
Hadoop搭建
资料
大数据导论
大数据业务分析基本步骤
- 明确分析目的和思路-->数据收集-->数据处理-->数据分析-->数据展现-->报告撰写
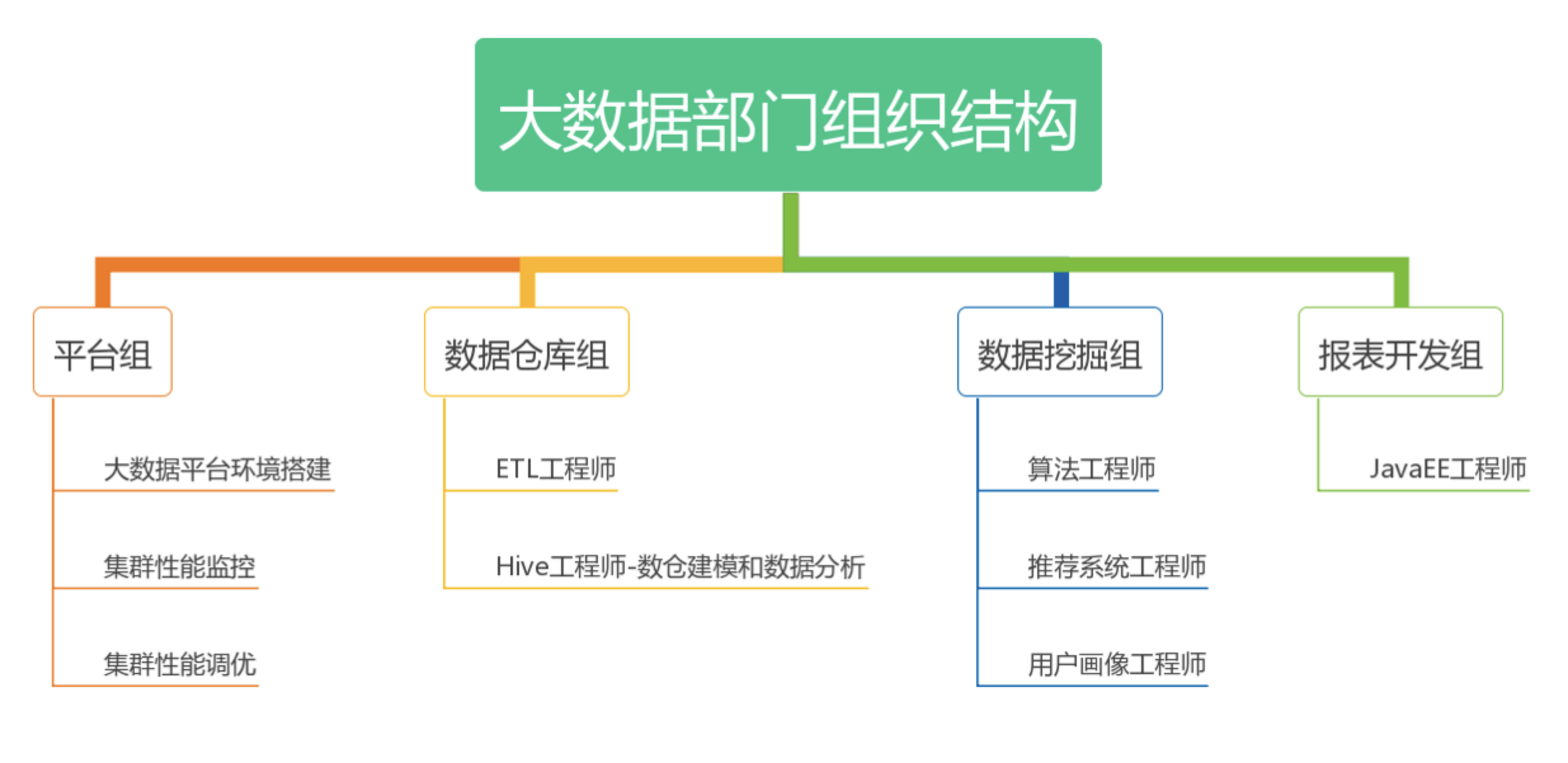
大数据部门的组织结构
分布式技术
为什么需要分布式
计算问题
无论是线程、进程,本质上目的都是喂了计算的并行化,解决的是算的慢的问题。如果计算量足够大,就算榨干了机器的计算能力也算不过来。所以就从多线程/进程的计算并行化,金华到计算的分布式化。(分布式一定程度上也是并行化)
存储问题
把数据分散到多台机器,本质上解决的是存不下的问题。同时,如果计算分布式化后,总不能所有程序都去同一台机器读数据,这样效率必然会受到单台机器的性能拖累,比如磁盘IO、网络带宽等。因此数据存储也要分散到各个机器上。
分布式系统概述
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
Hadoop概述
Hadoop介绍
Apache旗下一个用java语言实现的开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
- 核心组件
- HDFS:分布式文件系统,解决海量数据存储
- YARN:作业调度和集群资源管理的框架,解决资源任务调度
- MAPREDUCE:分布式运算编程框架,解决海量数据计算
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈
| 框架 | 用途 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式运算程序开发框架 |
| ZooKeeper | 分布式协调服务基础组件 |
| HIVE | 基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作 |
| FLUME | 日志数据采集框架 |
| oozie | 工作流调度框架 |
| Sqoop | 数据导入导出工具(比如用于mysql和HDFS之间) |
| Impala | 基于hive的实时sql查询分析 |
| Mahout | 基于mapreduce/spark/flink等分布式运算框架的机器学习算法库 |
Hadoop架构

Hadoop集群
集群简介
- Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
- HDFS集群负责海量数据存储,集群中主要角色有
- NameNode、DataNode、SecondaryNameNode
- YARN集群负责海量数据运算时的资源调度,集群中主要角色有
- ResourceManager、NodeManager
- MapReduce实际上是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
集群部署方式
- standalone mode(独立模式)
- Pseudo-Distributed mode(伪分布式模式)
- Cluster mode(群集模式)
- 集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
Hadoop集群架构模型
- NameNode与ResourceManager单节点架构模型
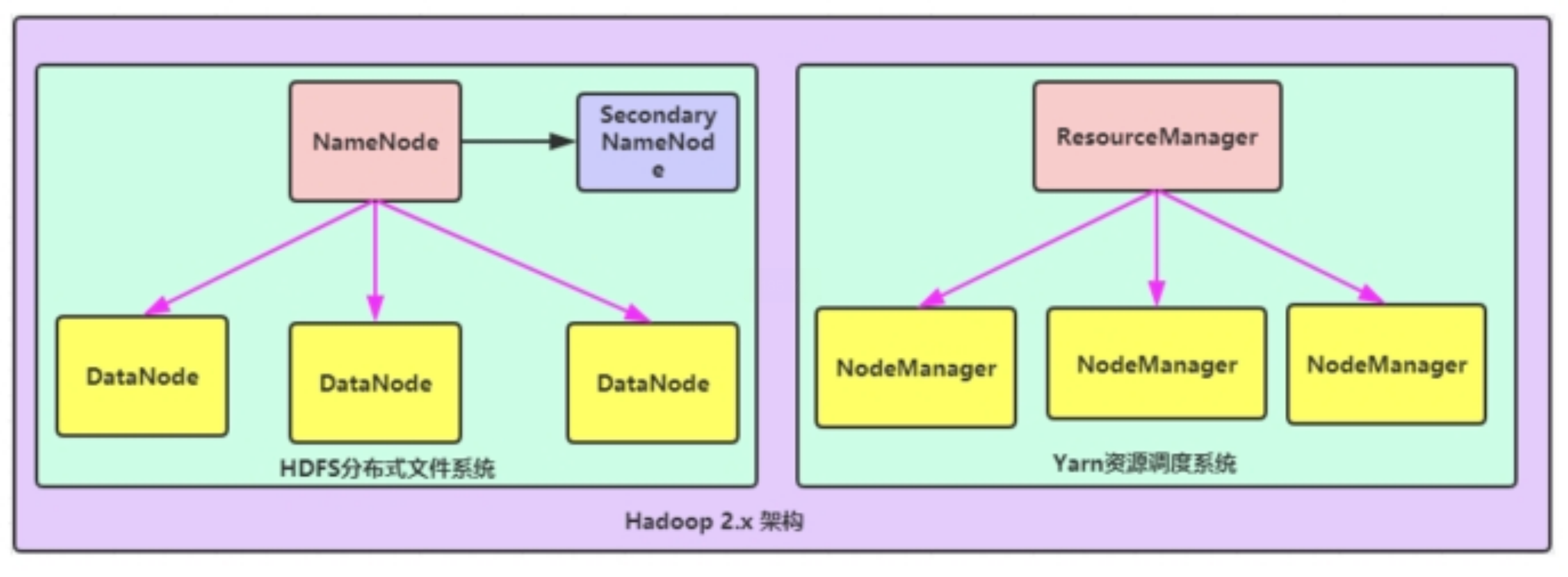 文件系统核心模块: NameNode:集群当中的主节点,主要用于管理集群当中的各种数据 secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理 DataNode:集群当中的从节点,主要用于存储集群当中的各种数据 数据计算核心模块: ResourceManager:接收用户的计算请求任务,并负责集群的资源分配 NodeManager:负责执行主节点APPmaster分配的任务
文件系统核心模块: NameNode:集群当中的主节点,主要用于管理集群当中的各种数据 secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理 DataNode:集群当中的从节点,主要用于存储集群当中的各种数据 数据计算核心模块: ResourceManager:接收用户的计算请求任务,并负责集群的资源分配 NodeManager:负责执行主节点APPmaster分配的任务
- NameNode高可用、ResourceManager单节点
- NameNode单节点、ResourceManager高可用
- NameNode与ResourceManager高可用
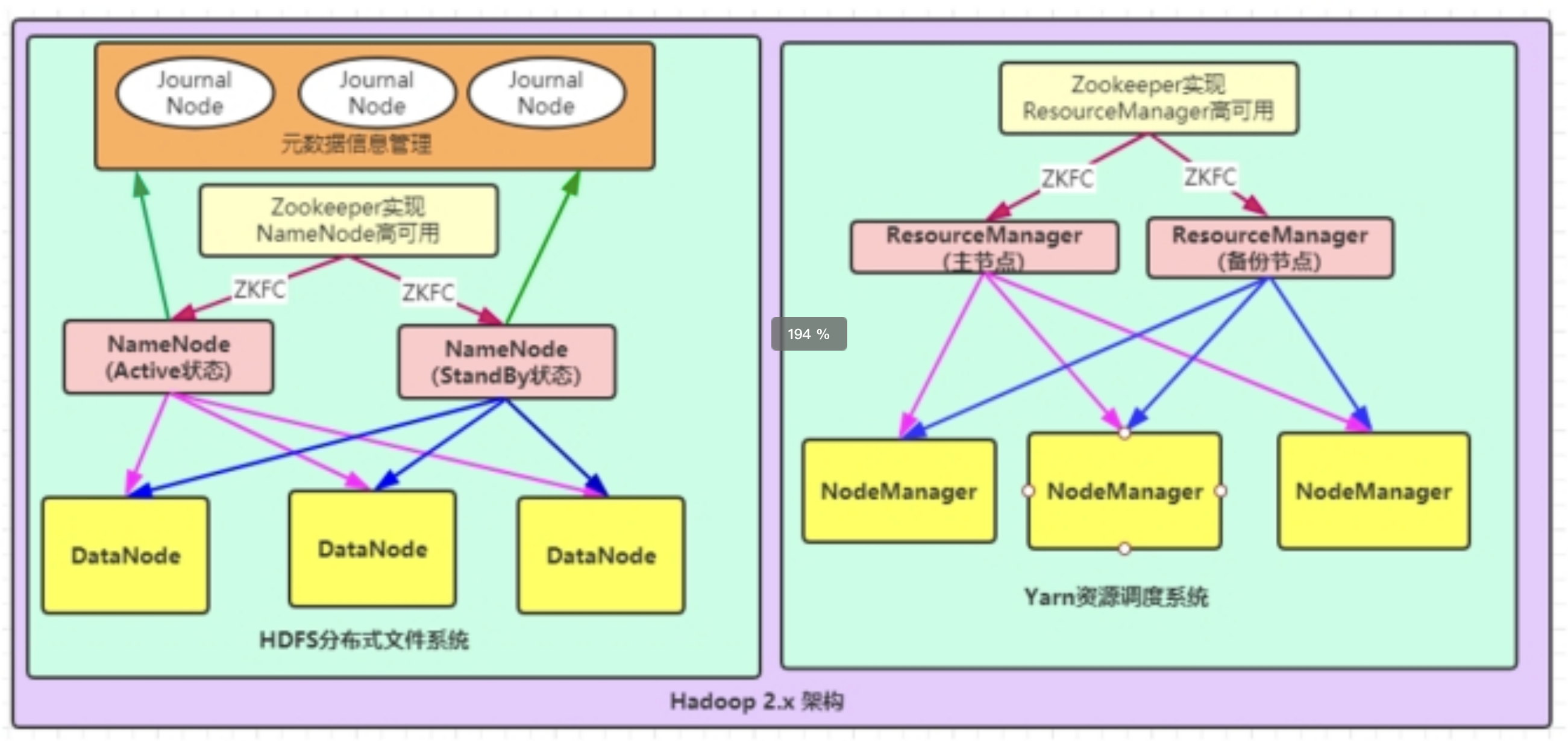 文件系统核心模块: NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用 JournalNode:元数据信息管理进程,一般都是奇数个 DataNode:从节点,用于数据的存储
文件系统核心模块: NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用 JournalNode:元数据信息管理进程,一般都是奇数个 DataNode:从节点,用于数据的存储
数据计算核心模块: ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用 NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
集群搭建规划
| 节点信息 | 10G/ 2cores | 7G / 2cores | 7G / 2cores | |
|---|---|---|---|---|
| node1 | node2 | node3 | ||
| HDFS集群 | ||||
| 守护进程 | NameNode | √ | × | × |
| SecondaryNameNode | × | √ | × | |
| DataNode | √ | √ | √ | |
| YARN集群 | ||||
| 守护进程 | ResourceManager | √ | × | × |
| NodeManager | √ | √ | √ |
搭建过程见资料
Hadoop安装目录结构说明
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
|---|---|
| etc | Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录,官方自带示例。 |
Hadoop配置文件
hadoop-env.sh
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
core-site.xml
- hadoop的核心配置文件,有默认的配置项core-default.xml。
- core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
hdfs-site.xml
- HDFS的核心配置文件,主要配置HDFS相关参数,有默认的配置项hdfs-default.xml。
- hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
mapred-site.xml
- MapReduce的核心配置文件,Hadoop默认只有个模板文件mapred-site.xml.template,需要使用该文件复制出来一份mapred-site.xml文件。
yarn-site.xml
- YARN的核心配置文件,在该文件中的configuration标签中添加以下配置
workers
- workers文件里面记录的是集群主机名。一般有以下作用
- 配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候workers文件里面的主机标记的就是从节点角色所在的机器。
HDFS基准测试
测试写入速度
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB测试读取速度
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB清除测试数据
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -clean