
PySpark_1
day01-PySpark课程笔记
文档
今日内容:
- 1- Spark 的基本介绍
- 2- Spark的环境安装 (参考安装文档, 将其搭建成功)
- 3- 基于pycharm完成pyspark入门案例(操作)
1. Spark的基本介绍
1.1 Spark的基本介绍
- MapReduce: 分布式的计算分析引擎
MR: 分布式计算引擎, 处理大规模的数据, 主要是用于批处理操作, 离线计算操作
MR存在的弊端主要是什么?
1- 执行效率比较低
2- API相对比较底层, 开发效率比较慢
3- 迭代计算非常的不方便
什么是迭代计算呢?
简单来说, 在执行过程中, 整个的计算任务需要划分为多个阶段. 每一个阶段需要依赖于上一个阶段的执行结果, 一个阶段一个阶段的进行运行, 我们可以将这样的计算过程称为迭代计算正因为MR存在这样的一些弊端, 在一些场景中, 更加希望能够有一款计算引擎执行效率更加高效, 能够更好的支持迭代计算操作, 也能够更加方便的使用,同时还能够处理大规模的数据, 我们的spark其实就是在这样的背景下, 逐步产生出来
Apache Spark 是一款用于处理大规模数据的分布式计算分析引擎, 与MR类似 , 基于内存计算, 整个Spark的核心数据结构为RDD
RDD: 弹性的分布式数据集 目前将其理解为就是一个庞大的容器, 整个计算都是在这个容器中完成的
Apache Spark最早是来源于加州伯克利分校发布一篇论文产生的, 后期将其贡献给Apache , 目前也是apache旗下顶级开源项目,官方地址: https://spark.apache.org/
整个spark主要是基于scala语言编写的
为什么说Spark的程序运行效率快呢?
原因一: Spark提供了一种全新数据结构: RDD
通过这个数据结构, 让分布式计算引擎在运算的时候可以基于内存进行计算, 同时能够更好的进行迭代计算操作, 对于MR来说, 主要是基于磁盘来计算, 而且在进行迭代计算的操作, 需要将多个MR进行串联操作. 执行效率比较低
原因二: Spark基于线程来运行的, 而MR是基于进程运行的
线程的启动和销毁的速度, 要高于进程的启动和销毁的基于线程和基于进程的各自的优缺点? 
1.2 Spark的发展史
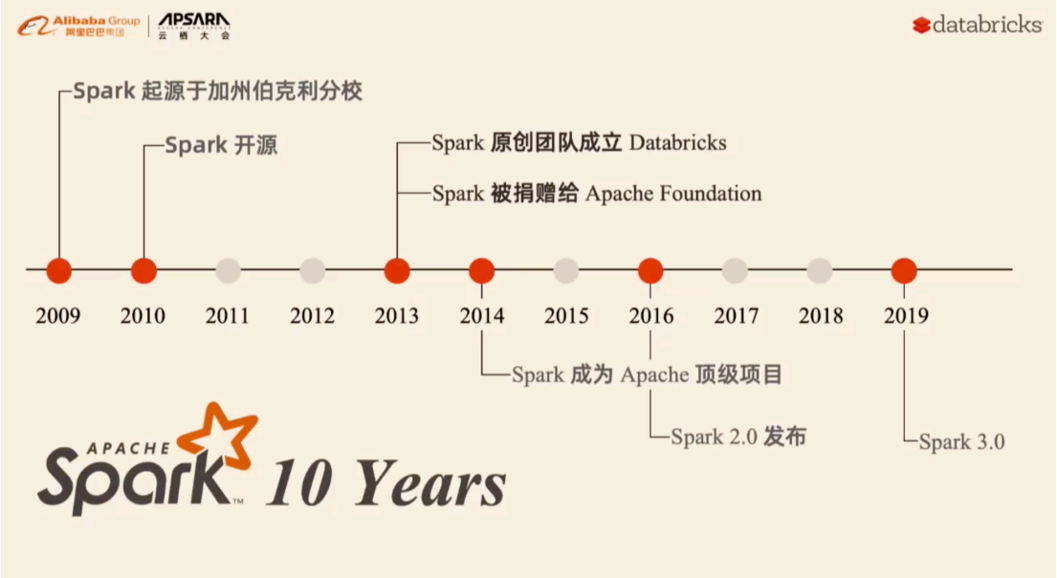
Spark 是一个分布式计算的引擎, PySpark是一个python的库 专门用于通过python语言来操作Spark的python库1.3 Spark的特点
- 1- 运行速度快
原因一: 基于内存运行, 采用DAG(有向无环图)进行计算操作, 可以将中间的结果优先保存到内存中, 如果内存不足也是存储磁盘
原因二: Spark基于线程运行的, 线程的启动和消费是优于进程
Spark认为, 如果基于内存运行, 比MR快100倍 即使基于磁盘运行, 也会快10倍- 2- 易用性
原因一: Spark提供多种语言的客户端,可以基于多种语言来开发Spark程序: Python Sql scala java R ....
目前主推 Python 和 SQL
原因二: Spark提供了更加高阶的API, 而且这些API在不同的语言上, 基本都是一样的, 大大的降低了程序员的学习成本- 3- 通用型
Spark提供了多种组件, 用于满足各种场景的处理工作
Spark Core: Spark的核心库 学习的Spark基础 次重点
主要是用于放置Spark的核心API, 内存管理的API 包括维护RDD的数据结构
Spark SQL: 通过 SQL的方式来操作Spark计算框架 最为重要的
Structured Streaming: 结构化流 基于Spark SQL的之上的组件 用于进行流式计算(实时计算)
Spark Streaming: Spark的流式计算的框架, 主要是用于进行流式计算操作(实时计算)
目前不使用, 整个实时部分主要是基于Flink
Spark MLlib: Spark的机器学习库, 主要是包含了一些机器学习的相关的内容 比如说 回归 聚类 ..... (针对特定人群)
Spark graphX: Spark的图计算库, 比如说: 地区的路程规划 (针对特定人群)
- 4- 随处运行
原因一: 编写的Spark程序可以运行在不同的资源调度平台上: local yarn spark集群 云上调度平台
原因二: Spark程序可以和大数据的生态圈中各种软件进行集成, 便于方便的使用Spark来对接不同的软件整个Spark集群内部 数据通信的框架基于 netty(通信框架)
2. Spark环境安装
2.0 使用大数据统一环境
2.1 Local模式安装
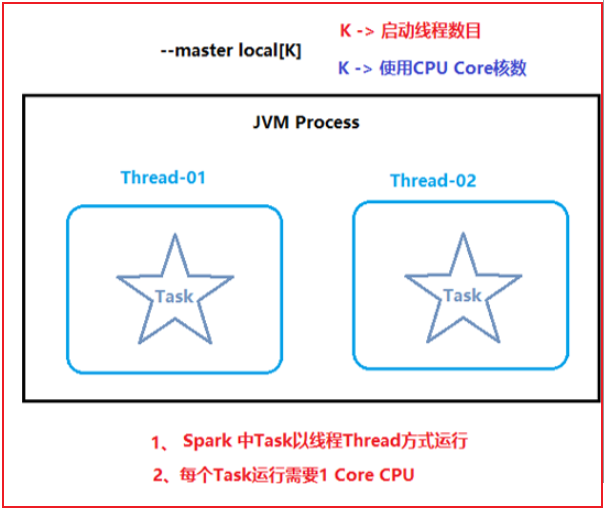
Local模式主要是用于本地代码测试操作
本质上就是一个单进程的程序, 在一个进程中运行多个线程
类似于pandas, 都是一个单进程程序 无法处理大规模的数据, 只处理小规模
安装操作, 可以直接参考课件中<<spark的部署文档>>
- 上传安装包:
要求: 将安装包上传到 某一台linux节点的 /export/software 下
如果想使用rz上传:
请先安装:
yum -y install lrzsz- 注意: 如果使用 浏览器访问 node1:4040 无法访问的时候 尝试去看一下, 在windows本地hosts文件中是否有以下配置
- hosts文件地址: C:\Windows\System32\drivers\etc
192.168.88.161 node1 node1.itcast.cn
192.168.88.162 node2 node2.itcast.cn
192.168.88.163 node3 node3.itcast.cn或者 也有可能没有启动spark的客户端
如何退出客户端: (禁止使用 ctrl + z ,此种操作本质是挂载在后台)
尝试使用以下方式:
ctrl + c
ctrl + d
:quit
quit
!quit
:exit
exit
!exit2.2 PySpark库安装
安装pyspark. 其实就是在python上安装一个pyspark的库, 要求首先必须先有python环境, 而spark要求python环境必须为 3以上版本 
目前虚拟机上安装的python版本为 2.7.5 . 但是实际spark要求版本必须为 3以上的版本,而且在本地windwos上安装python环境也是为3.8.8版本, 需要在虚拟机中也需要安装这个python版本安装 python环境和 pyspark的环境, 可以直接参考部署文档即可
说明:
发现了一个比较奇怪的现象: 在通过 local pyspark shell 访问的时候, 没有安装pyspark, 但是可以进入pyspark环境, 而且还可以编写pyspark的代码, 那这是什么原因呢?
我们说如果想通过python操作spark 必须保证python环境可以加载到pyspark的包,那么也就意味着 虽然我们没有安装, 但是 spark的环境自带了这个pyspark的包, 所以我们才能使用
结论: spark自身环境中带有pyspark的包, 我们只需要提供python环境 即可在spark环境中基于python编写代码了但是我们依然需要大家在python环境中安装pyspark, 那这又是为什么呢?
原因:
当前我们基于spark提供的pyspark的脚本来执行的, 此时加载环境为整个spark环境, 但是后续我们编码的时候, 更多是在pycharm中编写代码, 而pycharm加载环境的时候, 是加载python的环境, 此时python环境中如果没有pyspark,pycharm压根都无法进行导包 编写代码的操作
结论: 我们在python环境中安装pyspark 更多是为了在pycharm中使用, 方便进行导包, 以及本地测试工作
没有必要将多个节点都按照上pyspark, 仅需要在node1的python环境安装即可(后续 pycharm远程连接node1的python环境)扩展: anaconda的常用命令
安装库:
conda install 包名
pip install -i 镜像地址 包名
卸载库:
conda uninstall 包名
pip uninstall 包名
设置 anaconda下载的库的镜像地址:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
如何使用anaconda构建虚拟(沙箱)环境:
1- 查看当前有那些虚拟环境:
conda env list
2- 如何创建一个新的虚拟环境
conda create 虚拟环境名称 python=版本号
例如: 创建一个pyspark_env 虚拟环境
conda create -n pyspark_env python=3.8
3- 如何进入虚拟环境(激活)
source activate pyspark_env
或者
conda activate pyspark_env
4- 如何退出虚拟环境:
deactivate pyspark_env
或者
conda deactivate注意: 如果大家使用的提供统一虚拟环境, 在后续的快照中, 其实将所有的环境都安装完成了, 但是在安装过程中, 出现了一个小失误, 将pyspark库安装为3.2.0版本了, 而不是3.1.2的版本, 所以需要大家卸载3.2.0版本, 安装3.1.2版本 否则后续会存在兼容问题
而且三个节点都安装了3.2.0的版本, 建议大家可以将三个节点都替换为3.1.2,以免引起兼容问题
卸载方式:
pip uninstall pyspark
安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.1.2如何将spark程序, 提交到spark local模式进行执行运行呢?
使用命令:
spark-submit
如何使用(简单使用):
cd /export/server/spark/bin
./spark-submit --master 运行方式 py脚本
案例使用:
./spark-submit --master local[2] /export/server/spark/examples/src/main/python/pi.py 10
整个spark程序大致分为两部分:
一部分是 Driver程序 : 类似于 MR中 appMaster(applicationMaster)角色
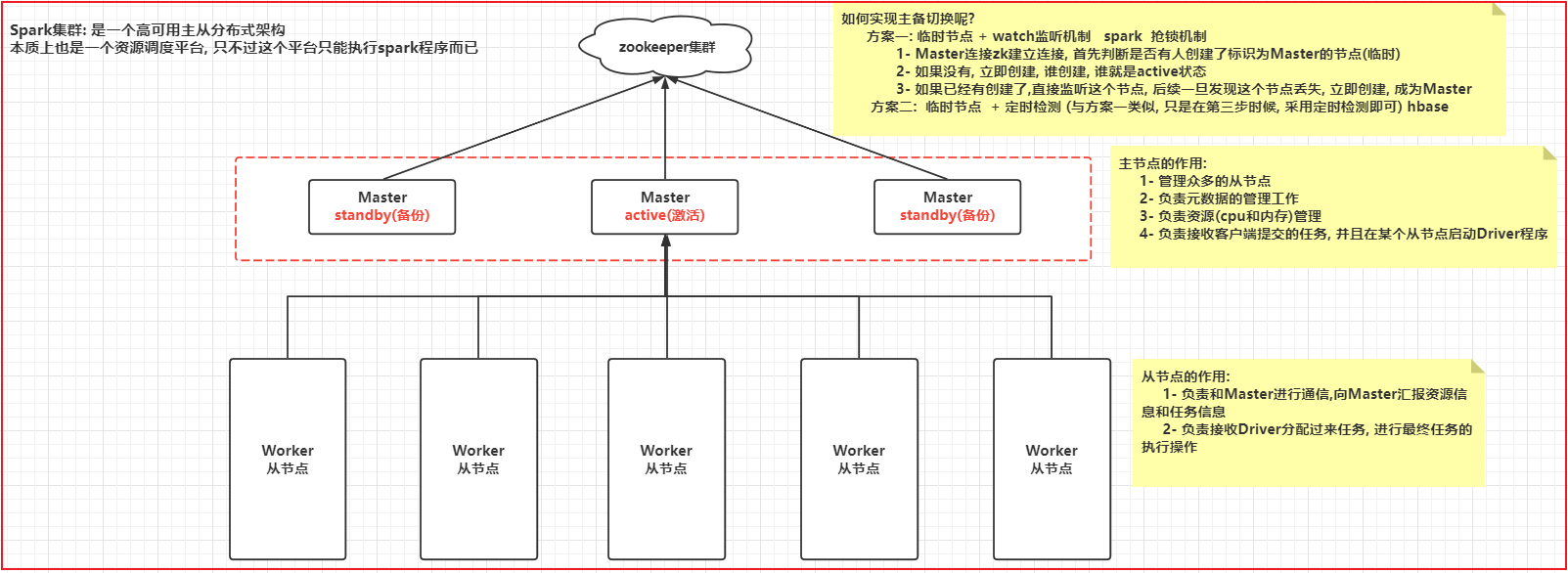
一部分为 executor程序 : 类似于 MR中 mapTask和reduceTask2.3 Spark集群模式架构
高清图 查看图片目录
3. 基于pycharm完成PySpark入门案例
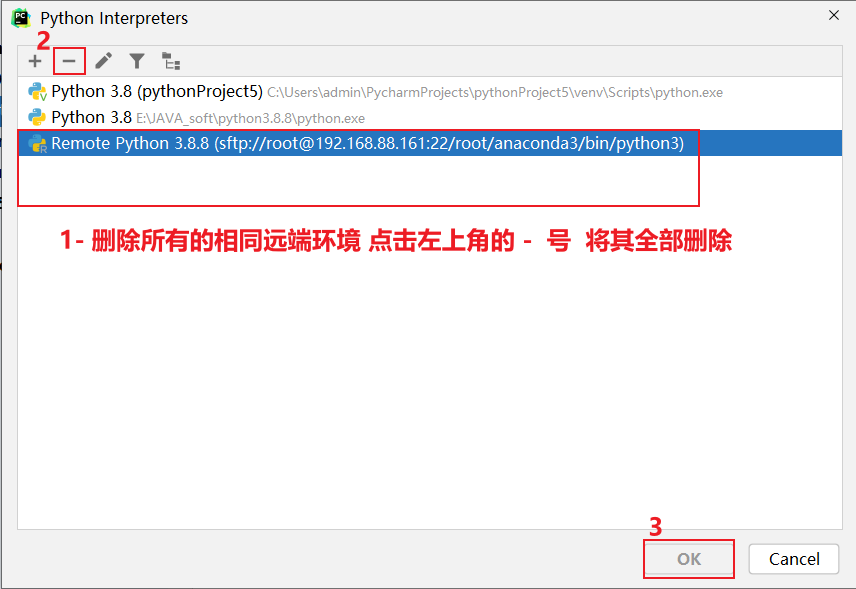
3.0 如何清理远端, 以及如何在已有项目添加远端
清理远端步骤:
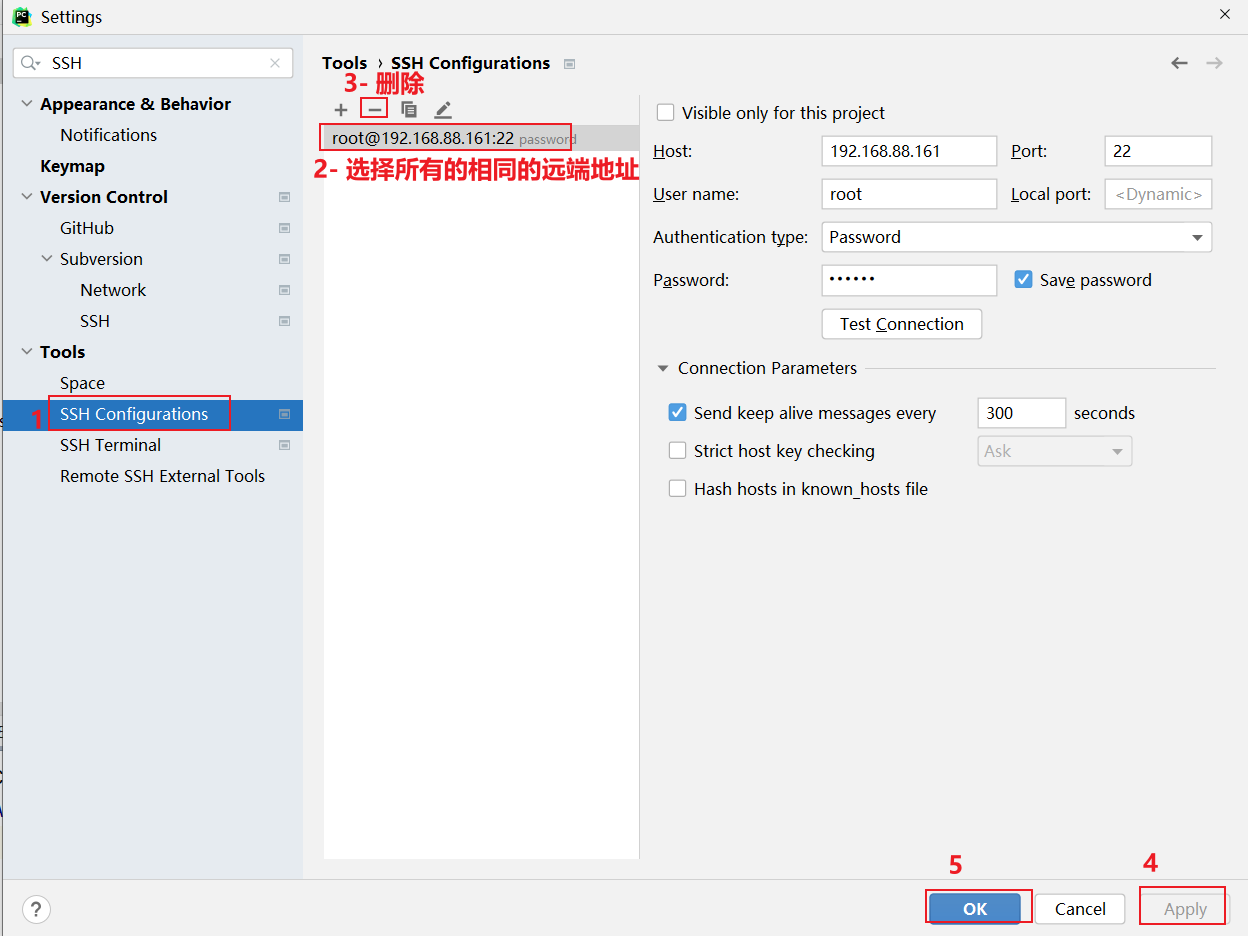
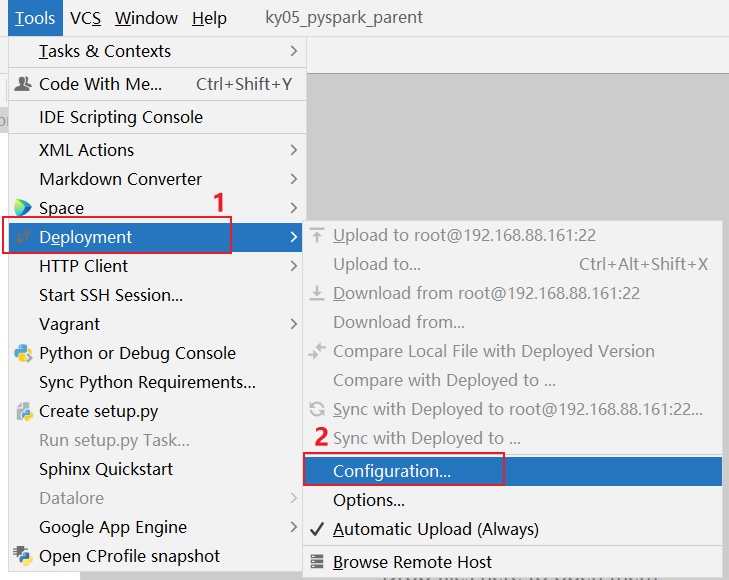
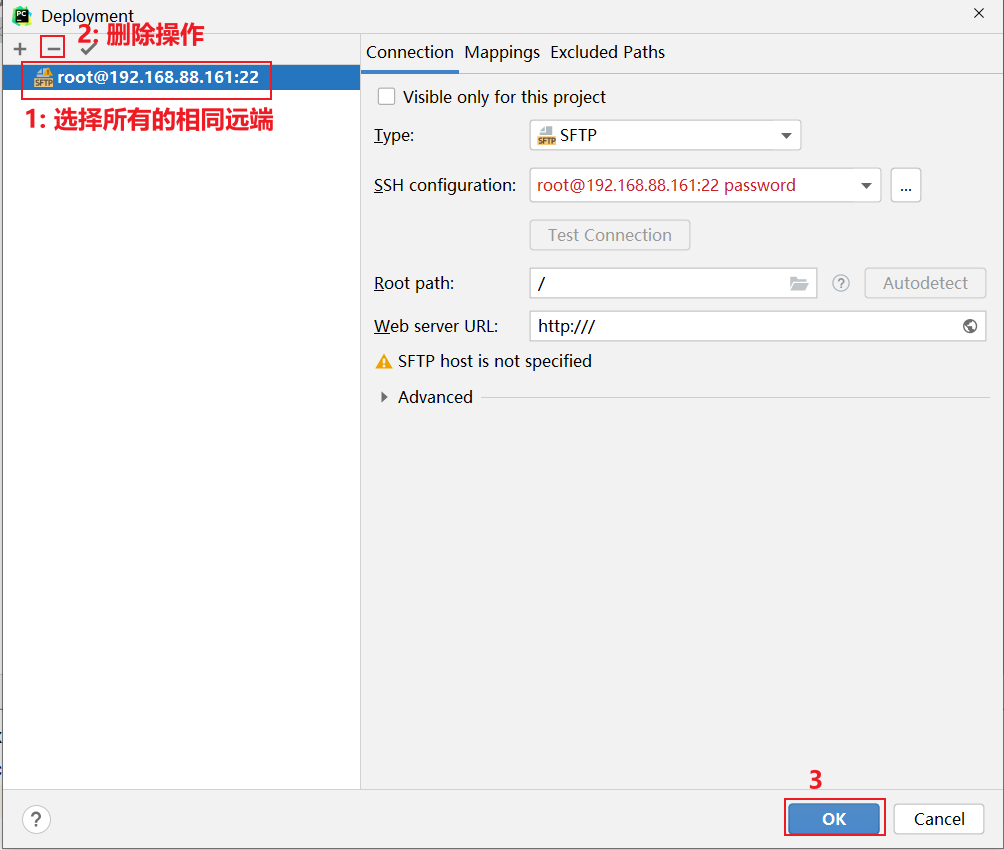
如何在添加远端呢?
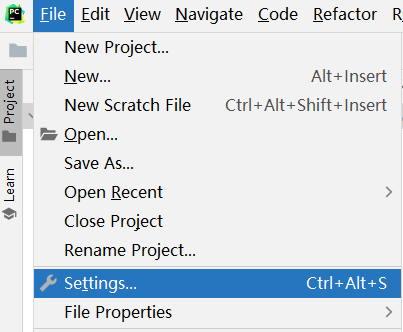
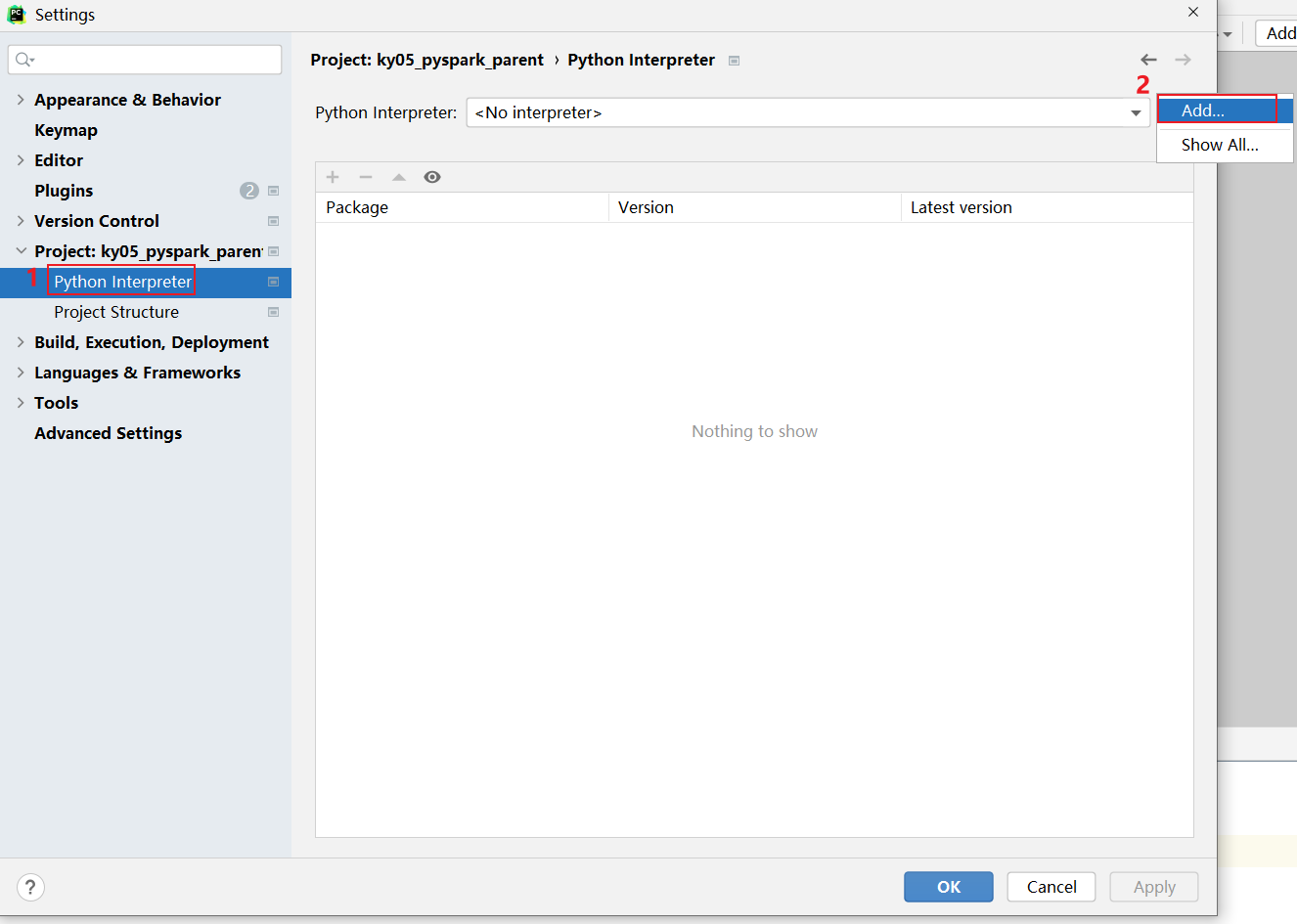
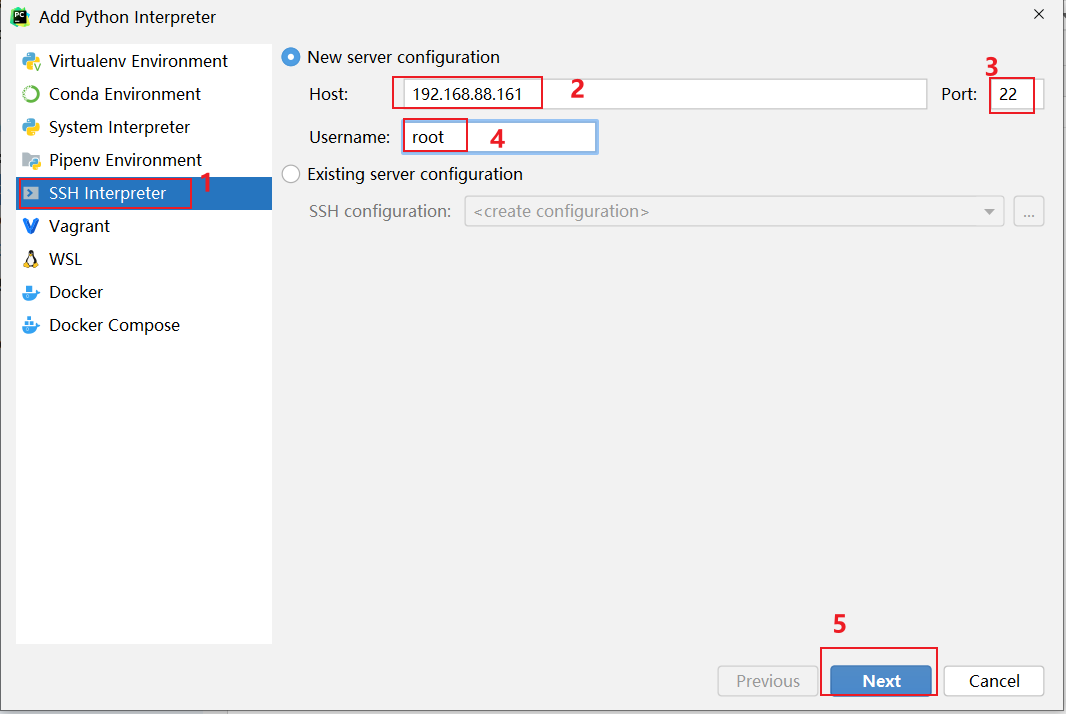
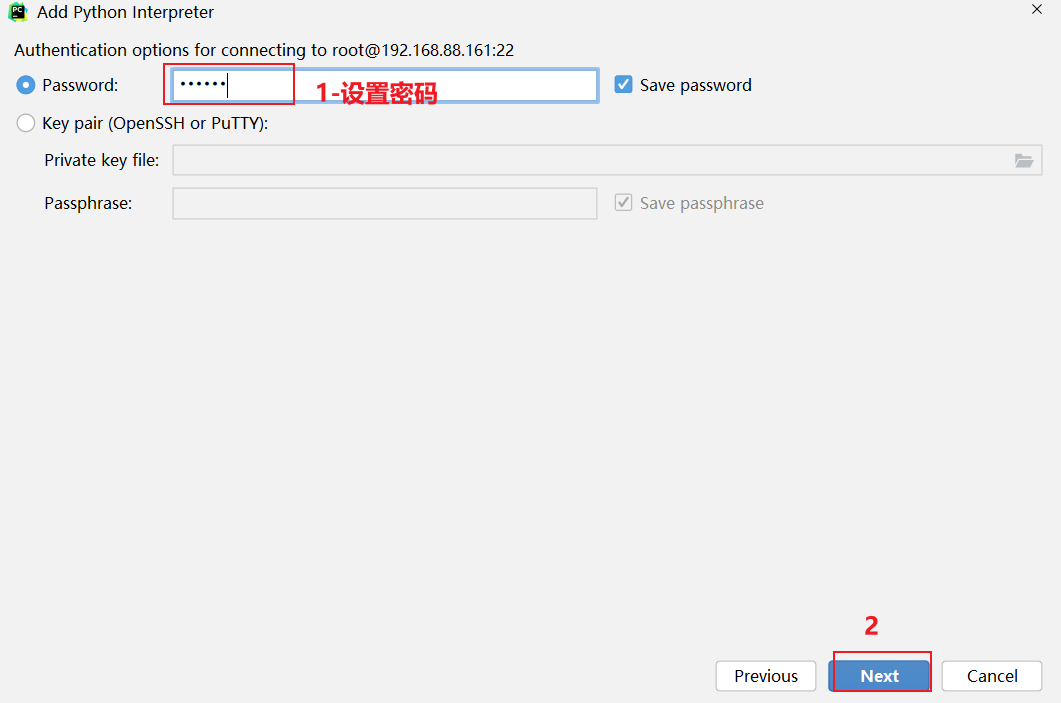
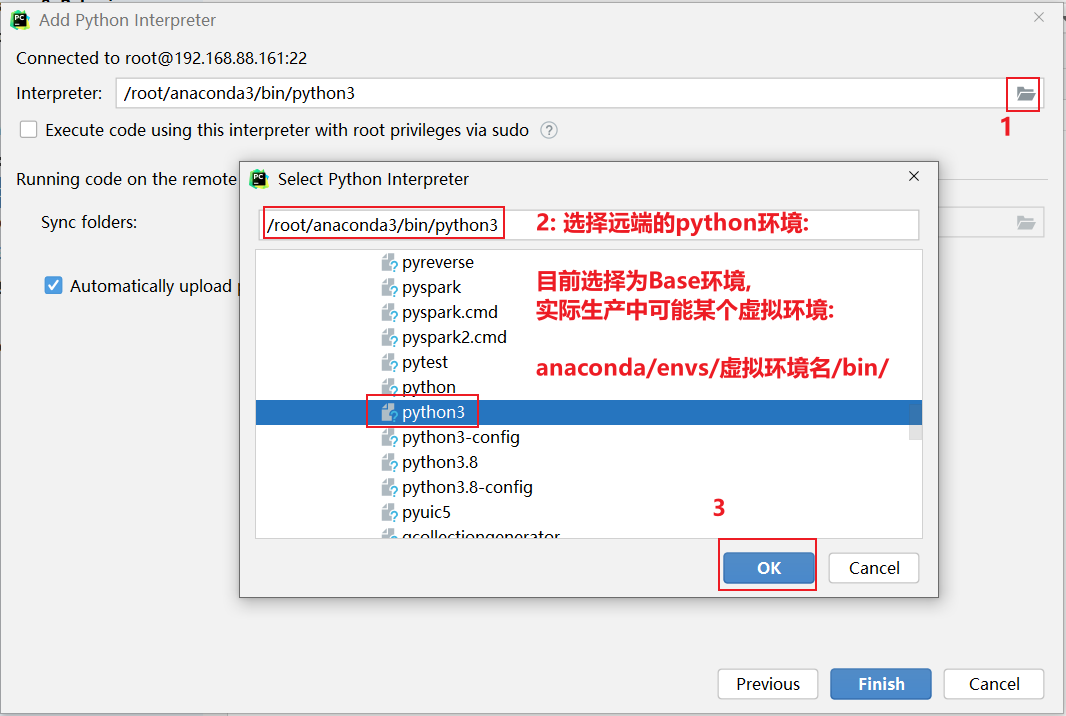
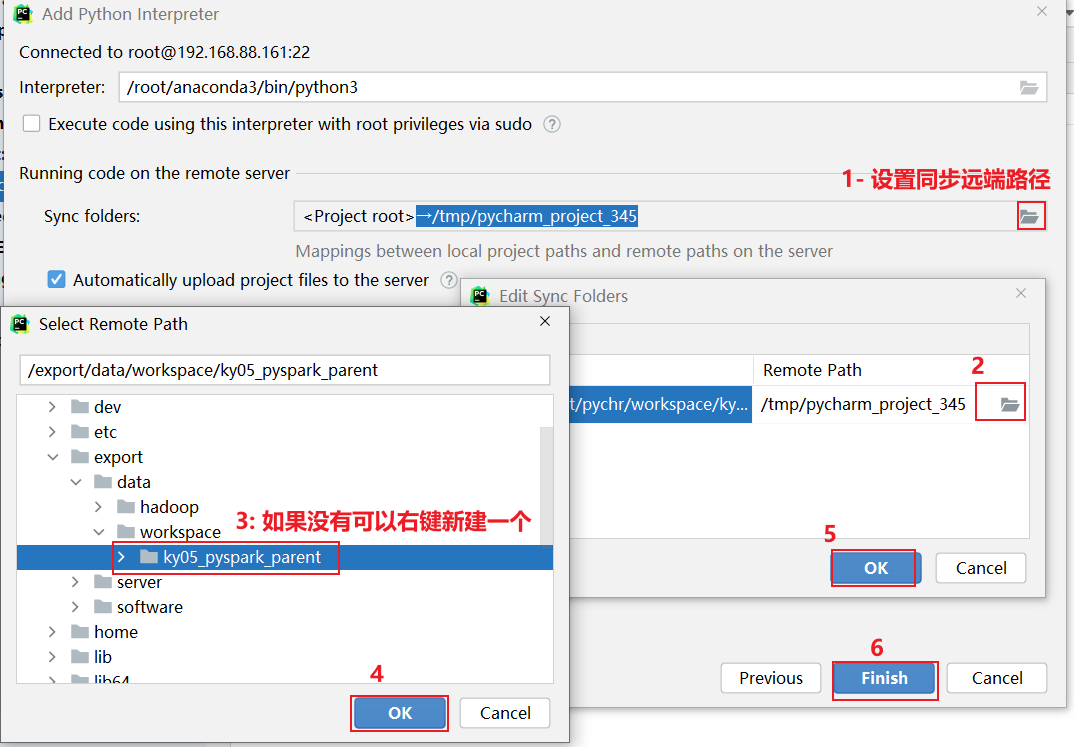
3.1 pycharm连接远程环境
背景说明:
一般在企业中, 会存在两套线上环境, 一套环境是用于开发(测试)环境, 一套环境是用于生产环境, 首先一般都是先在开发测试环境上进行编写代码, 并且在此环境上进行测试, 当整个项目全部开发完成后, 需要将其上传到生产环境, 面向用户使用
如果说还是按照之前的本地模式开发方案, 每个人的环境有可能都不一致, 导致整个团队无法统一一套开发环境进行使用, 从而导致后续在进行测试 上线的时候, 出现各种各样环境问题
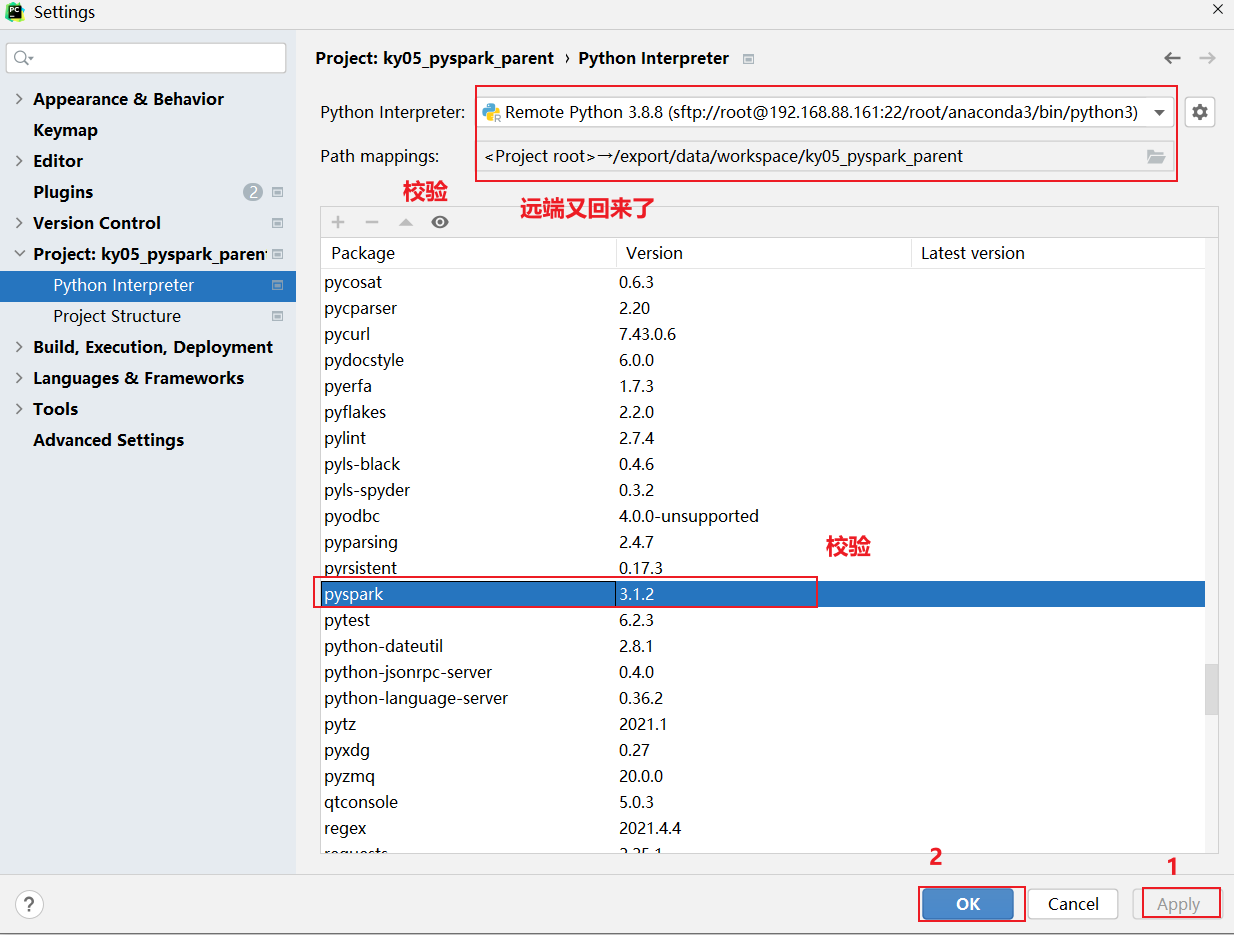
pycharm提供了一些解决方案: 远程连接方案, 允许所有的程序员都去连接远端的测试环境的, 确保大家的环境都是统一, 避免各种环境问题发生, 而且由于连接的远程环境, 所有在pycharm编写代码, 会自动上传到远端环境中, 在执行代码的时候, 相当于是直接在远端环境上进行执行操作操作实现: 本次这里配置远端环境, 指的连接虚拟机中虚拟环境, 可以配置为 base环境, 也可以配置为 pyspark_env虚拟环境, 但是建议配置为 base环境, 因为base环境自带python包更全面一些
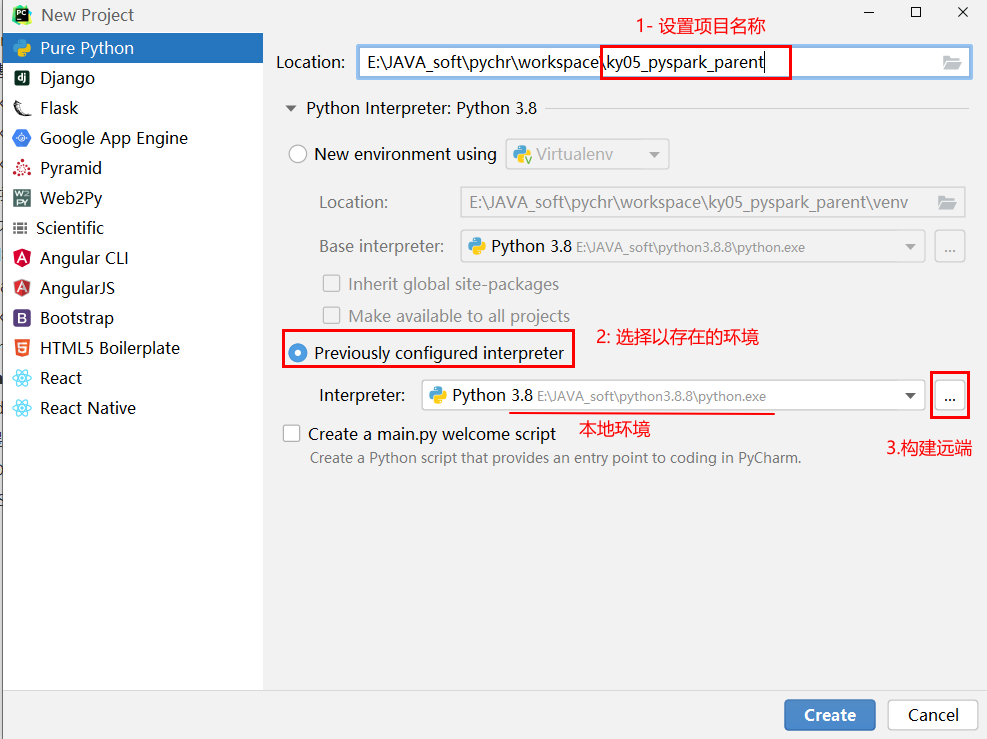
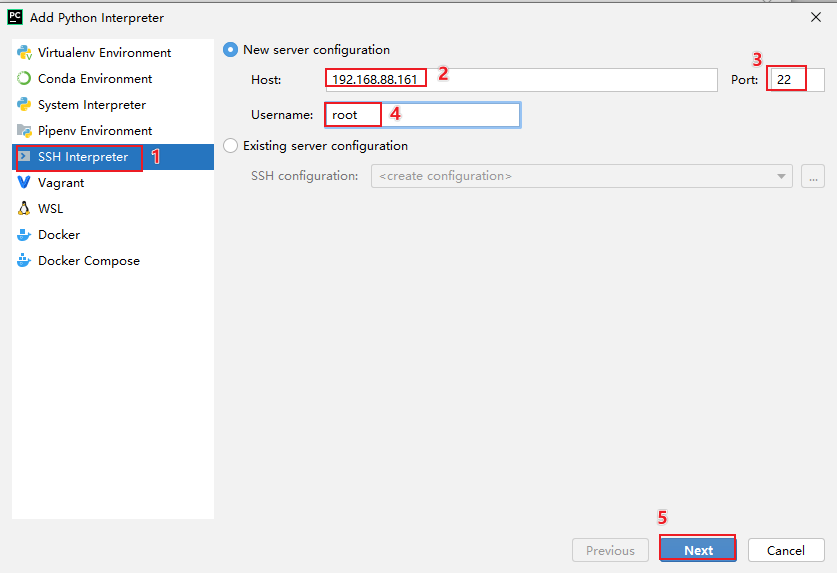
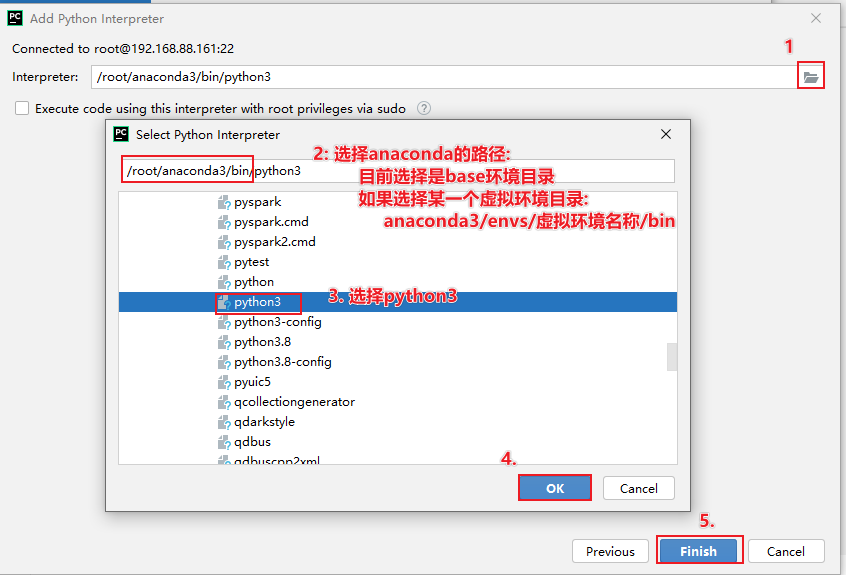
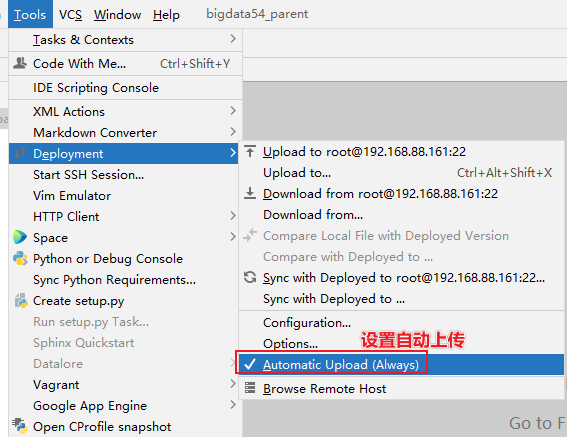
创建项目后, 设置自动上传操作
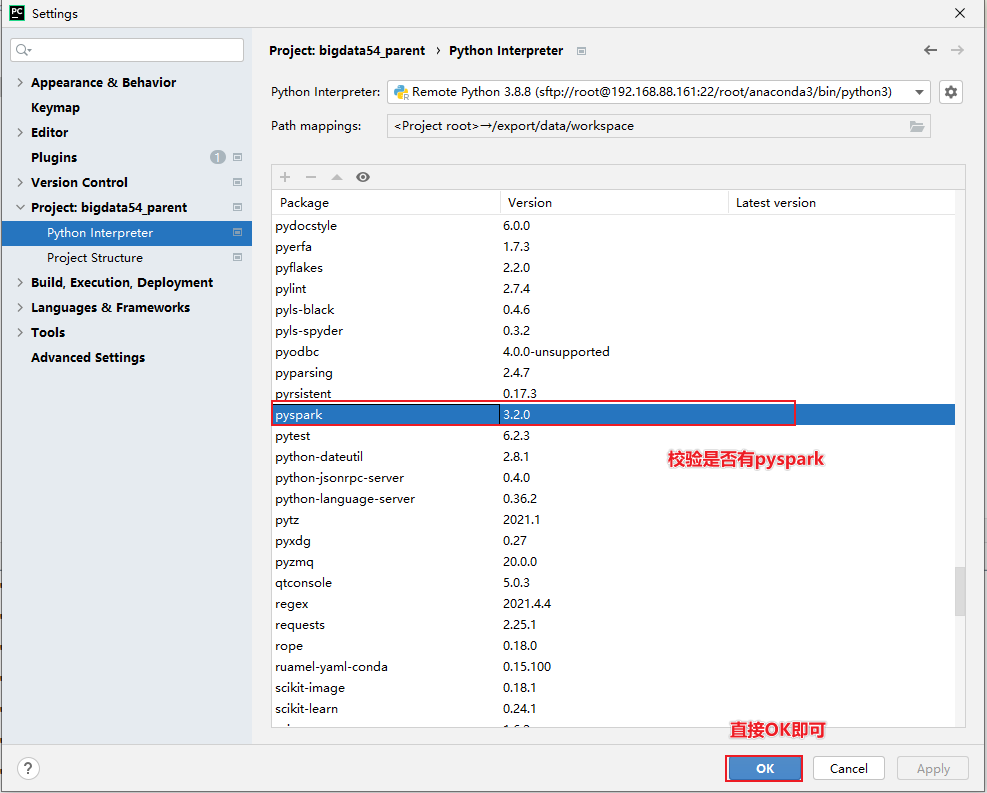
校验是否有pyspark
ok 后, 就可以在项目上创建子项目进行干活了: 最终项目效果图
最后, 就可以在 main中编写今日代码了, 比如WordCount代码即可
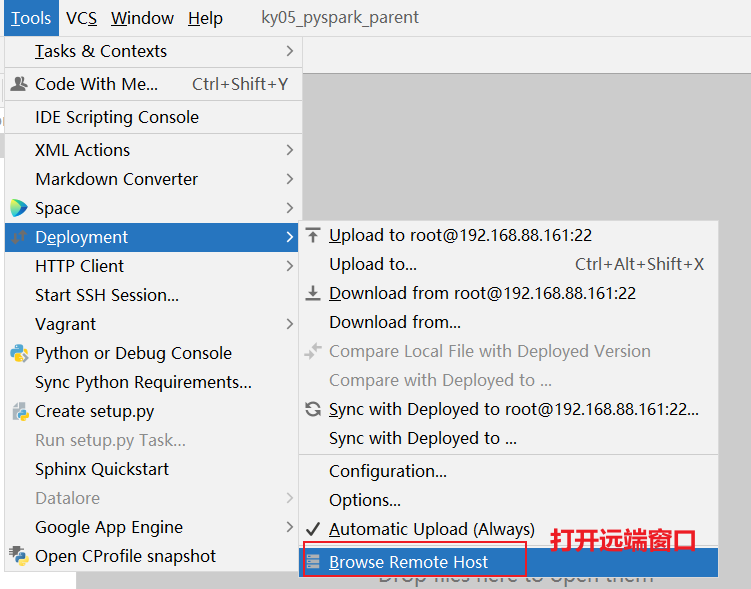
如何在pycharm打开远端窗口:
3.2 WordCount代码实现_Local
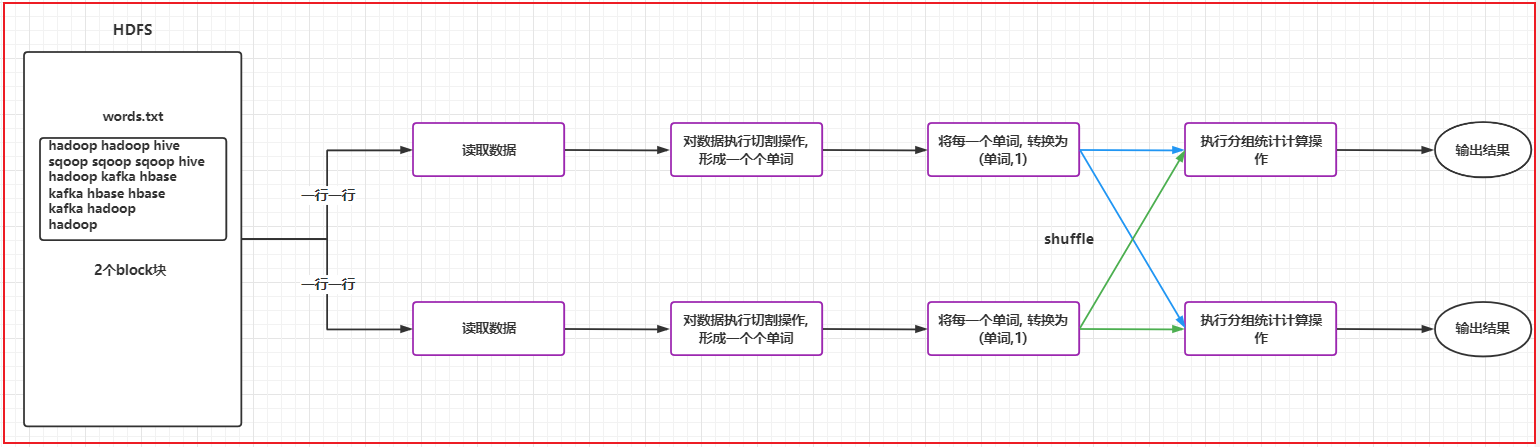
3.2.1 WordCount案例流程实现
3.2.2 代码实现
# 演示WordCount实现代码
from pyspark import SparkContext, SparkConf
import os
# 锁定远程的环境版本(固定代码): 写了一定是没问题的, 但是不写可能会报错
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 在spark程序中, 如果基于python来编写spark代码. 要求python程序必须得有入口类
# main函数快捷键: main + 回车
if __name__ == '__main__':
print('演示WordCount实现')
# 1- 创建SparkContext对象:
conf = SparkConf().setAppName('WordCount').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2- 读取外部文件数据源
# 参数1: 表示文件的路径 支持 HDFS 本地 或者 HDFS支持的文件系统
# 如果本地文件: file:///路径地址
# 如果HDFS文件: hdfs://node1:8020/路径
# 注意: 由于使用远端环境, 所有的代码都是在远端运行, 所以此处的本地路径应该指的是linux的本地路径 而非windows的本地路径
# 默认是一行一行的进行读取操作
rdd_init = sc.textFile('file:///export/data/workspace/ky05_pyspark_parent/_01_pyspark_base/data/words.txt')
# 3- 处理数据
# 3.1 对数据执行切割操作
"""
rdd_init处理的后数据:
['hello world hello hadoop', 'hadoop hello world hive', 'hive hive hadoop', 'hadoop hadoop hive']
希望处理后得到结果如下:
[
hello,world,hello,hadoop,hadoop,hello,world,hive,hive,hive,hadoop,hadoop,hadoop,hive
]
"""
# 演示一对一: map
# def map_fn(line):
# return line.split(' ')
# 当函数只有一行的时候, 可以简写函数
#rdd_map = rdd_init.map(lambda line: line.split(' '))
"""
处理后的结果: 胖列表
[
['hello', 'world', 'hello', 'hadoop'],
['hadoop', 'hello', 'world', 'hive'],
['hive', 'hive', 'hadoop']
]
"""
# 演示 一 对 多: flapMap()
rdd_flatMap = rdd_init.flatMap(lambda line: line.split(' '))
"""
处理后结果:
[
'hello', 'world', 'hello', 'hadoop',
'hadoop', 'hello', 'world', 'hive',
'hive', 'hive', 'hadoop'
]
"""
# 3.2 将每一个单词转换为 单词,1 形式
rdd_map = rdd_flatMap.map(lambda word:(word,1))
"""
得到的结果:
[('hello', 1), ('world', 1), ('hello', 1), ('hadoop', 1), ('hadoop', 1), ('hello', 1), ('world', 1)]
"""
# 3.3 根据key进行分组聚合统计
# 说明 a 和 b 都是value的值, ByKey 用于进行分组操作, 将每一组中value数据传递给函数来进行聚合计算操作
#
def fn1(a,b):
print(f'{a}-{b}')
return a + b
# 说明:
# 函数的参数1 表示的是局部聚合的结果, 默认值为每组的第一个值 1
# 函数的参数2 表示的每组中每一次遍历的value的值
# 每一次计算, 都是将计算的结果赋值给了agg
rdd_res = rdd_map.reduceByKey(lambda agg,curr: agg + curr)
print(rdd_res.collect())
# 4- 释放资源
sc.stop()简单写法(合并写法): 链式编程法
# 演示WordCount实现代码
from pyspark import SparkContext, SparkConf
import os
# 锁定远程的环境版本(固定代码): 写了一定是没问题的, 但是不写可能会报错
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 在spark程序中, 如果基于python来编写spark代码. 要求python程序必须得有入口类
# main函数快捷键: main + 回车
if __name__ == '__main__':
print('演示WordCount实现')
# 1- 创建SparkContext对象
conf = SparkConf().setAppName('WordCount').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2- 读取外部数据源
rdd_init = sc.textFile('file:///export/data/workspace/ky05_pyspark_parent/_01_pyspark_base/data/words.txt')
# 3- 数据处理
print(rdd_init.flatMap(lambda line: line.split(' ')).map(lambda word: (word, 1)).reduceByKey(
lambda agg, curr: agg + curr).collect())
# 4- 释放资源
sc.stop()可能出现的问题:
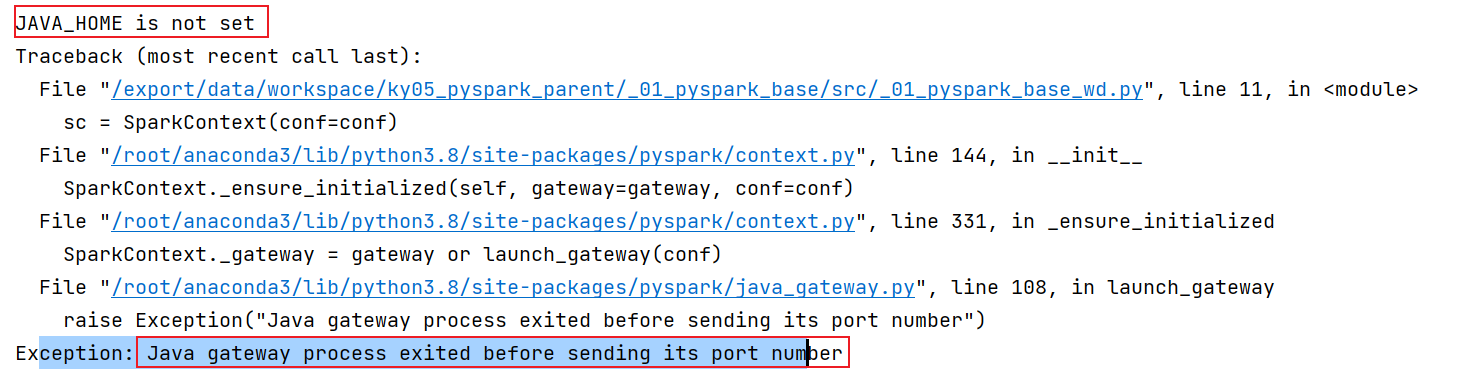
异常: JAVA_HOME is not set
出现位置: 当pycharm采用SSH连接远程python环境的时候, 在启动执行的时候, 可能会爆出来此错误
原因: 当前python环境无法加载到JDK位置
解决方案:
第一步: 需要在linux的 /root/.bashrc 文件中, 添加以下相关内容:
export JAVA_HOME=/export/server/jdk1.8.0_241/
export PYSPARK_PYTHON=/root/anaconda3/bin/python3
第二步: 在代码中, 指定linux中spark环境所在目录
# 锁定远程的环境版本(固定代码): 写了一定是没问题的, 但是不写可能会报错
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'3.3 [扩展]部署windows开发环境(不需要做)
- 1- 第一步: 需要安装Python 环境 , 建议使用anaconda 来安装即可
- 2- 第二步: 在Python安装pySpark
执行:
pip install pyspark==3.1.2
- 3- 第三步: 配置 hadoop的环境

首先, 需要将 hadoop-3.3.0 放置到一个没有中文, 没有空格的目录下
接着将目录中bin目录下有一个 hadoop.dll文件, 放置在c:/windows/system32 目录下 (配置后, 需要重启电脑)
最后, 将这个hadoop3.3.0 配置到环境变量中: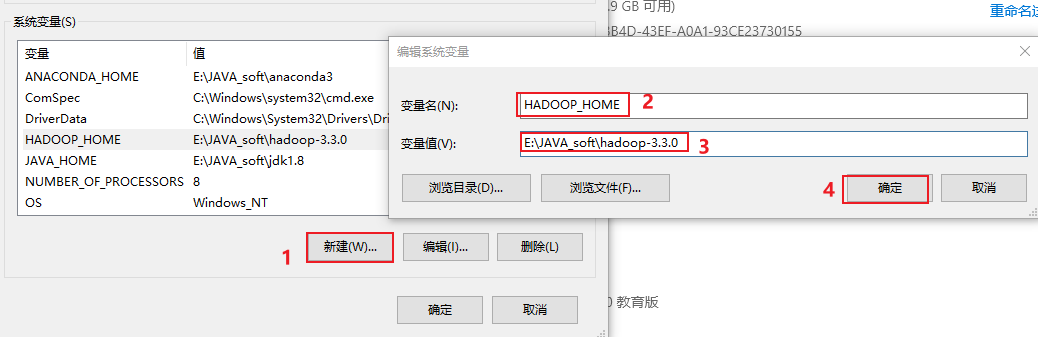
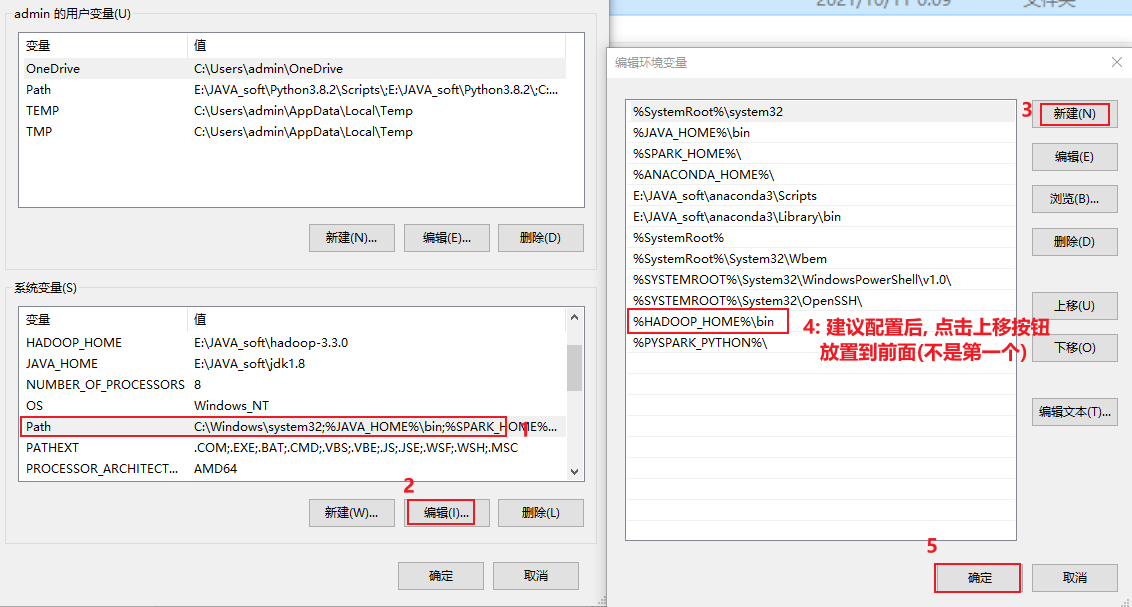
配置后, 一定一直点确定退出, 否则就白配置了....
- 4-第四步: 配置spark本地环境

首先, 需要将 spark-3.1.2... 放置到一个没有中文, 没有空格的目录下
最后, 将这个 spark-3.1.2... 配置到环境变量中: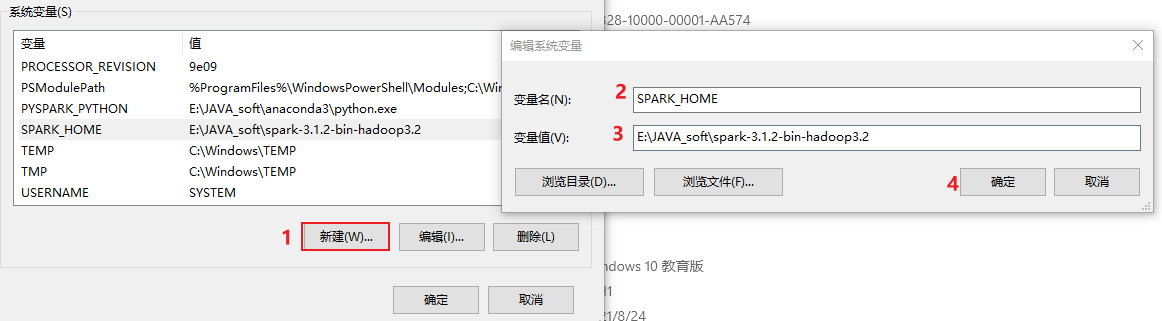
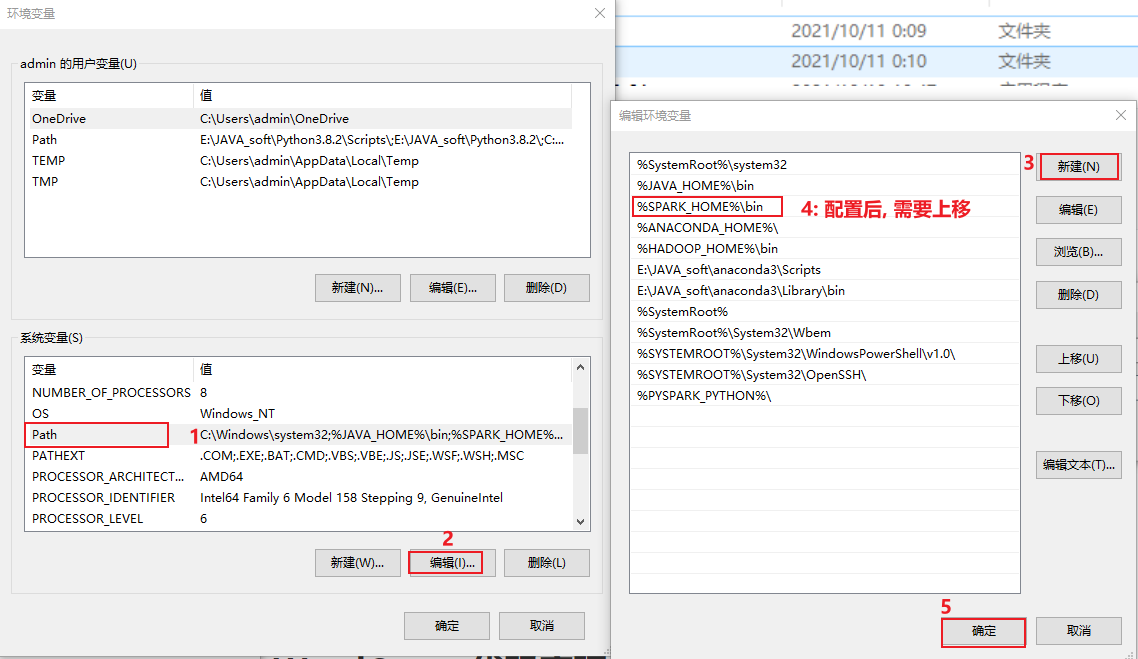
配置后, 一定一直点确定退出, 否则就白配置了....
- 5-配置pySpark环境
需要修改环境变量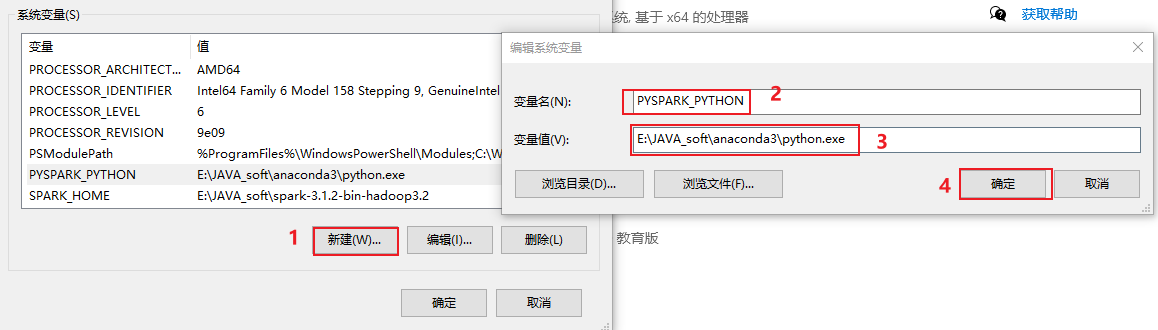

配置后, 一定一直点确定退出, 否则就白配置了....
- 6- 配置 jdk的环境:
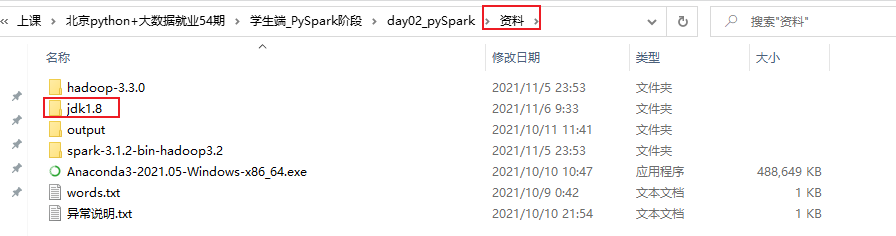
首先: 需要将 jdk1.8 放置在一个没有中文, 没有空格的目录下
接着:要在环境变量中配置 JAVA_HOME, 并在path设置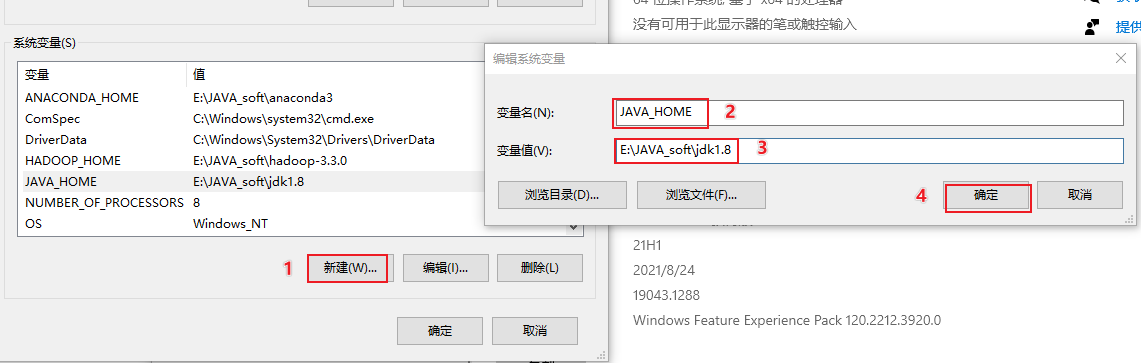
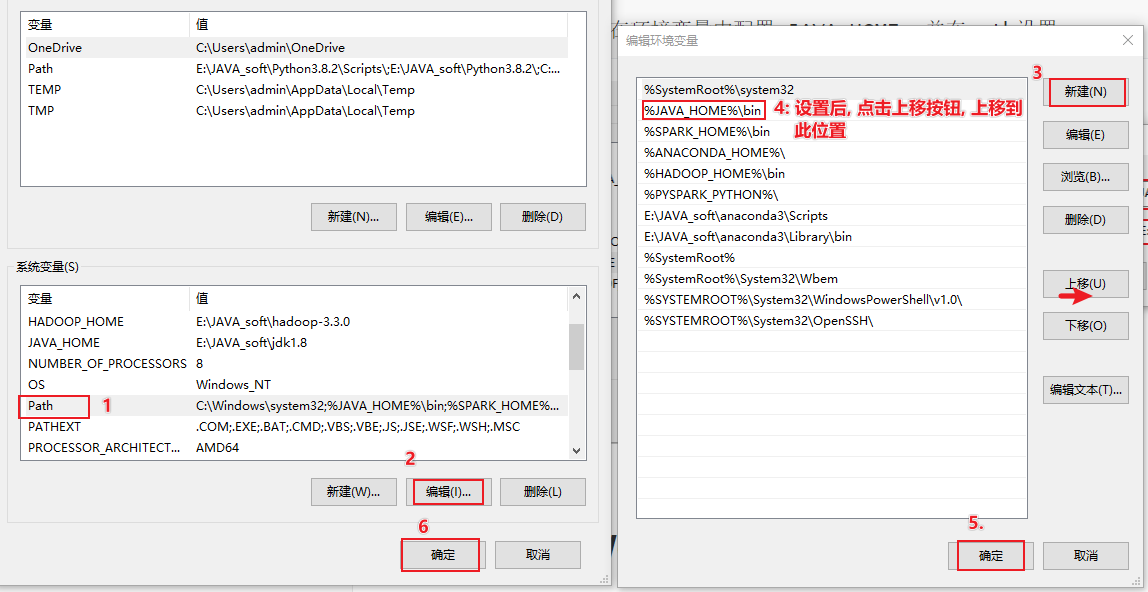
3.4 从HDFS上读取文件并实现排序
# 演示WordCount实现代码
from pyspark import SparkContext, SparkConf
import os
# 锁定远程的环境版本(固定代码): 写了一定是没问题的, 但是不写可能会报错
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 在spark程序中, 如果基于python来编写spark代码. 要求python程序必须得有入口类
# main函数快捷键: main + 回车
if __name__ == '__main__':
print('演示WordCount实现: 从HDFS读取数据, 并且对结果数据进行排序操作, 将结果保存到目的地')
# 1- 创建SparkContext对象
conf = SparkConf().setAppName('WordCount').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2- 读取外部数据源: HDFS
rdd_init = sc.textFile('hdfs://node1:8020/words.txt')
# 3 - 数据处理操作
rdd_flatMap = rdd_init.flatMap(lambda line: line.split())
rdd_map = rdd_flatMap.map(lambda word:(word,1))
rdd_res = rdd_map.reduceByKey(lambda agg,curr: agg + curr)
# 希望输出的结果, 可以根据value进行排序操作, 倒序排序
#rdd_sort = rdd_res.sortBy(lambda res_tup:res_tup[1],ascending=False)
# 以下操作, 纯属娱乐, 没有实际价值, 只是为了演示sortByKey的作用 以及对map的理解
#rdd_res = rdd_res.map(lambda res_tup:(res_tup[1],res_tup[0]))
#rdd_sort = rdd_res.sortByKey(ascending=False)
#rdd_sort = rdd_sort.map(lambda res_tup: (res_tup[1], res_tup[0]))
# # 默认如果数据是kv类型的数据, 按照key进行倒序排序, 如果需要对value, 可以设置函数来指定排序的内容
# top只能做倒序, 直接返回结果
print(rdd_res.top(10,lambda res_tup:res_tup[1]))
# 输出目的地
rdd_res.saveAsTextFile('hdfs://node1:8020/wd/output')
# 4- 释放资源
sc.stop()总结:
排序相关的API:
sortBy(设置排序的规则, 是否为倒序) 返回的RDD的对象
sortByKey(是否为倒序) 返回的RDD对象
top(N,可选的函数) 直接得结果, 不需要使用collect收集 也无法在调用 saveAsTextFile
输出目的地API:
saveAsTextFile(路径)