Flink_1
Chapter1_Flink基础
本章目标
- 【了解】- Flink基础的课程介绍
- 【理解】- Flink的批处理和流处理的概念
- 【了解】- Flink概述
- 【理解】- Flink框架如何进行搭建和部署的
- 【理解】- Flink的运行时架构
- 【会用】- Flink的入门案例(DataStream API)流处理应用
课程介绍
批处理与流处理
知识点01:【了解】批处理和实时流处理的区别
- 批处理:对有界的数据进行处理就是批处理。
有界的数据:明确定义了开始和结束。
- 实时流处理:对无界的数据流进行实时处理就是流处理。
无界的数据流:可以认为有开始,没有结束,不知道何时会终止提供数据。
知识点02:【了解】批处理与流处理对比的特点
- 批处理程序的容错不使用检查点。因为数据有限,所以恢复可以通过“完全重播”(重新处理)来实现。这种处理方式会降低常规处理的成本,因为它可以避免检查点
- 批处理的特点是:有界、持久、大量,用于离线计算。
- 流处理的特点是:无界、实时、用于实时计算。
Flink概述
知识点03:【理解】Flink官方简介
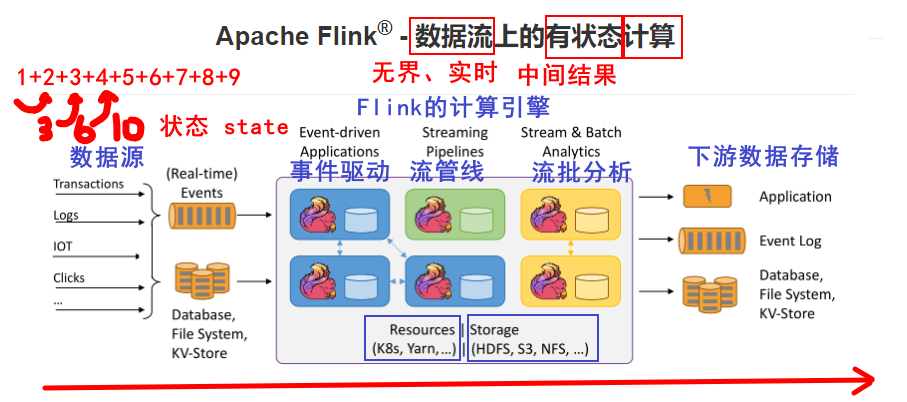
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
知识点04:【了解】处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
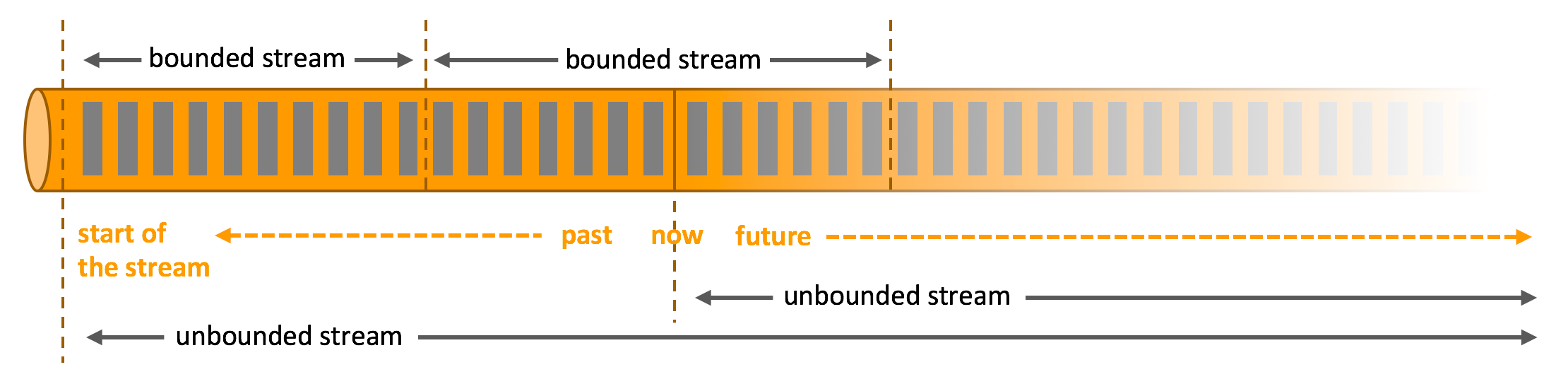
Apache Flink 擅长处理无界和有界数据集精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
知识点05:【理解】部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Kubernetes,但同时也可以作为 Standalone 独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
知识点06:【了解】运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
Flink 用户报告了其生产环境中一些令人印象深刻的扩展性数字
- 处理每天处理数万亿的事件
- 应用维护几TB大小的状态
- 应用在数千个内核上运行
知识点07:【了解】利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
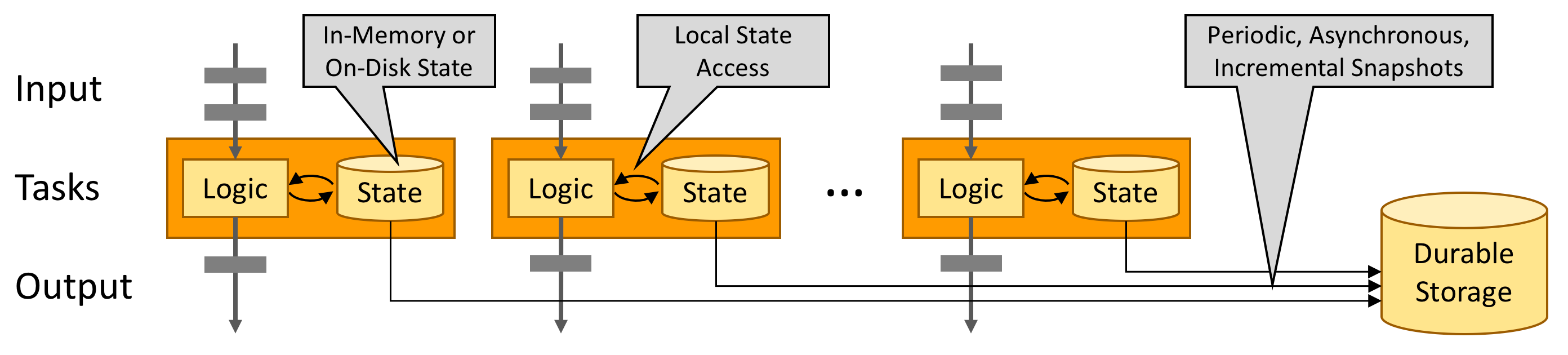
知识点08:【了解】Flink架构图
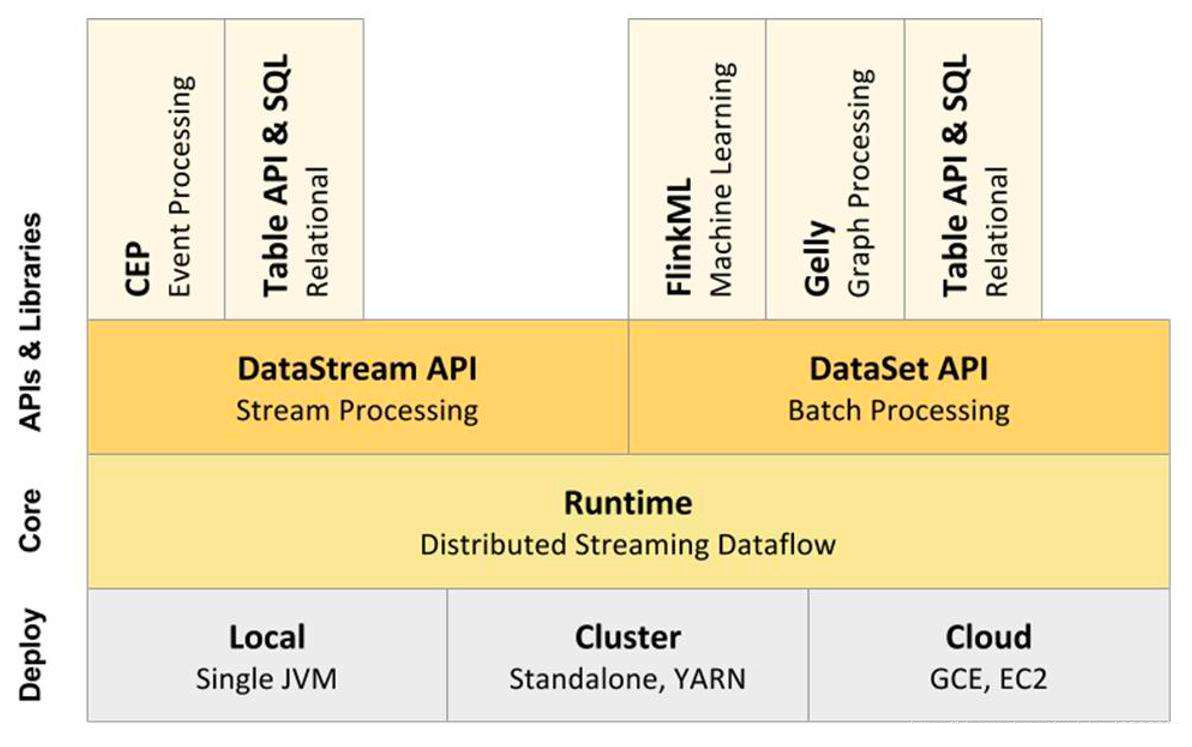
知识点09:【掌握】Flink的架构体系
目标:掌握Flink集群的架构以及每个角色的功能
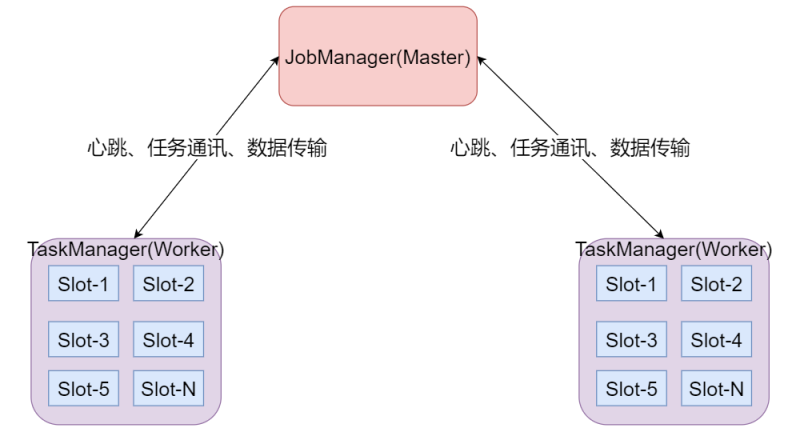
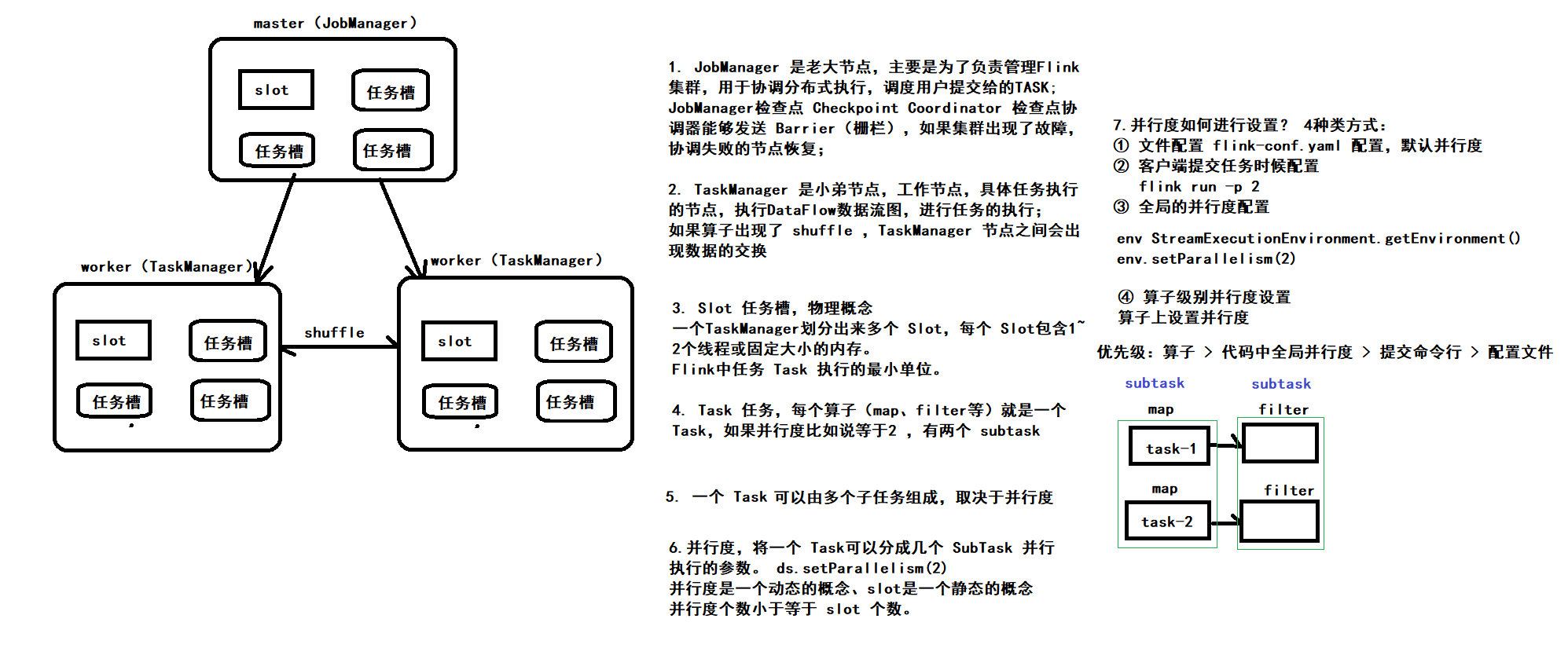
- JobManager处理器:
- 也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
- TaskManager处理器:
- 也称之为Worker,用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换,Flink运行时至少会存在一个worker处理器。
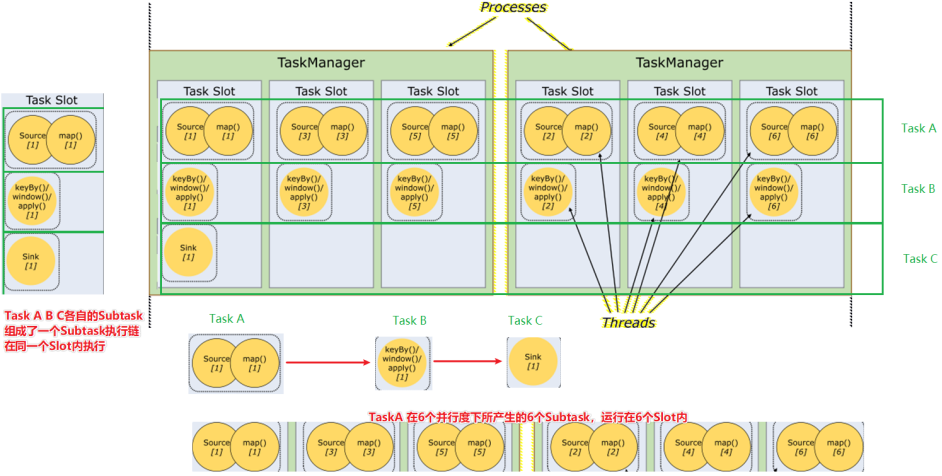
- Slot 任务执行槽位:
- 物理概念,一个TM(TaskManager)内会划分出多个Slot,1个Slot内最多可以运行1个Task(Subtask)或一组由Task(Subtask)组成的任务链。
- 多个Slot之间会共享平分当前TM的内存空间
- Slot是对一个TM的资源进行固定分配的工具,每个Slot在TM启动后,可以获得固定的资源
- 比如1个TM是一个JVM进程,如果有6个Slot,那么这6个Slot平分这一个JVM进程的资源
- 但是因为在同一个进程内,所以线程之间共享TCP连接、内存数据等,效率更高(Slot之间交流方便)
- Task:
- 任务,每一个Flink的Job会根据情况(并行度、算子类型)将一个整体的Job划分为多个Task
- Subtask:
- 子任务,一个Task可以由一个或者多个Subtask组成,一个Task有多少个Subtask取决于这个Task的并行度
- 也就是,每一个Subtask就是当前Task任务并行的一个线程
- 如,当前Task并行度为8,那么这个Task会有8个Subtask(8个线程并行执行这个Task)
- 并行度:
- 并行度就是一个Task可以分成多少个Subtask并行执行的一个参数
- 这个参数是动态的,可以在任务执行前进行分配,而非Slot分配,TM启动就固定了
- 一个Task可以获得的最大并行度取决于整个Flink环境的可用Slot数量,也就是如果有8个Slot,那么最大并行度也就是8,设置的再大也没有意义
- 如下图:
- 一个Job分为了3个Task来运行,分别是TaskA TaskB TaskC
- 其中TaskA设置为了6个并行度,也就是TaskA可以有6个Subtask,如图可见,TaskA的6个Subtask各自在一个Slot内执行
- 其中在Slot的时候说过,Slot可以运行由Task(或Subtask)组成的任务链,如图可见,最左边的Slot运行了TaskA TaskB TaskC 3个Task各自的1个Subtask组成的一个Subtask执行链
并行度是一个动态的概念,可以在多个地方设置并行度:
- 配置文件默认并行度:conf/flink-conf.yaml的parallelism.default
- 启动Flink任务,动态提交参数:比如:bin/flink run -p 3
- 在代码中设置全局并行度:env.setParallelism(3);
- 针对每个算子进行单独设置:sum(1).setParallelism(3)
优先级别是什么样子呢?
- 就近原则
- 算子 > 代码全局 > 提交任务 > 配置文件中
知识点10:【掌握】Flink数据流编程模型
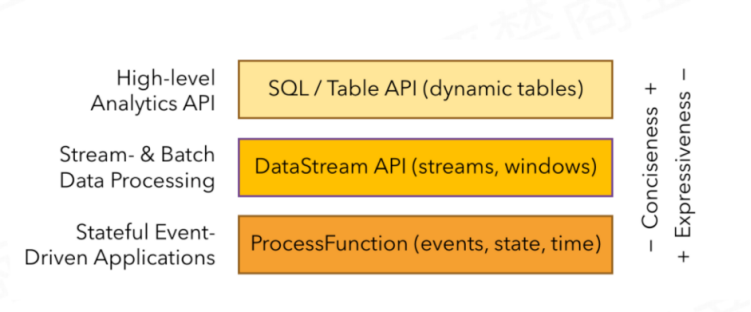
- 最顶层:SQL/Table API 提供了操作关系表、执行SQL语句分析的API库,供我们方便的开发SQL相关程序
- 中层:流和批处理API层,提供了一系列流和批处理的API和算子供我们对数据进行处理和分析
- 最底层:运行时层,提供了对Flink底层关键技术的操纵,如对Event、state、time、window等进行精细化控制的操作API
随着FlinkSQL的成熟,同时开发效率运维效率的考虑,企业越来越多的采用最顶层的FlinkSQL进行业务的开发,因此课程的讲解以FlinkSQL为主
知识点11:【扩展】Spark与Flink的区别
Flink 和 Spark 对比
通过前面的学习,我们了解到,Spark和Flink都支持批处理和流处理,接下来让我们对这两种流行的数据处理框架在各方面进行对比。首先,这两个数据处理框架有很多相同点:
- 基于内存的计算引擎
- 支持 Checkpoint 容错机制 和 Exactly-once 近义词语义,不多不少仅被有效处理一次
- 支持有效无环图的算子链,而且都支持 SQL 语义的操作
当然,它们的不同点也是相当明显,我们可以从4个不同的角度来看。
- 从流处理的角度来讲,Spark基于微批量处理,把流数据看成是一个个小的批处理数据块分别处理,所以延迟性只能做到秒级。而Flink基于每个事件处理,每当有新的数据输入都会立刻处理,是真正的流式计算,支持毫秒级计算。由于相同的原因,Spark只支持基于时间的窗口操作(处理时间或者事件时间),而Flink支持的窗口操作则非常灵活,不仅支持时间窗口,还支持基于数据本身的窗口,开发者可以自由定义想要的窗口操作。
- 从SQL 功能的角度来讲,Spark和Flink分别提供SparkSQL和Table APl提供SQL交互支持。两者相比较,Spark对SQL支持更好,相应的优化、扩展和性能更好,而Flink在SQL支持方面还有很大提升空间。
- 从迭代计算的角度来讲,Spark对机器学习的支持很好,因为可以在内存中缓存中间计算结果来加速机器学习算法的运行。但是大部分机器学习算法其实是一个有环的数据流,在Spark中,却是用无环图来表示。而Flink支持在运行时间中的有环数据流,从而可以更有效的对机器学习算法进行运算。
- 从相应的生态系统角度来讲,Spark 的社区无疑更加活跃。Spark可以说有着Apache旗下最多的开源贡献者,而且有很多不同的库来用在不同场景。而Flink由于较新,现阶段的开源社区不如Spark活跃,各种库的功能也不如Spark全面。但是Flink还在不断发展,各种功能也在逐渐完善。
如何选择Spark和Flink
对于以下场景,你可以选择 Spark:
- 数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等);
- 基于历史数据的交互式查询,要求响应较快;
- 基于实时数据流的数据处理,延迟性要求在在数百毫秒到数秒之间。
Spark完美满足这些场景的需求,而且它可以一站式解决这些问题,无需用别的数据处理平台。
由于Flink是为了提升流处理而创建的平台,所以它适用于各种需要非常低延迟(微秒到毫秒级)的实时数据处理场景,比如实时日志报表分析。而且Flink 用流处理去模拟批处理的思想,比Spark 用批处理去模拟流处理的思想扩展性更好。
总之,Apache Spark和Flink都是下一代大数据工具抢占业界关注的焦点。两者都提供与Hadoop和NoSQL数据库的本机连接,并且可以处理HDFS数据。两者都是几个大数据的好方法问题。但由于其底层架构,Flink比Spark更快。Apache Spark是Apache存储库中最活跃的组件。Spark拥有非常强大的社区支持,并且拥有大量的贡献者。Spark已经在生产中部署。但就流媒体功能而言,Flink远比Spark好(因为spark以微批量形式处理流)并且具有对流的本机支持。有人认为:Spark是大数据的3G,而Flink则被视为大数据的4G,该观点仅供参考即可。
Flink的安装部署
Flink支持多种安装模式。
- local(本地开发测试)——本地模式
- standalone——独立模式,Flink自带集群,开发测试环境使用(集群测试)
- standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用(略过)
- yarn——计算资源统一由Hadoop YARN管理(生产环境)
Standalone - 伪分布环境(开发测试)
知识点12:【理解】架构图
目标:理解Standalone集群架构
- Flink程序需要提交给JobClient
- JobClient将作业提交给JobManager
- JobManager负责协调资源分配和作业执行。 资源分配完成后,任务将提交给相应的TaskManager
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改。例如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(JobClient)
知识点13:【实现】Standalone集群部署
- 目标:实现Spark Standalone集群的部署
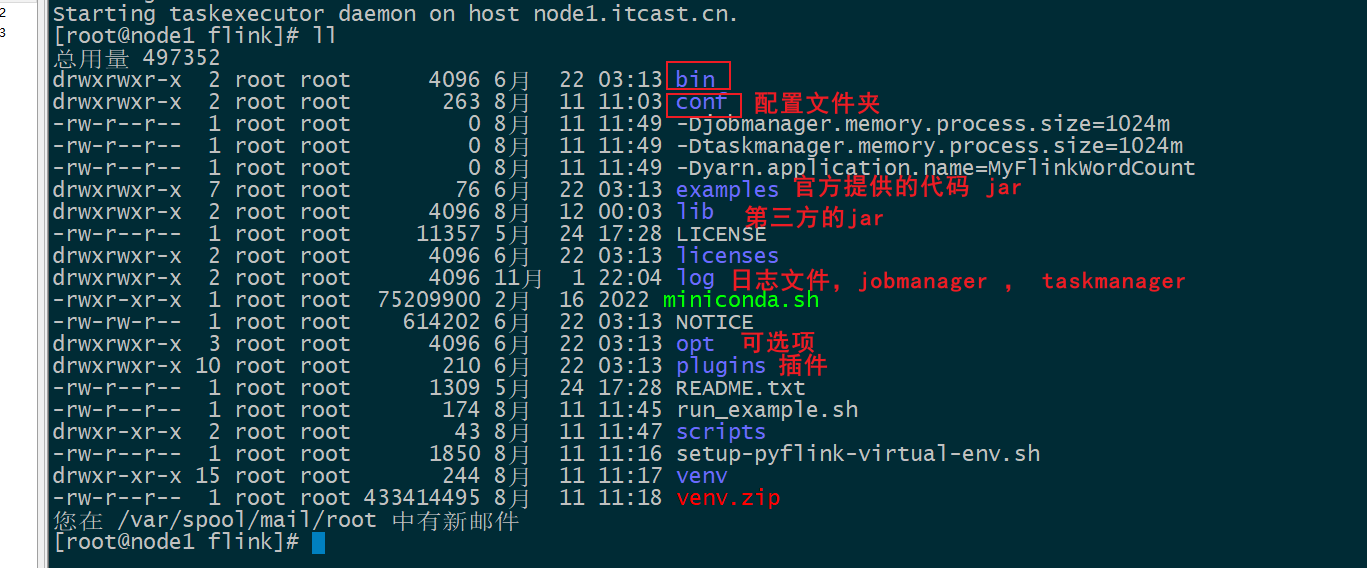
- 实施:
# 解压安装
cd /export/software/
tar -zxvf flink-1.15.2-bin-scala_2.12.tgz -C /export/server/
# 构建软连接
rm -rf flink
ln -s /export/server/flink-1.15.2 /export/server/flink- 目录结构
- 修改conf/flink-conf.yaml配置文件
#指定当前节点的slot数量
taskmanager.numberOfTaskSlots: 4
#设置checkpoint周期时间
execution.checkpointing.interval: 5000
#设置有且仅有一次模式 目前支持 EXACTLY_ONCE、AT_LEAST_ONCE
execution.checkpointing.mode: EXACTLY_ONCE
#设置checkpoint的存储方式
state.backend: filesystem
#设置checkpoint的存储位置
state.checkpoints.dir: hdfs://node:8020/checkpoints
#设置savepoint的存储位置
state.savepoints.dir: hdfs://node:8020/checkpoints
#设置checkpoint的超时时间 即一次checkpoint必须在该时间内完成 不然就丢弃
execution.checkpointing.timeout: 600000
#设置两次checkpoint之间的最小时间间隔
execution.checkpointing.min-pause: 500
#设置并发checkpoint的数目
execution.checkpointing.max-concurrent-checkpoints: 1
#开启checkpoints的外部持久化这里设置了清除job时保留checkpoint,默认值时保留一个 假如要保留3个
state.checkpoints.num-retained: 3
#默认情况下,checkpoint不是持久化的,只用于从故障中恢复作业。当程序被取消时,它们会被删除。但是你可以配置checkpoint被周期性持久化到外部,类似于savepoints。这些外部的checkpoints将它们的元数据输出到外#部持久化存储并且当作业失败时不会自动清除。这样,如果你的工作失败了,你就会有一个checkpoint来恢复。
#ExternalizedCheckpointCleanup模式配置当你取消作业时外部checkpoint会产生什么行为:
#RETAIN_ON_CANCELLATION: 当作业被取消时,保留外部的checkpoint。注意,在此情况下,您必须手动清理checkpoint状态。
#DELETE_ON_CANCELLATION: 当作业被取消时,删除外部化的checkpoint。只有当作业失败时,检查点状态才可用。
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
# 该配置用于客户端 client 连接 Flink, 将此设置为 JobManager 运行的主机名(该配置决定WEB的地址)
rest.address: node
# 客户端提供对外访问的地址和端口是rest.port和rest.address
# 如果没有配置rest.bind-port, 那么其他服务也使用rest.port端口,所以只要使用其中一个启动模式,其他模式在启动时就会报错端口无法启动
# 因此配置该项后, 其他 Job 启动后,就会在 rest.bind-address 和 rest.bind-port 随机选择并占用.
rest.bind-address: node
classloader.check-leaked-classloader: false- 配置环境变量
vim /etc/profile
FLINK_OPT_DIR=/export/server/flink-1.15.2/opt
export FLINK_OPT_DIR=/export/server/flink-1.15.2/opt
source /etc/profile- 启动Flink
bin/start-cluster.sh- 通过jps查看进程信息
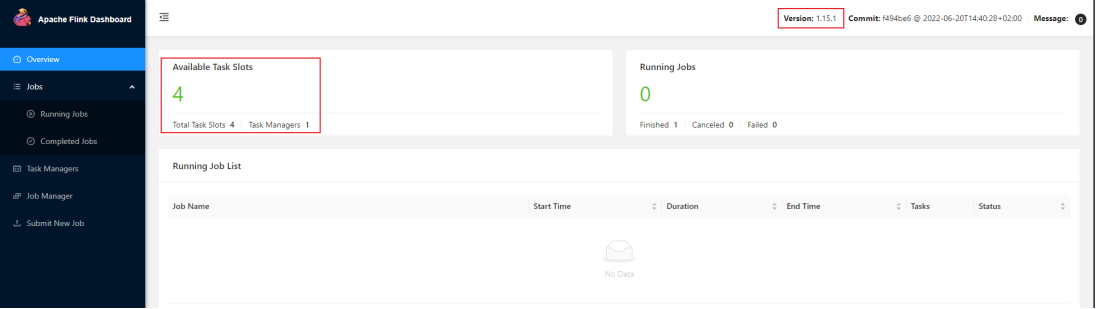
- 访问web界面
- Flink集成Hadoop包
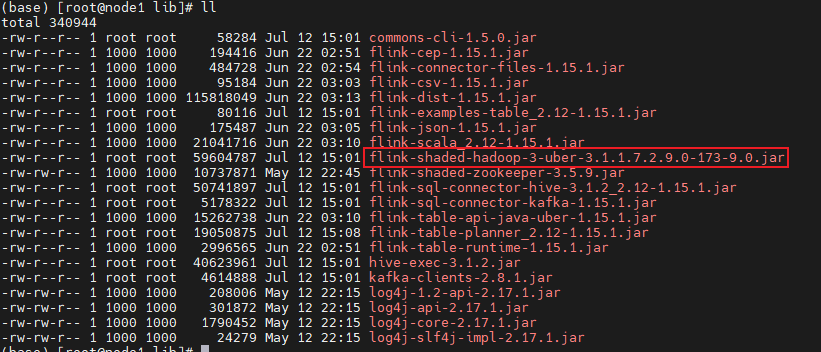
cd lib
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar - commons-cli-1.5.0.jar上传到lib目录下
- 
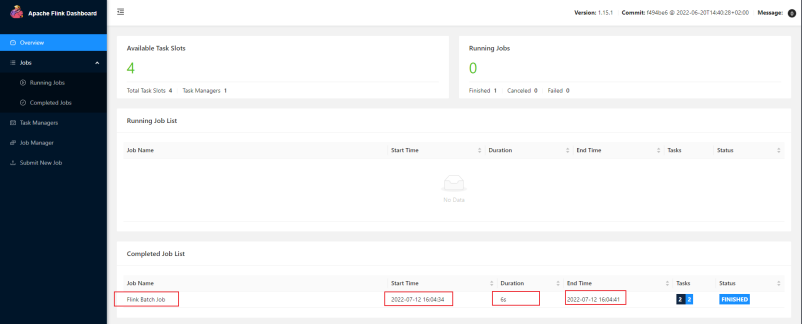
知识点15:【实现】案例演示
运行测试任务
观察WebUI
yarn~集群环境(生产推荐)
知识点16:【实现】环境准备
- 准备三台虚拟机
- 服务器: node1(ResourceManager + NodeManager)
- 服务器: node2(NodeManager)
- 服务器: node3(NodeManager)
- 至少hadoop2.2
- hdfs & yarn均启动
- 修改hadoop的配置参数:在node1服务器操作
- vim etc**/hadoop/**yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>5</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>- 分发yarn-site.xml到其它服务器节点
scp yarn-site.xml node2:$PWD
scp yarn-site.xml node3:$PWD- 重新启动HDFS、YARN集群
start-all.sh知识点17:【实现】准备 YARN 环境
知识点18:【理解】Yarn的三种部署方式
Session模式
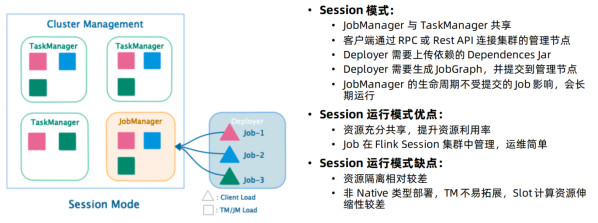
- 特点:需要事先申请资源,使用Flink中的yarn-session(yarn客户端),启动JobManager和TaskManger
- 优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
- 缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
- 应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
Per-Job模式
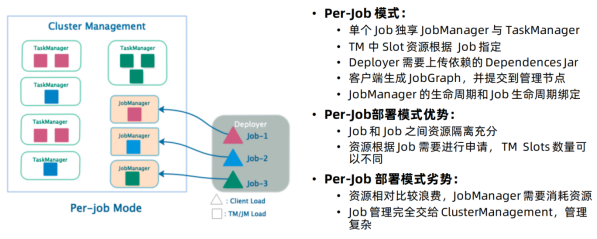
- 特点:每次递交作业都需要申请一次资源
- 优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
- 缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
- 应用场景:适合作业比较少的场景、大作业的场景
application模式
- 背景:flink-1.11 引入了一种新的部署模式,即 Application 模式。目前,flink-1.11 已经可以支持基于 Yarn 和 Kubernetes 的 Application 模式。
- 优势:
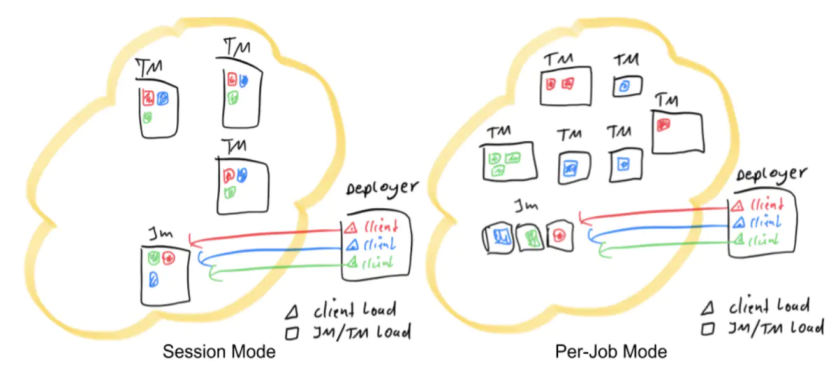
- Session模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。
- Per-Job模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行。
- 通过以上两种模式的特点描述,可以看出,main方法都是在客户端执行,社区考虑到在客户端执行 main() 方法来获取 flink 运行时所需的依赖项,并生成 JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,那么将会给服务器造成很大的压力。尤其在大量用户共享客户端时,问题更加突出。
- 因此,社区提出新的部署方式 Application 模式解决该问题。
- 原理
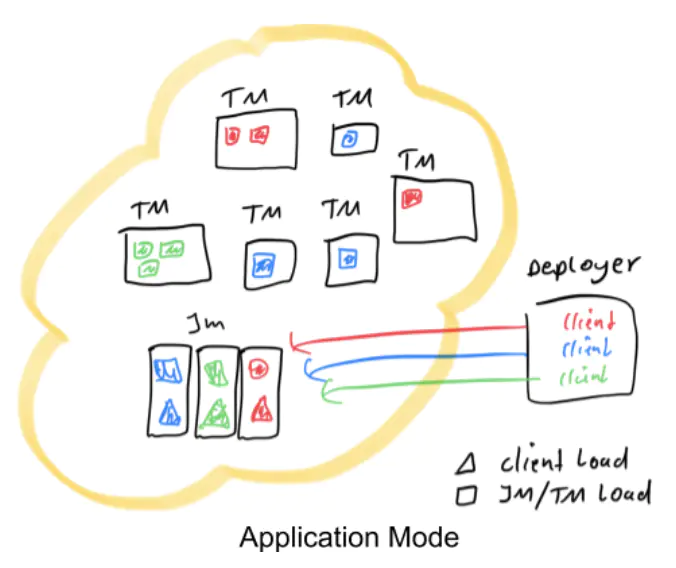
- Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在这种体系结构中,Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 main() 可以节省所需的 CPU 周期,还可以节省本地下载依赖项所需的带宽。
知识点19:【实现】Yarn的三种部署方式演示
Pre-Job 模式部署作业
执行以下命令,以 Pre-Job 模式部署 PyFlink 作业:
输入日志:
(base) [root@node1 flink-1.15.2]# bin/flink run -m yarn-cluster -pyarch venv.zip -pyexec venv.zip/venv/bin/python3.8 -py examples/python/datastream/word_count.py
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/export/server/flink-1.15.2/lib/flink-dist-1.15.2.jar) to field java.lang.String.value
WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2022-07-12 17:55:39,307 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/export/server/flink-1.15.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-07-12 17:55:39,367 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at node1/192.168.88.161:8032
2022-07-12 17:55:39,528 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-07-12 17:55:39,537 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Job Clusters are deprecated since Flink 1.15. Please use an Application Cluster/Application Mode instead.
2022-07-12 17:55:39,675 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2022-07-12 17:55:39,685 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2022-07-12 17:55:39,797 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2022-07-12 17:55:39,797 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2022-07-12 17:55:39,797 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=4}
2022-07-12 17:55:47,166 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Removing 'localhost' Key: 'jobmanager.bind-host' , default: null (fallback keys: []) setting from effective configuration; using '0.0.0.0' instead.
2022-07-12 17:55:47,167 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Removing 'localhost' Key: 'taskmanager.bind-host' , default: null (fallback keys: []) setting from effective configuration; using '0.0.0.0' instead.
2022-07-12 17:55:47,200 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1657619193120_0002
2022-07-12 17:55:47,223 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1657619193120_0002
2022-07-12 17:55:47,223 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2022-07-12 17:55:47,226 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2022-07-12 17:55:59,078 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2022-07-12 17:55:59,079 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node2:38614 of application 'application_1657619193120_0002'.
Job has been submitted with JobID d3517431b2791185e3fad73878d555af
Program execution finished
Job with JobID d3517431b2791185e3fad73878d555af has finished.
Job Runtime: 37703 ms
Executing word_count example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.上面信息已经显示运行完成,在 Web 界面可以看到作业状态:
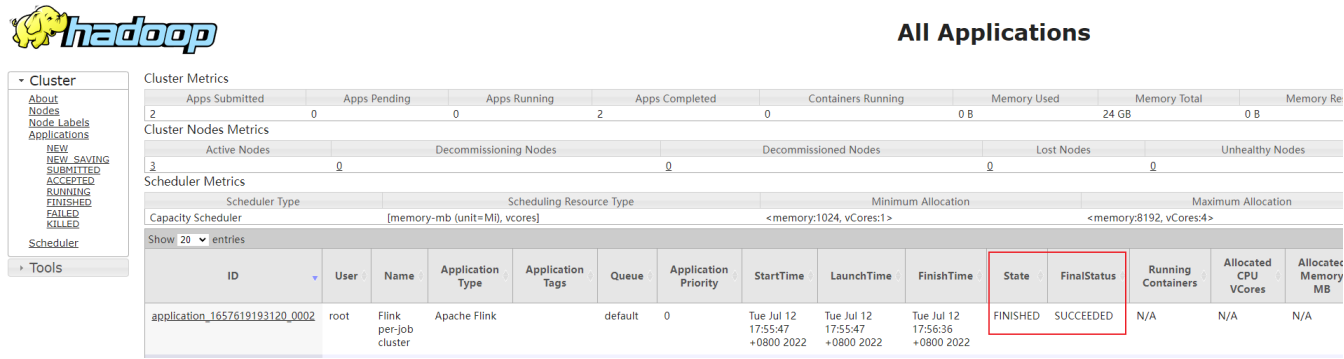
到这里,我们以 Pre-Job 的方式成功部署了 PyFlink 的作业!相比提交到本地 Standalone 集群,多了三个参数,我们简单说明如下:
| 参数 | 说明 |
|---|---|
| -m yarn-cluster | yarn-session.sh(开辟资源)+flink run(提交任务)以 Per-Job 模式部署到 yarn 集群 |
| -pyarch venv.zip | 将当前目录下的 venv.zip 上传到 yarn 集群 |
| -pyexec venv.zip/venv/bin/Python | 指定 venv.zip 中的 Python 解释器来执行 Python UDF,路径需要和 zip 包内部结构一致。 |
Session 模式部署作业
以 Session 模式部署作业也非常简单,操作一下:
(base) [root@node1 flink-1.15.2]# bin/yarn-session.sh
2022-07-12 18:09:27,123 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, localhost
2022-07-12 18:09:27,125 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.bind-host, localhost
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.bind-host, localhost
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.host, localhost
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 4
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: execution.checkpointing.interval, 5000
2022-07-12 18:09:27,126 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: execution.checkpointing.mode, EXACTLY_ONCE
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.backend, filesystem
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.checkpoints.dir, hdfs://node1:8020/checkpoints
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.savepoints.dir, hdfs://node1:8020/checkpoints
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: execution.checkpointing.timeout, 600000
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: execution.checkpointing.min-pause, 500
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: execution.checkpointing.max-concurrent-checkpoints, 1
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.checkpoints.num-retained, 3
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: execution.checkpointing.externalized-checkpoint-retention, RETAIN_ON_CANCELLATION
2022-07-12 18:09:27,127 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.backend, hashmap
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: state.checkpoint-storage, jobmanager
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: restart-strategy, fixed-delay
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: restart-strategy.fixed-delay.attempts, 3
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: restart-strategy.fixed-delay.delay, 10 s
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, node1
2022-07-12 18:09:27,128 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.bind-address, node1
2022-07-12 18:09:27,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: classloader.check-leaked-classloader, false
2022-07-12 18:09:27,295 WARN org.apache.hadoop.util.NativeCodeLoader [] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-07-12 18:09:27,424 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Hadoop user set to root (auth:SIMPLE)
2022-07-12 18:09:27,433 INFO org.apache.flink.runtime.security.modules.JaasModule [] - Jaas file will be created as /tmp/jaas-12574813724942792954.conf.
2022-07-12 18:09:27,453 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/export/server/flink-1.15.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-07-12 18:09:27,502 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at node1/192.168.88.161:8032
2022-07-12 18:09:27,596 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-07-12 18:09:27,604 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-07-12 18:09:27,690 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2022-07-12 18:09:27,690 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2022-07-12 18:09:27,727 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2022-07-12 18:09:27,728 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2022-07-12 18:09:27,728 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=4}
2022-07-12 18:09:31,077 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Removing 'localhost' Key: 'jobmanager.bind-host' , default: null (fallback keys: []) setting from effective configuration; using '0.0.0.0' instead.
2022-07-12 18:09:31,078 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Removing 'localhost' Key: 'taskmanager.bind-host' , default: null (fallback keys: []) setting from effective configuration; using '0.0.0.0' instead.
2022-07-12 18:09:31,119 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-07-12 18:09:31,128 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1657619193120_0003
2022-07-12 18:09:31,149 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1657619193120_0003
2022-07-12 18:09:31,149 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2022-07-12 18:09:31,154 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2022-07-12 18:09:35,692 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2022-07-12 18:09:35,692 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node3:39477 of application 'application_1657619193120_0003'.
JobManager Web Interface: http://node3:39477执行成功后不会返回,但会启动一个 JoBManager Web,地址如上[http://node3:39477],可复制到浏览器查看](http://localhost:62247,可复制到浏览器查看/):
我们可以修改 conf/flink-conf.yaml 中的配置参数。如果要更改某些内容,请参考官方文档。接下来我们提交作业,首先按组合键 Ctrl+Z 将 yarn-session.sh 进程切换到后台,并执行 bg 指令让其在后台继续执行, 然后执行以下命令,即可向 Session 模式的 Flink 集群提交 job :
(base) [root@node1 flink-1.15.2]# bin/flink run -t yarn-session -Dyarn.application.id=application_1657619193120_0003 -pyarch venv.zip -pyexec venv.zip/venv/bin/python3.8 -py examples/python/datastream/word_count.py
2022-07-12 18:16:21,703 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2022-07-12 18:16:21,703 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/export/server/flink-1.15.2/lib/flink-dist-1.15.2.jar) to field java.lang.String.value
WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2022-07-12 18:16:22,620 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/export/server/flink-1.15.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-07-12 18:16:22,680 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at node1/192.168.88.161:8032
2022-07-12 18:16:22,764 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-07-12 18:16:22,839 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node3:39477 of application 'application_1657619193120_0003'.
Job has been submitted with JobID f1da08c8b4fa6a0ae3948fa2df51dc94如果在打印 finished 之前查看之前的 web 页面,我们会发现 Session 集群会有一个正确运行的作业,如下:
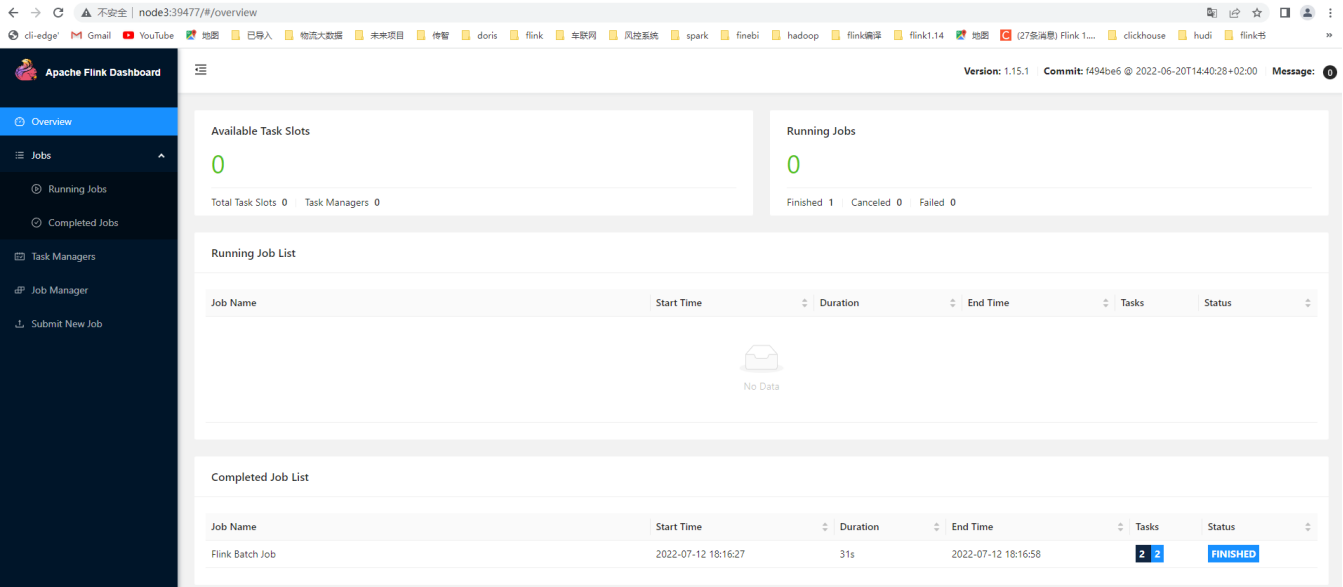
执行完毕后,别忘了关闭 yarn-session.sh(session 模式):
yarn application -kill application_1657619193120_0003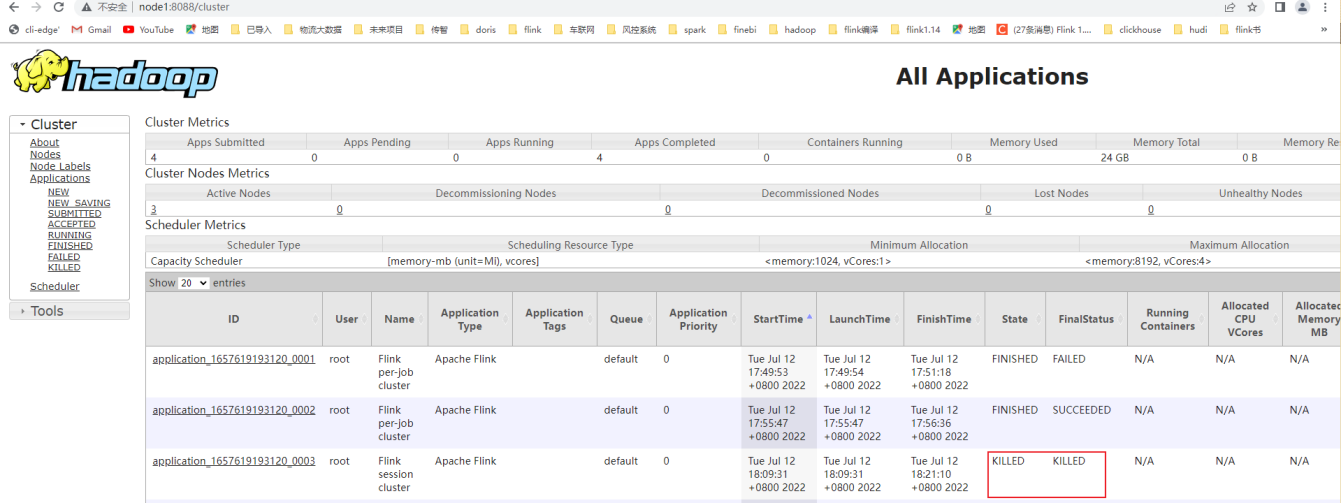
Application 模式部署作业
在该模式下需要将被执行的python文件和虚拟环境放到同一个目录下:
(base) [root@node1 flink-1.15.2]# mkdir scripts
(base) [root@node1 flink-1.15.2]# cp examples/python/datastream/word_count.py scripts/
(base) [root@node1 flink-1.15.2]# cp venv.zip scripts/
操作如下:
(base) [root@node1 flink-1.15.2]# ./bin/flink run-application -t yarn-application \
> -Djobmanager.memory.process.size=1024m \
> -Dtaskmanager.memory.process.size=1024m \
> -Dyarn.application.name="MyFlinkWordCount" \
> -Dyarn.ship-files=/export/server/flink-1.15.2/scripts \
> -pyarch scripts/venv.zip \
> -pyclientexec venv.zip/venv/bin/python3.8 \
> -pyexec venv.zip/venv/bin/python3.8 \
> -pyfs scripts/word_count.py \
> -pym word_count \
> --output hdfs://node1:8020/wordcount/output_52
2022-07-12 18:41:58,982 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2022-07-12 18:41:58,982 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2022-07-12 18:41:59,113 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/export/server/flink-1.15.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-07-12 18:41:59,184 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at node1/192.168.88.161:8032
2022-07-12 18:41:59,268 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-07-12 18:41:59,361 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2022-07-12 18:41:59,361 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2022-07-12 18:41:59,386 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, slotsPerTaskManager=4}
2022-07-12 18:42:07,545 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Removing 'localhost' Key: 'jobmanager.bind-host' , default: null (fallback keys: []) setting from effective configuration; using '0.0.0.0' instead.
2022-07-12 18:42:07,546 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Removing 'localhost' Key: 'taskmanager.bind-host' , default: null (fallback keys: []) setting from effective configuration; using '0.0.0.0' instead.
2022-07-12 18:42:07,584 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1657619193120_0008
2022-07-12 18:42:07,605 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1657619193120_0008
2022-07-12 18:42:07,606 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2022-07-12 18:42:07,607 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2022-07-12 18:42:13,395 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
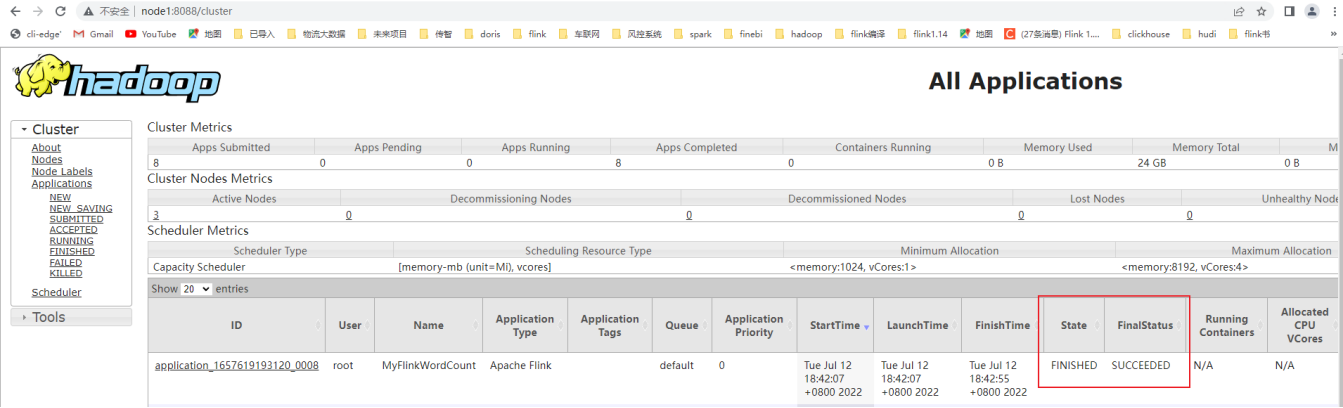
2022-07-12 18:42:13,396 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node3:35217 of application 'application_1657619193120_0008'.上面信息已经显示运行完成,在 Web 界面可以看到作业状态:
如果使用的是flink on yarn方式,想切换回standalone模式的话,需要删除文件:【/tmp/.yarn-properties-root】
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
如果是分离模式运行的YARN\JOB后,其运行完成会自动删除这个文件
但是会话模式的话,如果是kill掉任务,其不会执行自动删除这个文件的步骤,所以需要我们手动删除这个文件。
Flink的入门案例
知识点20:【实现】创建Flink项目
有了这些信息我们就可以进行Flink的作业开发了。
知识点21:【实现】批处理的入门案例
基于DataStreamAPI编程
package com.mmzy.batchDemo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.*;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 使用批的方式进行单词计数
* 读取文件里面的数据,对单词进行空格拆分,对每个单词进行计数,然后分组累加
* 使用flink1.12版本需要区分批处理和流处理的应用程序,flink1.12以后实现了流批一体
*/
public class WordCountBatch_DataStream {
public static void main(String[] args) throws Exception {
/**
* 实现步骤:
* 1)初始化flink批处理的运行环境
* 2)指定文件路径,获取数据
* 3)对获取到的数据进行空格拆分
* 4)对拆分后的单词计数,每个单词记一次数
* 5)对相同单词的数据进行分组操作
* 6)对分组后的数据进行累加操作
* 7)打印输出
* 8)启动作业,递交任务
*/
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> dataSet = env.readTextFile("/Users/znyoung/FlinkProject/FlinkProject/src/main/java/com/mmzy/batchDemo/wordcount.txt");
FlatMapOperator<String, String> words = dataSet.flatMap(new MyFlatMapFunction());
MapOperator<String, Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
});
UnsortedGrouping<Tuple2<String, Integer>> groupByRes = wordAndOne.groupBy(0);
AggregateOperator<Tuple2<String, Integer>> sumed = groupByRes.sum(1);
sumed.print();
}
private static class MyFlatMapFunction implements FlatMapFunction<String, String> {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] split = line.split(",");
for (String word : split) {
collector.collect(word);
}
}
}
}基于TableAPI编程
package com.mmzy.batchDemo;
import org.apache.flink.table.api.*;
import static org.apache.flink.table.api.Expressions.$;
public class WordCountBatch_Table {
public static void main(String[] args) {
//1:第一步创建流处理的执行环境
final EnvironmentSettings settings =
EnvironmentSettings.newInstance().inBatchMode().build();
final TableEnvironment tEnv = TableEnvironment.create(settings);
//2:第二步创建 datagen Connector 输入表 source_table,并指定字段 userid、timestamp、money 和 frequency:
tEnv.createTemporaryTable("source_table",
TableDescriptor.forConnector("filesystem").schema(
Schema.newBuilder()
.column("userid", DataTypes.STRING())
.column("timestamp", DataTypes.BIGINT())
.column("money", DataTypes.DOUBLE())
.column("category", DataTypes.STRING())
.build()
)
.option("path", "/Users/znyoung/FlinkProject/FlinkProject/src/main/java/com/mmzy/batchDemo/order.csv")
.option("format", "csv")
.build()
);
//3:第三步执行聚合查询计算每个 word 的出现次数 frequency:
Table resultTable = tEnv.from("source_table")
.groupBy($("userid"))
.select($("userid"), $("money").sum().as("money"));
//4:第四步创建 Print Connector 输出表 sink_table,并指定两个字段 userid 和 total_money:
tEnv.createTemporaryTable("sink_table",
TableDescriptor.forConnector("print").schema(
Schema.newBuilder()
.column("userid", DataTypes.STRING())
.column("total_money", DataTypes.DOUBLE())
.build())
.build());
//5:第五步查询结果 resultTable 输出到 Print 表 sink_table中:
resultTable.executeInsert("sink_table");
}
}基于SQL编程
package com.mmzy.batchDemo;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class WordCountBatch_SQL {
public static void main(String[] args) throws Exception {
// 1:第一步创建流处理的执行环境
final EnvironmentSettings settings =
EnvironmentSettings.newInstance().inBatchMode().build();
final TableEnvironment tableEnv = TableEnvironment.create(settings);
//2:第二步创建 datagen Connector 输入表 source_table,并指定字段 userid、timestamp、money 和 frequency:
String sourceDdl = "CREATE TABLE file_source (\n" +
" `userid` STRING,\n" +
" `timestamp` BIGINT,\n" +
" `money` DOUBLE,\n" +
" `category` STRING\n" +
" ) WITH (\n" +
" 'connector' = 'filesystem',\n" +
" 'path' = 'file:///Users/znyoung/FlinkProject/FlinkProject/src/main/java/com/mmzy/batchDemo/order.csv',\n" +
" 'format' = 'csv'\n" +
" )";
tableEnv.executeSql(sourceDdl);
//3:第三步创建 Print Connector 输出表 sink_table,并指定两个字段 userid 和 total_money:
String sinkDdl = "CREATE TABLE print_sink (\n" +
" `userid` STRING,\n" +
" `category` STRING,\n" +
" `totalmoney` DOUBLE\n" +
" ) WITH (\n" +
" 'connector' = 'print'\n" +
" )";
tableEnv.executeSql(sinkDdl);
//4:第四步查询结果 resultTable 输出到 Print 表 sink_table中:
tableEnv.executeSql("INSERT INTO print_sink\n" +
" SELECT `userid`, `category`, sum(`money`) AS `totalmoney`\n" +
" FROM file_source\n" +
" GROUP BY `userid`, `category`");
}
}知识点22:【实现】流处理的入门案例
准备工作
yum install -y nc- 将flink-examples-table_2.12-1.15.2.jar的jar包拷贝到指定目录,如:D:/workspace/pyflink_study/libs/
- 启动netcat监听的端口号
nc -lk 9999基于DataStreamAPI编程
package com.mmzy.flowDemo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountFlow_DataStram {
public static void main(String[] args) throws Exception {
/**
* 实现步骤:
* 1)初始化flink流处理的运行环境
* 2)指定socket路径,获取数据
* 3)对获取到的数据进行空格拆分
* 4)对拆分后的单词计数,每个单词记一次数
* 5)对相同单词的数据进行分组操作
* 6)对分组后的数据进行累加操作
* 7)打印输出
* 8)启动作业,递交任务
*/
//todo 1)初始化flink流处理的运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo 2)指定socket路径,获取数据
//nc -lk 9999
final DataStreamSource<String> lines = env.socketTextStream("node", 9999);
//todo 3)对获取到的数据进行空格拆分
//搜索类名:ctrl+n
//提示参数:ctrl+p
/**
* 第一个String:传入值类型
* 第二个String:返回值类型
*/
final SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
//ctrl+i
/**
* line:一行数据
* out:收集器,是用来返回数据的
* @param line
* @param out
* @throws Exception
*/
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
//将一行数据根据空格进行拆分
final String[] words = line.split(" ");
//遍历每个单词
for (String word : words) {
out.collect(word);
}
}
});
//todo 4)对拆分后的单词计数,每个单词记一次数
final SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map((MapFunction<String, Tuple2<String, Integer>>) value -> Tuple2.of(value, 1));
//todo 5)对相同单词的数据进行分组操作
final KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = wordAndOne.keyBy(0);
//todo 6)对分组后的数据进行累加操作
final SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = keyedStream.sum(1);
//todo 7)打印输出
sumed.print();
//todo 8)启动作业,递交任务
//在flink1.12之前批处理开发的时候,print相当于行动算子,会触发作业的递交,因此不需要额外的触发提交
//flink流开发作业必须要加execute
env.execute();
}
}基于TableAPI编程
package com.mmzy.flowDemo;
import org.apache.flink.connector.datagen.table.DataGenConnectorOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.*;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
public class WordCountFlow_Table {
public static void main(String[] args) {
//1:第一步创建流处理的执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//2:第二步创建 datagen Connector 输入表 source_table,并指定两个字段 word 和 frequency:
//通过 option 设置 Connector 的一些行为:
//fields.word.kind:指定 word 字段 kind 为 random,表示随机生成
//fields.word.length:指定 word 字段为一个字符长度
//fields.frequency.min:指定 frequency 字段最小值为 1
//fields.frequency.max:指定 frequency 字段最大值为 9
tEnv.createTemporaryTable("source_table",
TableDescriptor.forConnector("datagen").schema(
Schema.newBuilder()
.column("word", DataTypes.STRING())
.column("frequency", DataTypes.BIGINT()).build()
)
.option(DataGenConnectorOptions.ROWS_PER_SECOND, 1L)
.option("fields.word.kind", "random")
.option("fields.word.length", "1")
.option("fields.frequency.min", "1")
.option("fields.frequency.max", "9")
.build()
);
//3:第三步执行聚合查询计算每个 word 的出现次数 frequency:
Table resultTable = tEnv.from("source_table")
.groupBy($("word"))
.select($("word"), $("frequency").sum().as("frequency"));
//4:第四步创建 Print Connector 输出表 sink_table,并指定两个字段 word 和 frequency:
tEnv.createTemporaryTable("sink_table",
TableDescriptor.forConnector("print").schema(
Schema.newBuilder()
.column("word", DataTypes.STRING())
.column("frequency", DataTypes.BIGINT())
.build())
.build());
//5:第五步查询结果 resultTable 输出到 Print 表 sink_table中:
resultTable.executeInsert("sink_table");
}
}基于SQL编程
package com.mmzy.flowDemo;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class WordCountFlow_SQL {
public static void main(String[] args) throws Exception {
// 1:第一步创建流处理的执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//2:第二步创建 datagen Connector 输入表 source_table,并指定字段 word 和 frequency:
String sourceDdl = "CREATE TABLE file_source (\n" +
" `word` STRING,\n" +
" `frequency` BIGINT\n" +
" ) WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'fields.word.kind' = 'random',\n" +
" 'fields.word.length' = '1',\n" +
" 'fields.frequency.min' = '1',\n" +
" 'fields.frequency.max' = '9'\n" +
" )";
tEnv.executeSql(sourceDdl);
//3:第三步创建 Print Connector 输出表 sink_table,并指定两个字段 word 和 frequency:
String sinkDdl = "CREATE TABLE print_sink (\n" +
" `word` STRING,\n" +
" `frequency` BIGINT\n" +
" ) WITH (\n" +
" 'connector' = 'print'\n" +
" )";
tEnv.executeSql(sinkDdl);
//4:第四步查询结果 resultTable 输出到 Print 表 sink_table中:
tEnv.executeSql("INSERT INTO print_sink\n" +
" SELECT `word`, sum(`frequency`) AS `frequency`\n" +
" FROM file_source\n" +
" GROUP BY `word`");
}
}基于Lambda
package com.mmzy.flowDemo;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class WordCountFlow_Lambda {
public static void main(String[] args) throws Exception {
// 1、创建流式处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、并行度设置为1,运行模式为批处理
env.setParallelism(1);
// 3、将source添加到环境中,生成datastream对象
final DataStreamSource<String> dataSource = env.socketTextStream("node", 9999);
// 4、transform
dataSource.flatMap((String input, Collector<String[]> collector) -> {
collector.collect(input.split(","));
})
.returns(Types.OBJECT_ARRAY(Types.STRING))
.flatMap((String[] words, Collector<Tuple2<String, Integer>> collector) -> {
Arrays.stream(words).map(word -> new Tuple2<>(word, 1)).forEach(collector::collect);
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0)
.sum(1)
.print();
env.execute();
}
}知识点23:【掌握】SqlClient工具的使用
SQL 客户端捆绑在常规 Flink 发行版中,因此可以直接运行。它仅需要一个正在运行的 Flink 集群就可以在其中执行表程序。有关设置 Flink 群集的更多信息,请参见集群和部署部分。如果仅想试用 SQL 客户端,也可以使用以下命令启动本地集群:
./bin/start-cluster.sh
启动 SQL 客户端命令行界面
SQL Client 脚本也位于 Flink 的 bin 目录中。用户可以通过启动嵌入式 standalone 进程或通过连接到远程 SQL 客户端网关来启动 SQL 客户端命令行界面。目前仅支持 embedded,模式默认值embedded。可以通过以下方式启动 CLI:
./bin/start-cluster.sh或者显式使用 embedded 模式:
./bin/sql-client.sh embedded启动成功 会进入 flink sql> 命令行界面 (输入 quit; 退出)
执行 SQL 查询
命令行界面启动后,你可以使用 **help**命令列出所有可用的 SQL 语句。输入第一条 SQL 查询语句并按 Enter 键执行,可以验证你的设置及集群连接是否正确:
SELECT 'Hello World';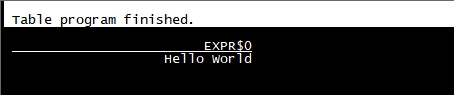
默认情况下输出默认采用的是表格模式,在上面的演示中该查询不需要 table source,因为只产生一行结果。CLI 将从集群中检索结果并将其可视化。按 Q 键退出结果视图。
CLI 为维护和可视化结果提供三种模式:
- 表格模式(table mode)在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用:
SET sql-client.execution.result-mode=table;- 变更日志模式(changelog mode)不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。
SET sql-client.execution.result-mode=changelog;- Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET sql-client.execution.result-mode=tableau;可以用如下查询来查看三种结果模式的运行情况:
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
- 变更日志模式 下,看到的结果应该类似于:
SET sql-client.execution.result-mode=changelog;
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
- 表格模式 下,可视化结果表将不断更新,直到表程序以如下内容结束:
SET sql-client.execution.result-mode=table;
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
- Tableau模式 下,如果这个查询以流的方式执行,那么将显示以下内容:
SET sql-client.execution.result-mode=tableau;
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
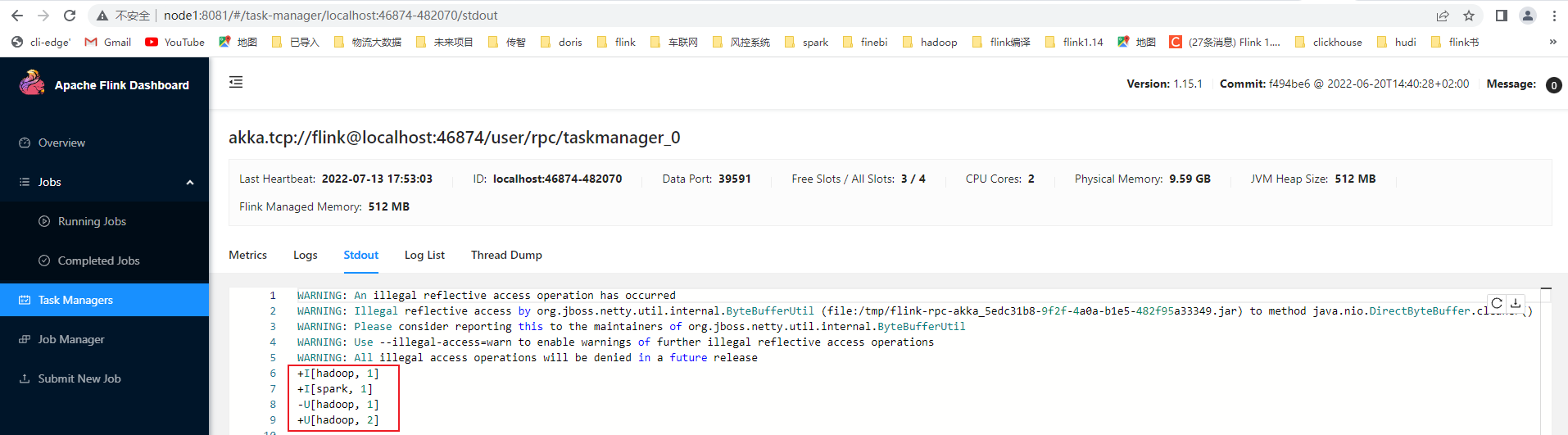
将流处理案例的sql在sqlclient工具中执行
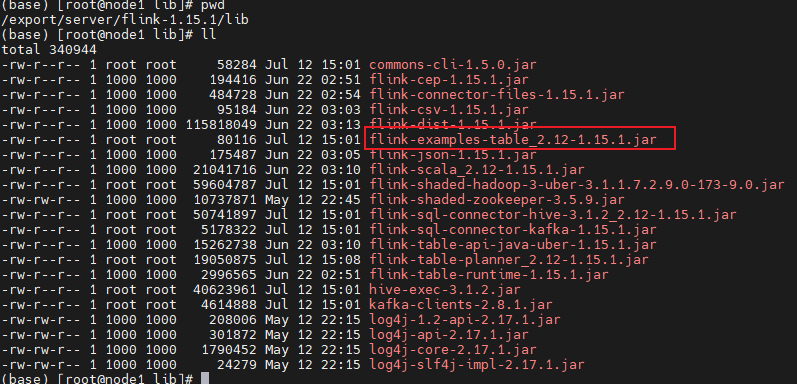
- 将flink-examples-table_2.12-1.15.2.jar上传到$FLINK_HOME/lib
- 重启flink集群,并进入sql-client命令行
(base) [root@node1 flink-1.15.2]# bin/sql-client.sh- 执行创建源表操作
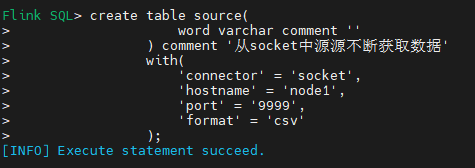
create table source(
word varchar comment ''
) comment '从socket中源源不断获取数据'
with(
'connector' = 'socket',
'hostname' = 'node1',
'port' = '9999',
'format' = 'csv'
);
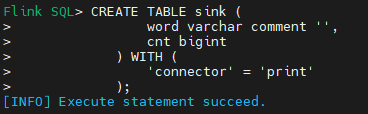
- 执行创建目标表操作
CREATE TABLE sink (
word varchar comment '',
cnt bigint
) WITH (
'connector' = 'print'
)
- 开启netcat,监听9999端口号
nc -lk 9999
- 在sql-client中递交一个流处理作业,将源表数据接受到的单词累加后实时写入到目标表
INSERT INTO sink
SELECT word, count(1) AS cnt
FROM source
GROUP BY word;Flink SQL> INSERT INTO sink
> SELECT word, count(1) AS cnt
> FROM source
> GROUP BY word;
[INFO] Submitting SQL update statement to the cluster...
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/export/server/flink-1.15.2/lib/flink-dist-1.15.2.jar) to field java.lang.String.value
WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 37643c78f8000a6d22a00e67379f2ad6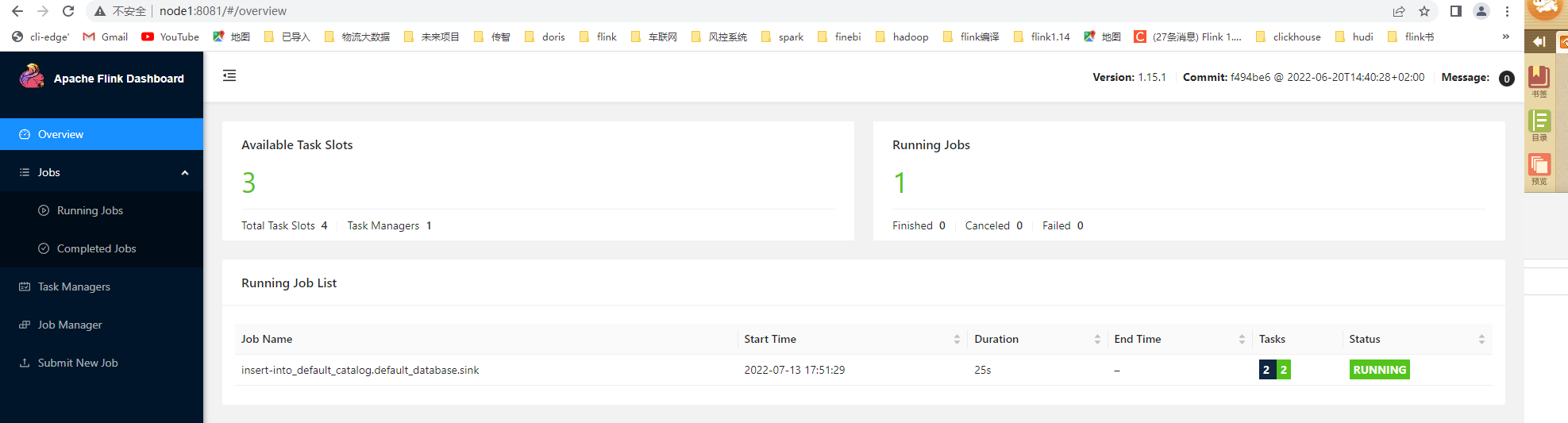
- 在nc输入单词
(base) [root@node1 flink-1.15.2]# nc -lk 9999
hadoop
spark
hadoop