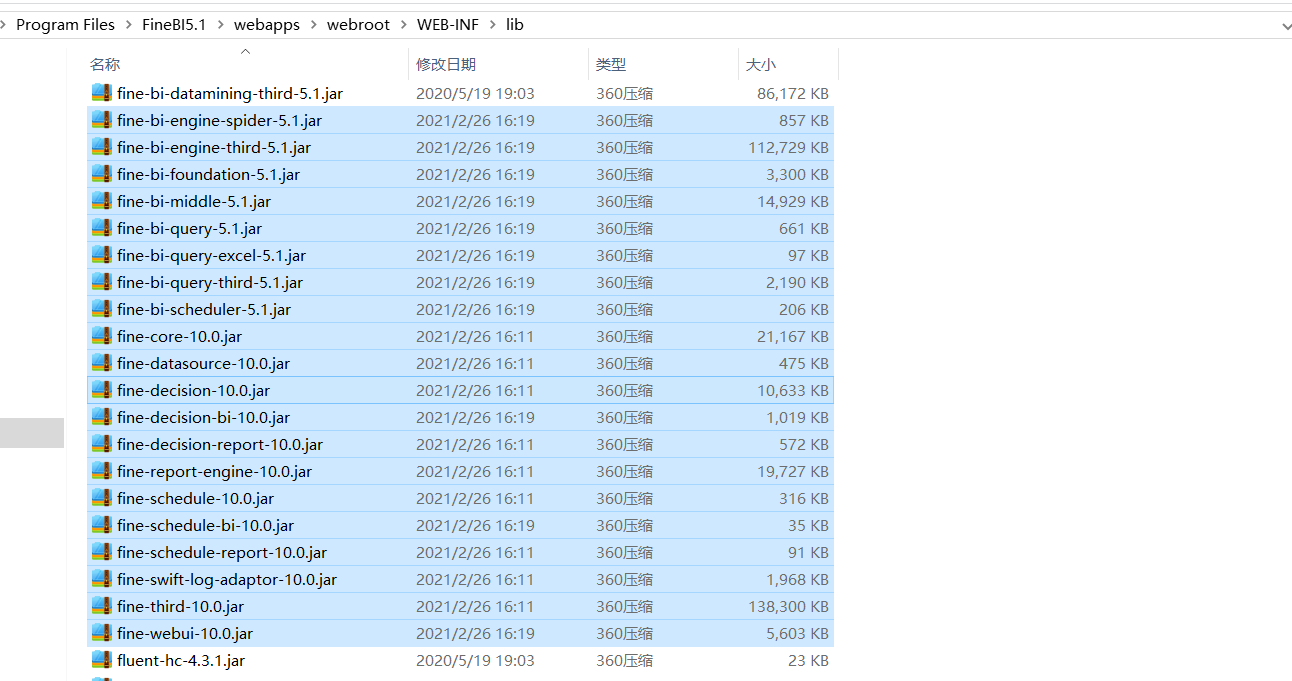
- 添加jar包:将jar包放入FineBI安装目录的 webapps\webroot\WEB-INF\lib目录下
- 注意:如果提示已存在,就选择覆盖
- 添加JS文件
- 创建js文件:refresh.js
- 实时报表配置
setTimeout(function () {
var b =document.title;
var a =BI.designConfigure.reportId;//获取仪表板id
//这里要指定自己仪表盘的id
if (a=="d574631848bd4e33acae54f986d34e69") {
setInterval(function () {
BI.SharingPool.put("controlFilters", BI.Utils.getControlCalculations());
//Data.SharingPool.put("controlFilters", BI.Utils.getControlCalculations());
BI.Utils.broadcastAllWidgets2Refresh(true);
}, 3000);//5000000为定时刷新的频率,单位ms
}
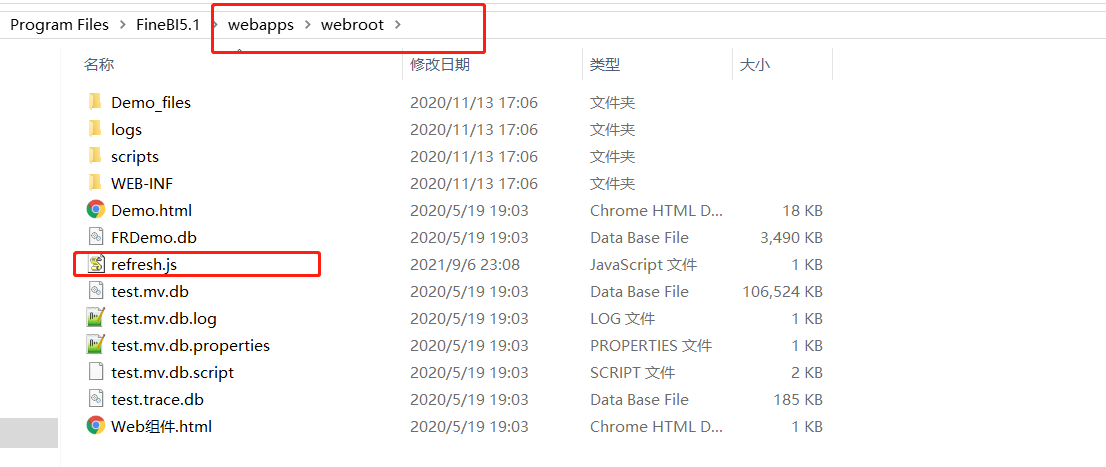
}, 2000) - 将创建好的refresh.js文件放至 FineBI 安装目录%FineBI%/webapps/webroot中
 - 关闭FineBI缓存,然后关闭FineBI
- 关闭FineBI缓存,然后关闭FineBI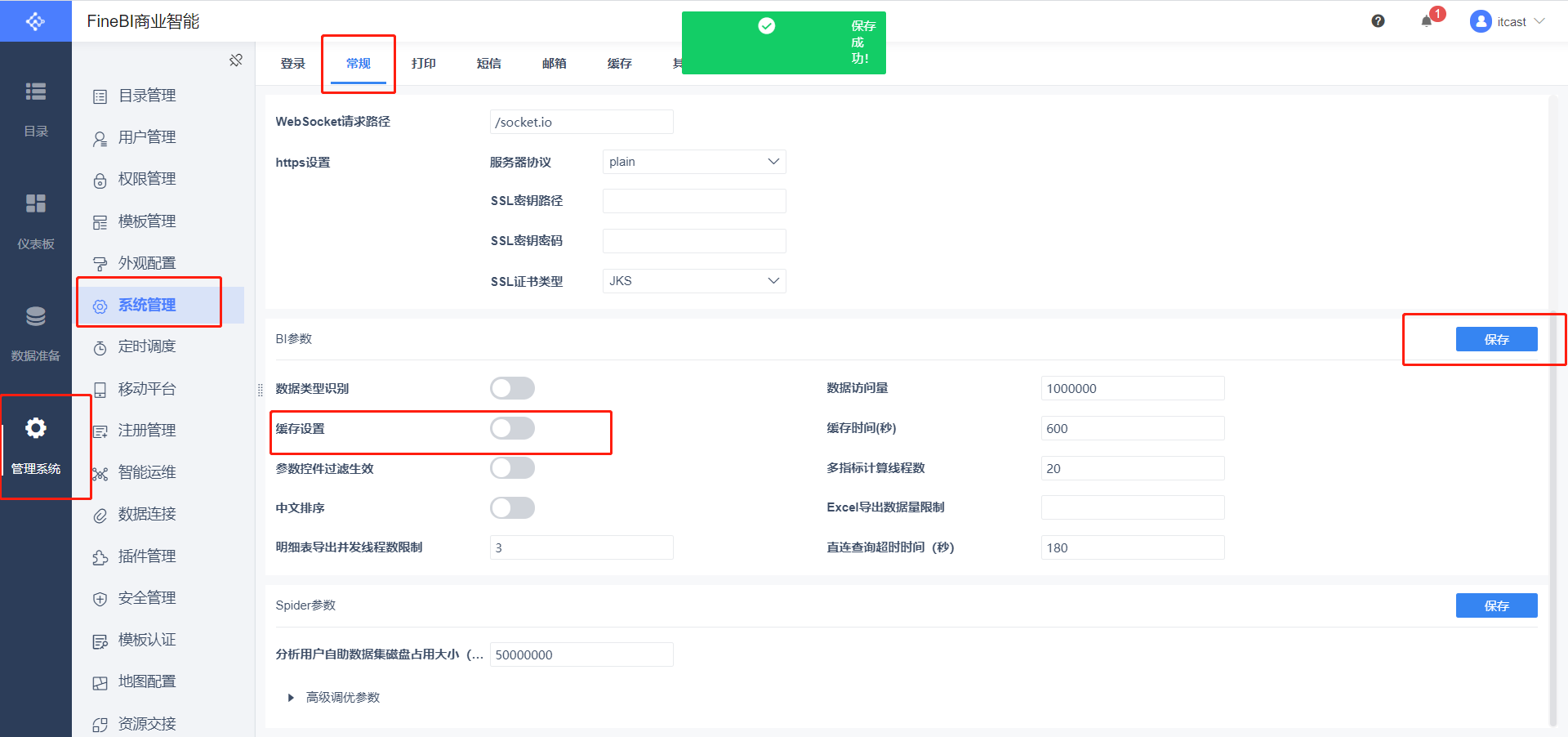 - 修改jar包,添加js
- 修改jar包,添加js 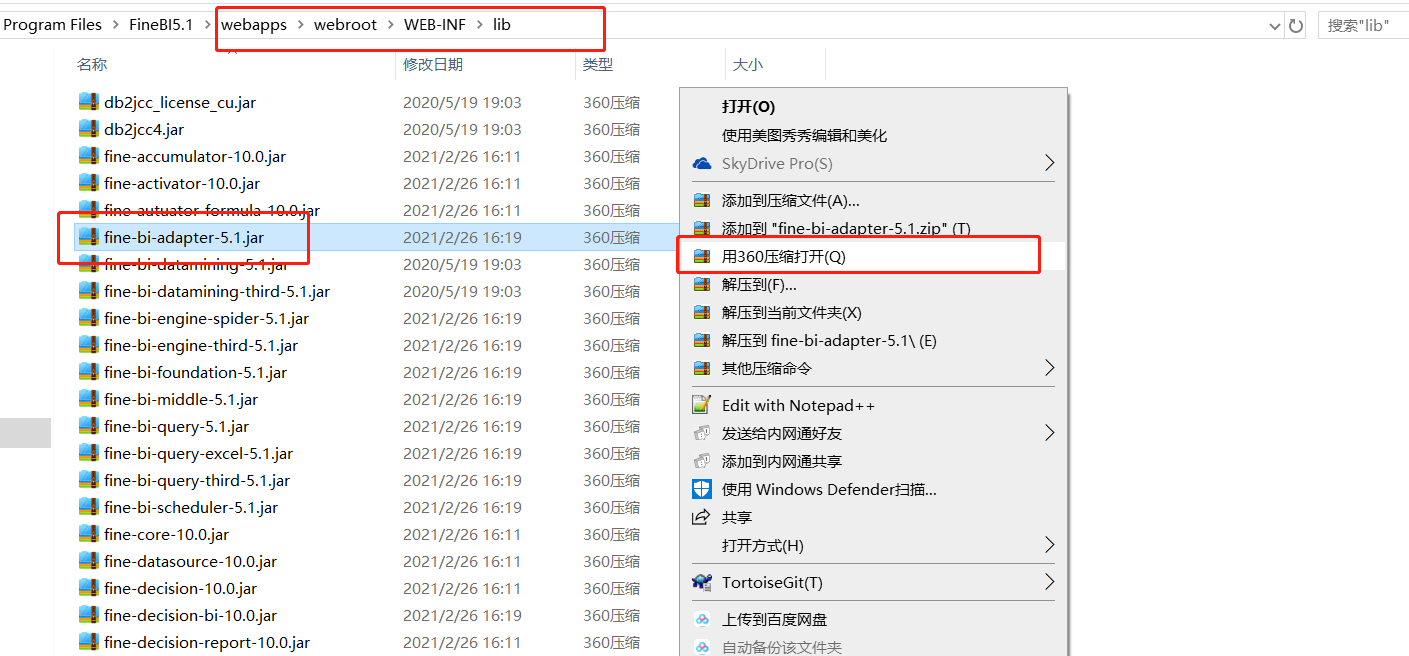
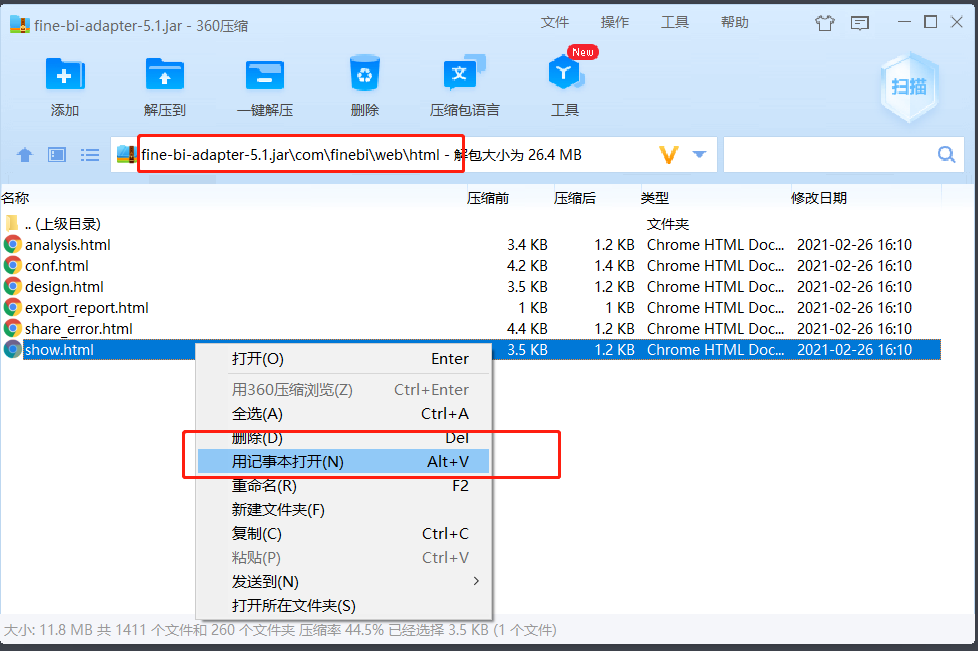
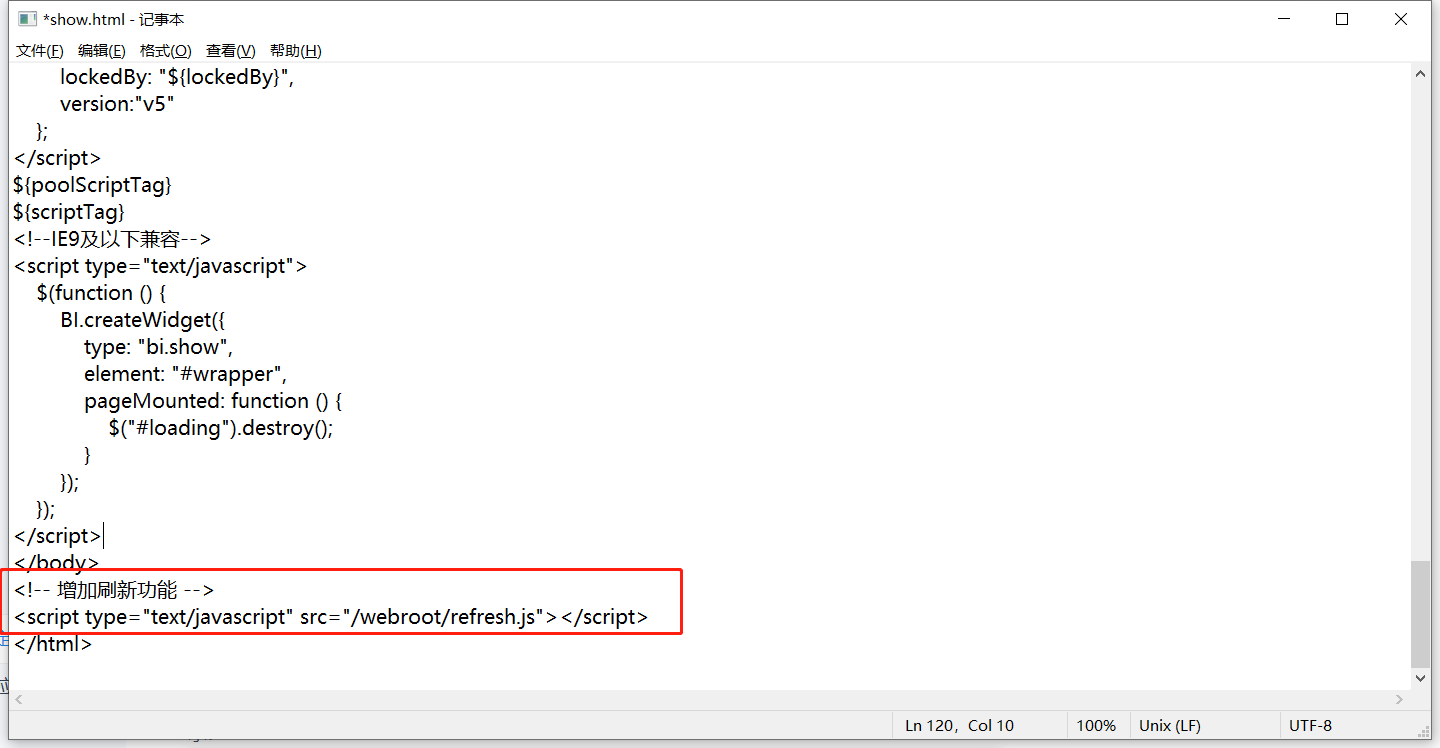
<!-- 增加刷新功能 -->
<script type="text/javascript" src="/webroot/refresh.js"></script> - **重启FineBI**
- 实时刷新测试
- 清空MySQL结果表
- 启动Flink程序:运行MoMoFlinkCount
- 启动Flume程序
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_kafka.properties -Dflume.root.logger=INFO,console- 启动模拟数据
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
10- 观察报表:注意一定要预览仪表盘
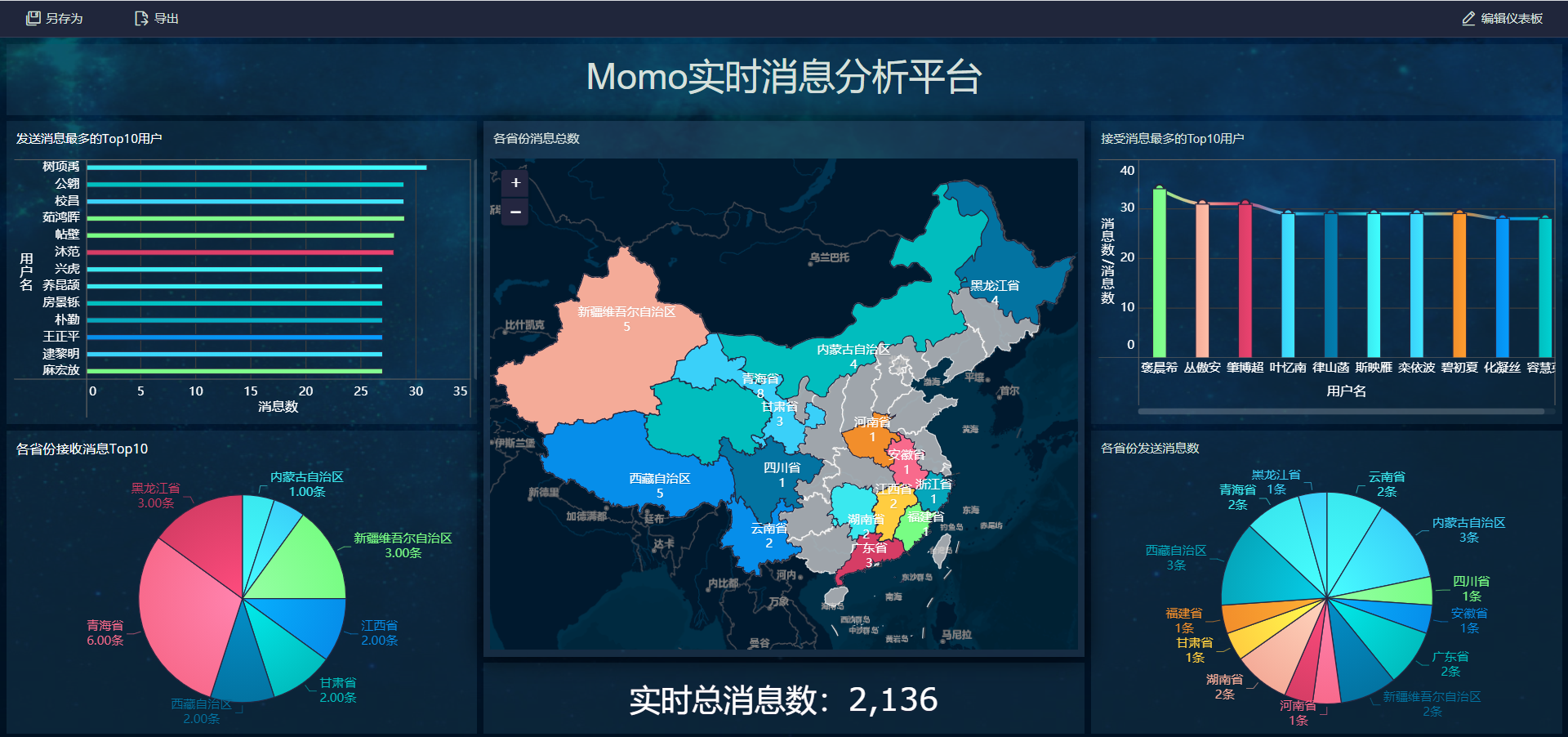

- 小结:实现FineBI实时测试
附录一:Maven依赖
<!--远程仓库-->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases><enabled>true</enabled></releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<!--Hbase 客户端-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.0</version>
</dependency>
<!--kafka 客户端-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<!--JSON解析工具包-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<!--Flink依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- flink操作hdfs、Kafka、MySQL、Redis,所需要导入该包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<!--HTTP请求的的依赖-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
<!--MySQL连接驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>附录二:离线消费者完整代码
package bigdata.itcast.cn.momo.offline;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MD5Hash;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.time.Duration;
import java.util.*;
/**
* @ClassName MomoKafkaToHbase
* @Description TODO 离线场景:消费Kafka的数据写入Hbase
* @Create By Frank
*/
public class MomoKafkaToHbase {
private static SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private static Connection conn;
private static Table table;
private static TableName tableName = TableName.valueOf("MOMO_CHAT:MOMO_MSG");//表名
private static byte[] family = Bytes.toBytes("C1");//列族
//todo:2-构建Hbase连接
//静态代码块: 随着类的加载而加载,一般只会加载一次,避免构建多个连接影响性能
static{
try {
//构建配置对象
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","node1:2181,node2:2181,node3:2181");
//构建连接
conn = ConnectionFactory.createConnection(conf);
//获取表对象
table = conn.getTable(tableName);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//todo:1-构建消费者,获取数据
consumerKafkaToHbase();
// String momoRowkey = getMomoRowkey("2020-08-13 12:30:00", "13071949728", "17719988692");
// System.out.println(momoRowkey);
}
/**
* 用于消费Kafka的数据,将合法数据写入Hbase
*/
private static void consumerKafkaToHbase() throws Exception {
//构建配置对象
Properties props = new Properties();
//指定服务端地址
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
//指定消费者组的id
props.setProperty("group.id", "momo1");
//关闭自动提交
props.setProperty("enable.auto.commit", "false");
//指定K和V反序列化的类型
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//构建消费者的连接
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//指定订阅哪些Topic
consumer.subscribe(Arrays.asList("MOMO_MSG"));
//持续拉取数据
while (true) {
//向Kafka请求拉取数据,等待Kafka响应,在100ms以内如果响应,就拉取数据,如果100ms内没有响应,就提交下一次请求: 100ms为等待Kafka响应时间
//拉取到的所有数据:多条KV数据都在ConsumerRecords对象,类似于一个集合
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
//todo:3-处理拉取到的数据:打印
//取出每个分区的数据进行处理
Set<TopicPartition> partitions = records.partitions();//获取本次数据中所有分区
//对每个分区的数据做处理
for (TopicPartition partition : partitions) {
List<ConsumerRecord<String, String>> partRecords = records.records(partition);//取出这个分区的所有数据
//处理这个分区的数据
long offset = 0;
for (ConsumerRecord<String, String> record : partRecords) {
//获取Topic
String topic = record.topic();
//获取分区
int part = record.partition();
//获取offset
offset = record.offset();
//获取Key
String key = record.key();
//获取Value
String value = record.value();
System.out.println(topic + "\t" + part + "\t" + offset + "\t" + key + "\t" + value);
//将Value数据写入Hbase
if(value != null && !"".equals(value) && value.split("\001").length == 20 ){
writeToHbase(value);
}
}
//手动提交分区的commit offset
Map<TopicPartition, OffsetAndMetadata> offsets = Collections.singletonMap(partition,new OffsetAndMetadata(offset+1));
consumer.commitSync(offsets);
}
}
}
/**
* 用于实现具体的写入Hbase的方法
* @param value
*/
private static void writeToHbase(String value) throws Exception {
//todo:3-写入Hbase
//切分数据
String[] items = value.split("\001");
String stime = items[0];
String sender_accounter = items[2];
String receiver_accounter = items[11];
//构建rowkey
String rowkey = getMomoRowkey(stime,sender_accounter,receiver_accounter);
//构建Put
Put put = new Put(Bytes.toBytes(rowkey));
//添加列
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("msg_time"),Bytes.toBytes(items[0]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_nickyname"),Bytes.toBytes(items[1]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_account"),Bytes.toBytes(items[2]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_sex"),Bytes.toBytes(items[3]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_ip"),Bytes.toBytes(items[4]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_os"),Bytes.toBytes(items[5]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_phone_type"),Bytes.toBytes(items[6]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_network"),Bytes.toBytes(items[7]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("sender_gps"),Bytes.toBytes(items[8]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_nickyname"),Bytes.toBytes(items[9]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_ip"),Bytes.toBytes(items[10]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_account"),Bytes.toBytes(items[11]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_os"),Bytes.toBytes(items[12]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_phone_type"),Bytes.toBytes(items[13]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_network"),Bytes.toBytes(items[14]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_gps"),Bytes.toBytes(items[15]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("receiver_sex"),Bytes.toBytes(items[16]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("msg_type"),Bytes.toBytes(items[17]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("distance"),Bytes.toBytes(items[18]));
put.addColumn(Bytes.toBytes("C1"),Bytes.toBytes("message"),Bytes.toBytes(items[19]));
//执行写入
table.put(put);
}
/**
* 基于消息时间、发送人id、接受人id构建rowkey
* @param stime
* @param sender_accounter
* @param receiver_accounter
* @return
* @throws Exception
*/
private static String getMomoRowkey(String stime, String sender_accounter, String receiver_accounter) throws Exception {
//转换时间戳
long time = format.parse(stime).getTime();
String suffix = sender_accounter+"_"+receiver_accounter+"_"+time;
//构建MD5
String prefix = MD5Hash.getMD5AsHex(Bytes.toBytes(suffix)).substring(0,8);
//合并返回
return prefix+"_"+suffix;
}
}附录三:注册百度地图开放平台
- step1:登陆百度账号
https://lbsyun.baidu.com/step2:注册开发者账号
- 进入邮箱,点击链接激活
step3:创建AK码